 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Efficient and Byzantine-Robust Distributed Learning
Paper and Code
Nov 21, 2019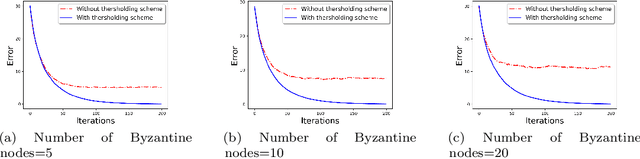
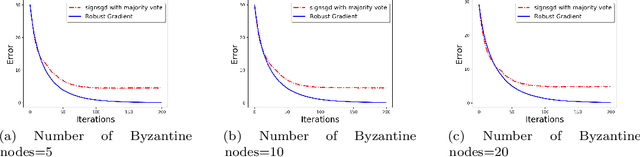
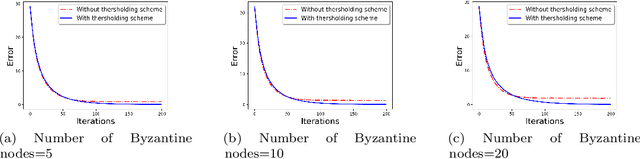
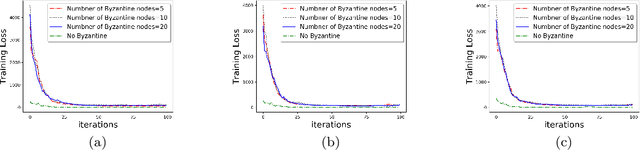
We develop a communication-efficient distributed learning algorithm that is robust against Byzantine worker machines. We propose and analyze a distributed gradient-descent algorithm that performs a simple thresholding based on gradient norms to mitigate Byzantine failures. We show the (statistical) error-rate of our algorithm matches that of [YCKB18], which uses more complicated schemes (like coordinate-wise median or trimmed mean) and thus optimal. Furthermore, for communication efficiency, we consider a generic class of {\delta}-approximate compressors from [KRSJ19] that encompasses sign-based compressors and top-k sparsification. Our algorithm uses compressed gradients and gradient norms for aggregation and Byzantine removal respectively. We establish the statistical error rate of the algorithm for arbitrary (convex or non-convex) smooth loss function. We show that, in the regime when the compression factor {\delta} is constant and the dimension of the parameter space is fixed, the rate of convergence is not affected by the compression operation, and hence we effectively get the compression for free. Moreover, we extend the compressed gradient descent algorithm with error feedback proposed in [KRSJ19] for the distributed setting. We have experimentally validated our results and shown good performance in convergence for convex (least-square regression) and non-convex (neural network training) problems.