 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmart Multi-Modal Search: Contextual Sparse and Dense Embedding Integration in Adobe Express
Aug 26, 2024



As user content and queries become increasingly multi-modal, the need for effective multi-modal search systems has grown. Traditional search systems often rely on textual and metadata annotations for indexed images, while multi-modal embeddings like CLIP enable direct search using text and image embeddings. However, embedding-based approaches face challenges in integrating contextual features such as user locale and recency. Building a scalable multi-modal search system requires fine-tuning several components. This paper presents a multi-modal search architecture and a series of AB tests that optimize embeddings and multi-modal technologies in Adobe Express template search. We address considerations such as embedding model selection, the roles of embeddings in matching and ranking, and the balance between dense and sparse embeddings. Our iterative approach demonstrates how utilizing sparse, dense, and contextual features enhances short and long query search, significantly reduces null rates (over 70\%), and increases click-through rates (CTR). Our findings provide insights into developing robust multi-modal search systems, thereby enhancing relevance for complex queries.
Semantic In-Domain Product Identification for Search Queries
Apr 13, 2024



Accurate explicit and implicit product identification in search queries is critical for enhancing user experiences, especially at a company like Adobe which has over 50 products and covers queries across hundreds of tools. In this work, we present a novel approach to training a product classifier from user behavioral data. Our semantic model led to >25% relative improvement in CTR (click through rate) across the deployed surfaces; a >50% decrease in null rate; a 2x increase in the app cards surfaced, which helps drive product visibility.
Query Understanding for Natural Language Enterprise Search
Dec 11, 2020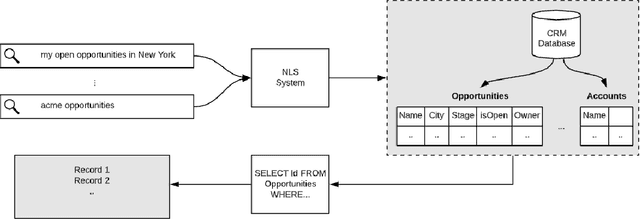
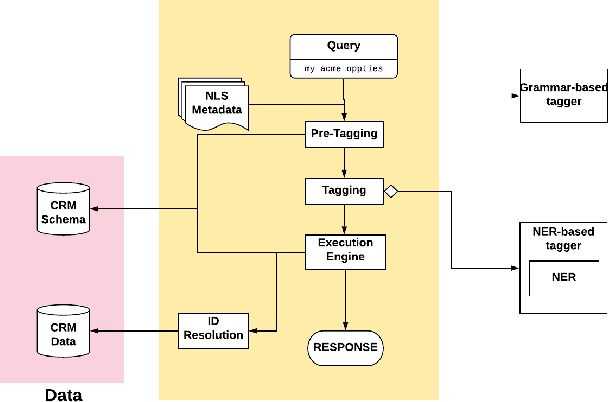

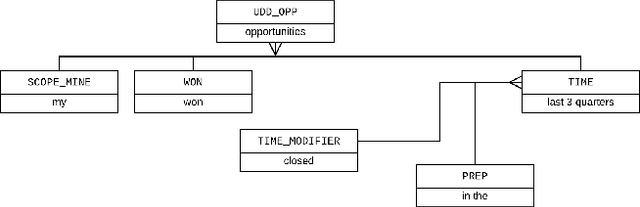
Natural Language Search (NLS) extends the capabilities of search engines that perform keyword search allowing users to issue queries in a more "natural" language. The engine tries to understand the meaning of the queries and to map the query words to the symbols it supports like Persons, Organizations, Time Expressions etc.. It, then, retrieves the information that satisfies the user's need in different forms like an answer, a record or a list of records. We present an NLS system we implemented as part of the Search service of a major CRM platform. The system is currently in production serving thousands of customers. Our user studies showed that creating dynamic reports with NLS saved more than 50% of our user's time compared to achieving the same result with navigational search. We describe the architecture of the system, the particularities of the CRM domain as well as how they have influenced our design decisions. Among several submodules of the system we detail the role of a Deep Learning Named Entity Recognizer. The paper concludes with discussion over the lessons learned while developing this product.
ColloQL: Robust Cross-Domain Text-to-SQL Over Search Queries
Oct 19, 2020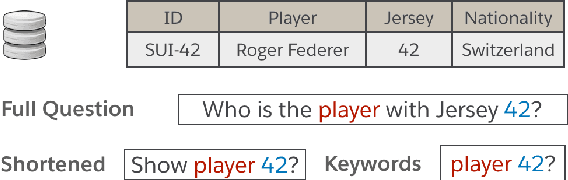

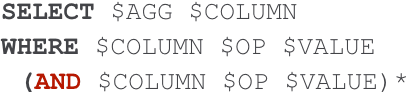

Translating natural language utterances to executable queries is a helpful technique in making the vast amount of data stored in relational databases accessible to a wider range of non-tech-savvy end users. Prior work in this area has largely focused on textual input that is linguistically correct and semantically unambiguous. However, real-world user queries are often succinct, colloquial, and noisy, resembling the input of a search engine. In this work, we introduce data augmentation techniques and a sampling-based content-aware BERT model (ColloQL) to achieve robust text-to-SQL modeling over natural language search (NLS) questions. Due to the lack of evaluation data, we curate a new dataset of NLS questions and demonstrate the efficacy of our approach. ColloQL's superior performance extends to well-formed text, achieving 84.9% (logical) and 90.7% (execution) accuracy on the WikiSQL dataset, making it, to the best of our knowledge, the highest performing model that does not use execution guided decoding.