 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunity Recovery in the Geometric Block Model
Jun 22, 2022

To capture inherent geometric features of many community detection problems, we propose to use a new random graph model of communities that we call a \emph{Geometric Block Model}. The geometric block model builds on the \emph{random geometric graphs} (Gilbert, 1961), one of the basic models of random graphs for spatial networks, in the same way that the well-studied stochastic block model builds on the Erd\H{o}s-R\'{en}yi random graphs. It is also a natural extension of random community models inspired by the recent theoretical and practical advancements in community detection. To analyze the geometric block model, we first provide new connectivity results for \emph{random annulus graphs} which are generalizations of random geometric graphs. The connectivity properties of geometric graphs have been studied since their introduction, and analyzing them has been difficult due to correlated edge formation. We then use the connectivity results of random annulus graphs to provide necessary and sufficient conditions for efficient recovery of communities for the geometric block model. We show that a simple triangle-counting algorithm to detect communities in the geometric block model is near-optimal. For this we consider two regimes of graph density. In the regime where the average degree of the graph grows logarithmically with number of vertices, we show that our algorithm performs extremely well, both theoretically and practically. In contrast, the triangle-counting algorithm is far from being optimum for the stochastic block model in the logarithmic degree regime. We also look at the regime where the average degree of the graph grows linearly with the number of vertices $n$, and hence to store the graph one needs $\Theta(n^2)$ memory. We show that our algorithm needs to store only $O(n \log n)$ edges in this regime to recover the latent communities.
Decentralized Competing Bandits in Non-Stationary Matching Markets
May 31, 2022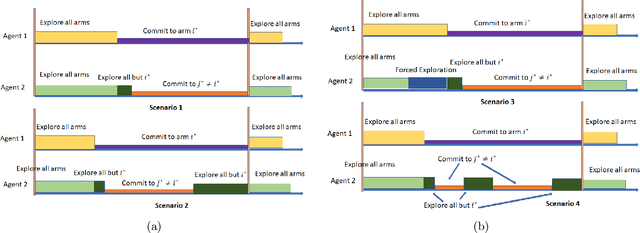
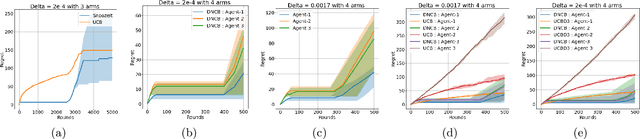
Understanding complex dynamics of two-sided online matching markets, where the demand-side agents compete to match with the supply-side (arms), has recently received substantial interest. To that end, in this paper, we introduce the framework of decentralized two-sided matching market under non stationary (dynamic) environments. We adhere to the serial dictatorship setting, where the demand-side agents have unknown and different preferences over the supply-side (arms), but the arms have fixed and known preference over the agents. We propose and analyze a decentralized and asynchronous learning algorithm, namely Decentralized Non-stationary Competing Bandits (\texttt{DNCB}), where the agents play (restrictive) successive elimination type learning algorithms to learn their preference over the arms. The complexity in understanding such a system stems from the fact that the competing bandits choose their actions in an asynchronous fashion, and the lower ranked agents only get to learn from a set of arms, not \emph{dominated} by the higher ranked agents, which leads to \emph{forced exploration}. With carefully defined complexity parameters, we characterize this \emph{forced exploration} and obtain sub-linear (logarithmic) regret of \texttt{DNCB}. Furthermore, we validate our theoretical findings via experiments.
On Learning Mixture of Linear Regressions in the Non-Realizable Setting
May 26, 2022
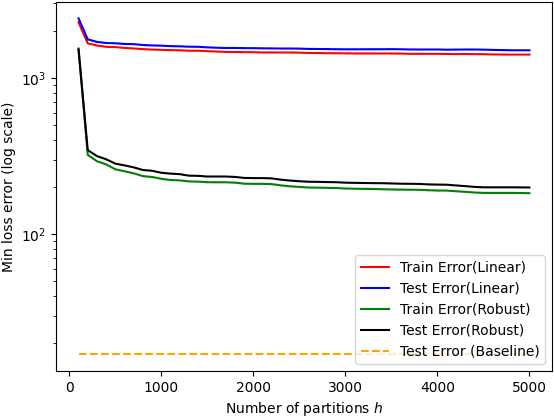


While mixture of linear regressions (MLR) is a well-studied topic, prior works usually do not analyze such models for prediction error. In fact, {\em prediction} and {\em loss} are not well-defined in the context of mixtures. In this paper, first we show that MLR can be used for prediction where instead of predicting a label, the model predicts a list of values (also known as {\em list-decoding}). The list size is equal to the number of components in the mixture, and the loss function is defined to be minimum among the losses resulted by all the component models. We show that with this definition, a solution of the empirical risk minimization (ERM) achieves small probability of prediction error. This begs for an algorithm to minimize the empirical risk for MLR, which is known to be computationally hard. Prior algorithmic works in MLR focus on the {\em realizable} setting, i.e., recovery of parameters when data is probabilistically generated by a mixed linear (noisy) model. In this paper we show that a version of the popular alternating minimization (AM) algorithm finds the best fit lines in a dataset even when a realizable model is not assumed, under some regularity conditions on the dataset and the initial points, and thereby provides a solution for the ERM. We further provide an algorithm that runs in polynomial time in the number of datapoints, and recovers a good approximation of the best fit lines. The two algorithms are experimentally compared.
On Learning Mixture Models with Sparse Parameters
Feb 24, 2022Mixture models are widely used to fit complex and multimodal datasets. In this paper we study mixtures with high dimensional sparse latent parameter vectors and consider the problem of support recovery of those vectors. While parameter learning in mixture models is well-studied, the sparsity constraint remains relatively unexplored. Sparsity of parameter vectors is a natural constraint in variety of settings, and support recovery is a major step towards parameter estimation. We provide efficient algorithms for support recovery that have a logarithmic sample complexity dependence on the dimensionality of the latent space. Our algorithms are quite general, namely they are applicable to 1) mixtures of many different canonical distributions including Uniform, Poisson, Laplace, Gaussians, etc. 2) Mixtures of linear regressions and linear classifiers with Gaussian covariates under different assumptions on the unknown parameters. In most of these settings, our results are the first guarantees on the problem while in the rest, our results provide improvements on existing works.
Random Subgraph Detection Using Queries
Oct 08, 2021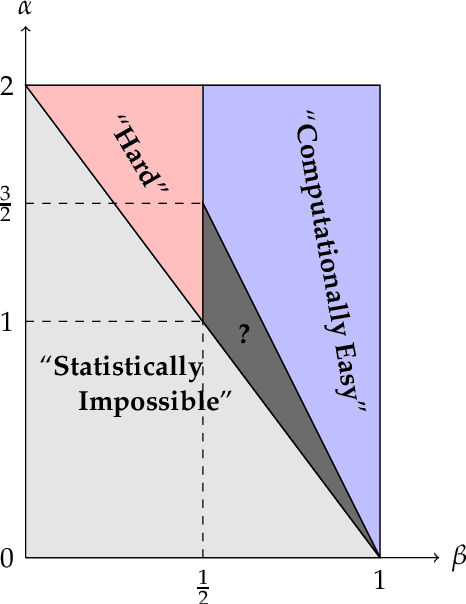
The planted densest subgraph detection problem refers to the task of testing whether in a given (random) graph there is a subgraph that is unusually dense. Specifically, we observe an undirected and unweighted graph on $n$ nodes. Under the null hypothesis, the graph is a realization of an Erd\H{o}s-R\'{e}nyi graph with edge probability (or, density) $q$. Under the alternative, there is a subgraph on $k$ vertices with edge probability $p>q$. The statistical as well as the computational barriers of this problem are well-understood for a wide range of the edge parameters $p$ and $q$. In this paper, we consider a natural variant of the above problem, where one can only observe a small part of the graph using adaptive edge queries. For this model, we determine the number of queries necessary and sufficient for detecting the presence of the planted subgraph. Specifically, we show that any (possibly randomized) algorithm must make $\mathsf{Q} = \Omega(\frac{n^2}{k^2\chi^4(p||q)}\log^2n)$ adaptive queries (on expectation) to the adjacency matrix of the graph to detect the planted subgraph with probability more than $1/2$, where $\chi^2(p||q)$ is the Chi-Square distance. On the other hand, we devise a quasi-polynomial-time algorithm that detects the planted subgraph with high probability by making $\mathsf{Q} = O(\frac{n^2}{k^2\chi^4(p||q)}\log^2n)$ non-adaptive queries. We then propose a polynomial-time algorithm which is able to detect the planted subgraph using $\mathsf{Q} = O(\frac{n^3}{k^3\chi^2(p||q)}\log^3 n)$ queries. We conjecture that in the leftover regime, where $\frac{n^2}{k^2}\ll\mathsf{Q}\ll \frac{n^3}{k^3}$, no polynomial-time algorithms exist. Our results resolve two questions posed in \cite{racz2020finding}, where the special case of adaptive detection and recovery of a planted clique was considered.
Lower Bounds on the Total Variation Distance Between Mixtures of Two Gaussians
Sep 02, 2021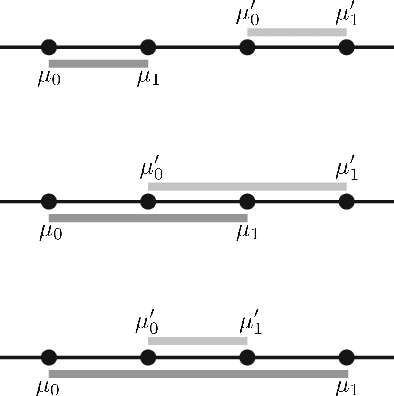
Mixtures of high dimensional Gaussian distributions have been studied extensively in statistics and learning theory. While the total variation distance appears naturally in the sample complexity of distribution learning, it is analytically difficult to obtain tight lower bounds for mixtures. Exploiting a connection between total variation distance and the characteristic function of the mixture, we provide fairly tight functional approximations. This enables us to derive new lower bounds on the total variation distance between pairs of two-component Gaussian mixtures that have a shared covariance matrix.
Support Recovery in Universal One-bit Compressed Sensing
Aug 23, 2021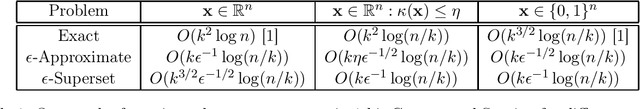
One-bit compressed sensing (1bCS) is an extreme-quantized signal acquisition method that has been widely studied in the past decade. In 1bCS, linear samples of a high dimensional signal are quantized to only one bit per sample (sign of the measurement). Assuming the original signal vector to be sparse, existing results either aim to find the support of the vector, or approximate the signal within an $\epsilon$-ball. The focus of this paper is support recovery, which often also computationally facilitates approximate signal recovery. A universal measurement matrix for 1bCS refers to one set of measurements that work for all sparse signals. With universality, it is known that $\tilde{\Theta}(k^2)$ 1bCS measurements are necessary and sufficient for support recovery (where $k$ denotes the sparsity). In this work, we show that it is possible to universally recover the support with a small number of false positives with $\tilde{O}(k^{3/2})$ measurements. If the dynamic range of the signal vector is known, then with a different technique, this result can be improved to only $\tilde{O}(k)$ measurements. Further results on support recovery are also provided.
Support Recovery of Sparse Signals from a Mixture of Linear Measurements
Jun 10, 2021Recovery of support of a sparse vector from simple measurements is a widely studied problem, considered under the frameworks of compressed sensing, 1-bit compressed sensing, and more general single index models. We consider generalizations of this problem: mixtures of linear regressions, and mixtures of linear classifiers, where the goal is to recover supports of multiple sparse vectors using only a small number of possibly noisy linear, and 1-bit measurements respectively. The key challenge is that the measurements from different vectors are randomly mixed. Both of these problems were also extensively studied recently. In mixtures of linear classifiers, the observations correspond to the side of queried hyperplane a random unknown vector lies in, whereas in mixtures of linear regressions we observe the projection of a random unknown vector on the queried hyperplane. The primary step in recovering the unknown vectors from the mixture is to first identify the support of all the individual component vectors. In this work, we study the number of measurements sufficient for recovering the supports of all the component vectors in a mixture in both these models. We provide algorithms that use a number of measurements polynomial in $k, \log n$ and quasi-polynomial in $\ell$, to recover the support of all the $\ell$ unknown vectors in the mixture with high probability when each individual component is a $k$-sparse $n$-dimensional vector.
Fuzzy Clustering with Similarity Queries
Jun 04, 2021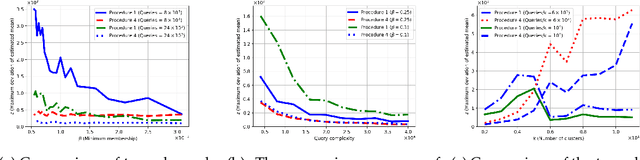
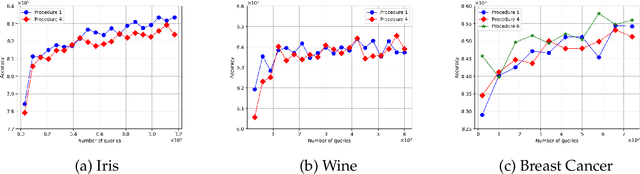
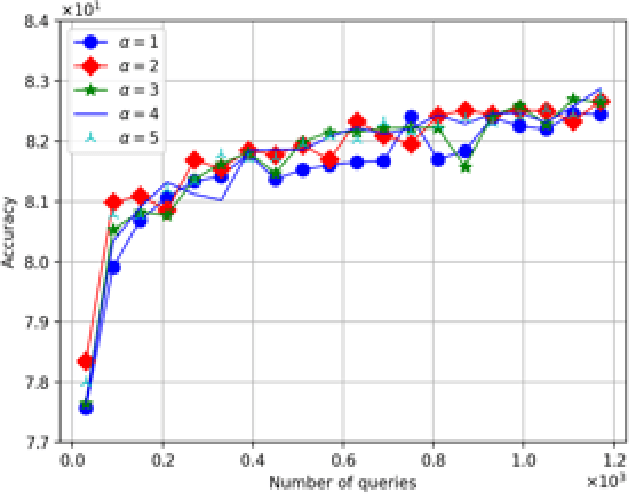
The fuzzy or soft $k$-means objective is a popular generalization of the well-known $k$-means problem, extending the clustering capability of the $k$-means to datasets that are uncertain, vague, and otherwise hard to cluster. In this paper, we propose a semi-supervised active clustering framework, where the learner is allowed to interact with an oracle (domain expert), asking for the similarity between a certain set of chosen items. We study the query and computational complexities of clustering in this framework. We prove that having a few of such similarity queries enables one to get a polynomial-time approximation algorithm to an otherwise conjecturally NP-hard problem. In particular, we provide probabilistic algorithms for fuzzy clustering in this setting that asks $O(\mathsf{poly}(k)\log n)$ similarity queries and run with polynomial-time-complexity, where $n$ is the number of items. The fuzzy $k$-means objective is nonconvex, with $k$-means as a special case, and is equivalent to some other generic nonconvex problem such as non-negative matrix factorization. The ubiquitous Lloyd-type algorithms (or, expectation-maximization algorithm) can get stuck at a local minima. Our results show that by making few similarity queries, the problem becomes easier to solve. Finally, we test our algorithms over real-world datasets, showing their effectiveness in real-world applications.
Escaping Saddle Points in Distributed Newton's Method with Communication efficiency and Byzantine Resilience
Mar 17, 2021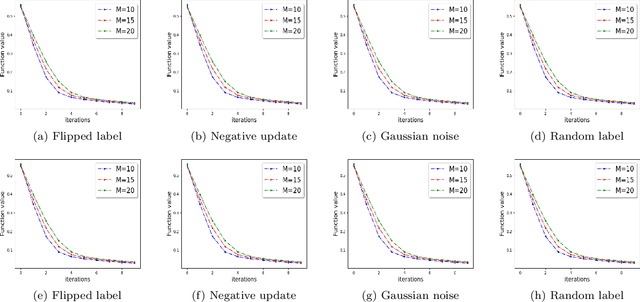

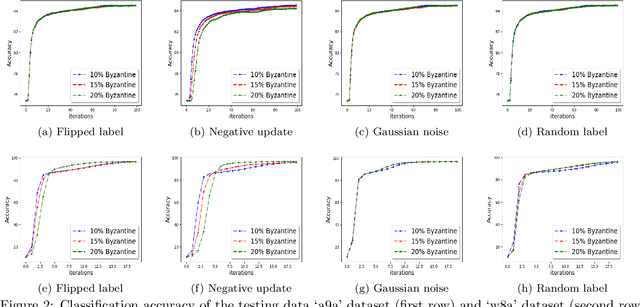
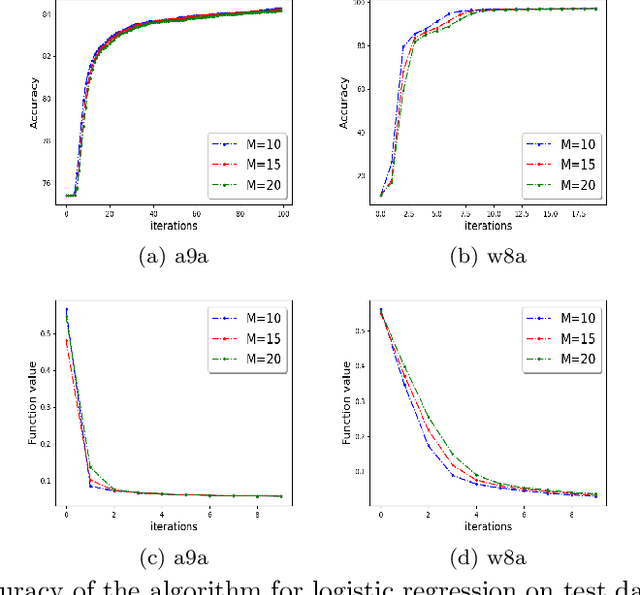
We study the problem of optimizing a non-convex loss function (with saddle points) in a distributed framework in the presence of Byzantine machines. We consider a standard distributed setting with one central machine (parameter server) communicating with many worker machines. Our proposed algorithm is a variant of the celebrated cubic-regularized Newton method of Nesterov and Polyak \cite{nest}, which avoids saddle points efficiently and converges to local minima. Furthermore, our algorithm resists the presence of Byzantine machines, which may create \emph{fake local minima} near the saddle points of the loss function, also known as saddle-point attack. We robustify the cubic-regularized Newton algorithm such that it avoids the saddle points and the fake local minimas efficiently. Furthermore, being a second order algorithm, the iteration complexity is much lower than its first order counterparts, and thus our algorithm communicates little with the parameter server. We obtain theoretical guarantees for our proposed scheme under several settings including approximate (sub-sampled) gradients and Hessians. Moreover, we validate our theoretical findings with experiments using standard datasets and several types of Byzantine attacks.