 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharing Knowledge without Sharing Data: Stitches can improve ensembles of disjointly trained models
Dec 19, 2025



Deep learning has been shown to be very capable at performing many real-world tasks. However, this performance is often dependent on the presence of large and varied datasets. In some settings, like in the medical domain, data is often fragmented across parties, and cannot be readily shared. While federated learning addresses this situation, it is a solution that requires synchronicity of parties training a single model together, exchanging information about model weights. We investigate how asynchronous collaboration, where only already trained models are shared (e.g. as part of a publication), affects performance, and propose to use stitching as a method for combining models. Through taking a multi-objective perspective, where performance on each parties' data is viewed independently, we find that training solely on a single parties' data results in similar performance when merging with another parties' data, when considering performance on that single parties' data, while performance on other parties' data is notably worse. Moreover, while an ensemble of such individually trained networks generalizes better, performance on each parties' own dataset suffers. We find that combining intermediate representations in individually trained models with a well placed pair of stitching layers allows this performance to recover to a competitive degree while maintaining improved generalization, showing that asynchronous collaboration can yield competitive results.
Stitching for Neuroevolution: Recombining Deep Neural Networks without Breaking Them
Mar 21, 2024



Traditional approaches to neuroevolution often start from scratch. This becomes prohibitively expensive in terms of computational and data requirements when targeting modern, deep neural networks. Using a warm start could be highly advantageous, e.g., using previously trained networks, potentially from different sources. This moreover enables leveraging the benefits of transfer learning (in particular vastly reduced training effort). However, recombining trained networks is non-trivial because architectures and feature representations typically differ. Consequently, a straightforward exchange of layers tends to lead to a performance breakdown. We overcome this by matching the layers of parent networks based on their connectivity, identifying potential crossover points. To correct for differing feature representations between these layers we employ stitching, which merges the networks by introducing new layers at crossover points. To train the merged network, only stitching layers need to be considered. New networks can then be created by selecting a subnetwork by choosing which stitching layers to (not) use. Assessing their performance is efficient as only their evaluation on data is required. We experimentally show that our approach enables finding networks that represent novel trade-offs between performance and computational cost, with some even dominating the original networks.
The Impact of Asynchrony on Parallel Model-Based EAs
Mar 27, 2023



In a parallel EA one can strictly adhere to the generational clock, and wait for all evaluations in a generation to be done. However, this idle time limits the throughput of the algorithm and wastes computational resources. Alternatively, an EA can be made asynchronous parallel. However, EAs using classic recombination and selection operators (GAs) are known to suffer from an evaluation time bias, which also influences the performance of the approach. Model-Based Evolutionary Algorithms (MBEAs) are more scalable than classic GAs by virtue of capturing the structure of a problem in a model. If this model is learned through linkage learning based on the population, the learned model may also capture biases. Thus, if an asynchronous parallel MBEA is also affected by an evaluation time bias, this could result in learned models to be less suited to solving the problem, reducing performance. Therefore, in this work, we study the impact and presence of evaluation time biases on MBEAs in an asynchronous parallelization setting, and compare this to the biases in GAs. We find that a modern MBEA, GOMEA, is unaffected by evaluation time biases, while the more classical MBEA, ECGA, is affected, much like GAs are.
Solving Multi-Structured Problems by Introducing Linkage Kernels into GOMEA
Mar 11, 2022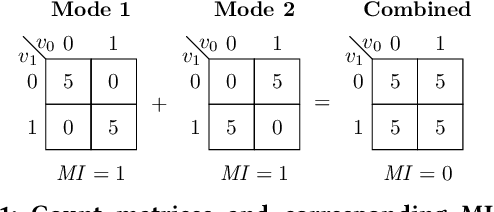
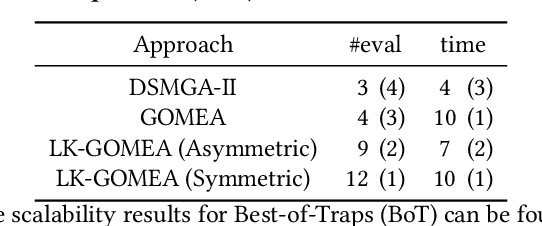
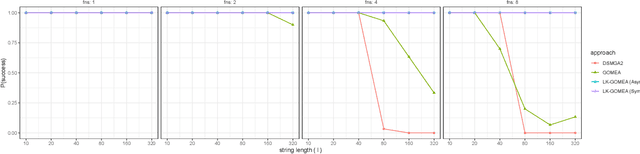
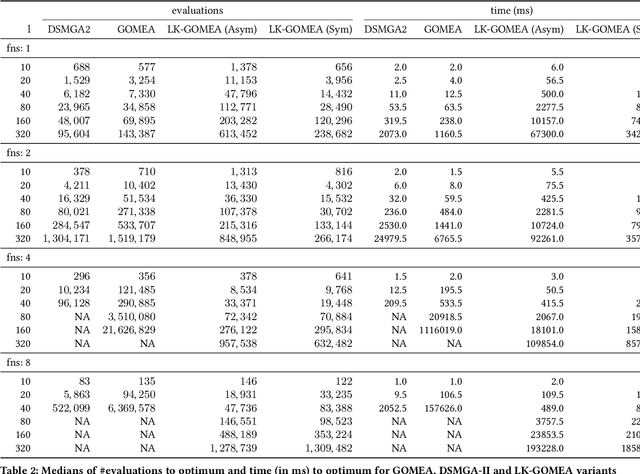
Model-Based Evolutionary Algorithms (MBEAs) can be highly scalable by virtue of linkage (or variable interaction) learning. This requires, however, that the linkage model can capture the exploitable structure of a problem. Usually, a single type of linkage structure is attempted to be captured using models such as a linkage tree. However, in practice, problems may exhibit multiple linkage structures. This is for instance the case in multi-objective optimization when the objectives have different linkage structures. This cannot be modelled sufficiently well when using linkage models that aim at capturing a single type of linkage structure, deteriorating the advantages brought by MBEAs. Therefore, here, we introduce linkage kernels, whereby a linkage structure is learned for each solution over its local neighborhood. We implement linkage kernels into the MBEA known as GOMEA that was previously found to be highly scalable when solving various problems. We further introduce a novel benchmark function called Best-of-Traps (BoT) that has an adjustable degree of different linkage structures. On both BoT and a worst-case scenario-based variant of the well-known MaxCut problem, we experimentally find a vast performance improvement of linkage-kernel GOMEA over GOMEA with a single linkage tree as well as the MBEA known as DSMGA-II.
EXPObench: Benchmarking Surrogate-based Optimisation Algorithms on Expensive Black-box Functions
Jun 08, 2021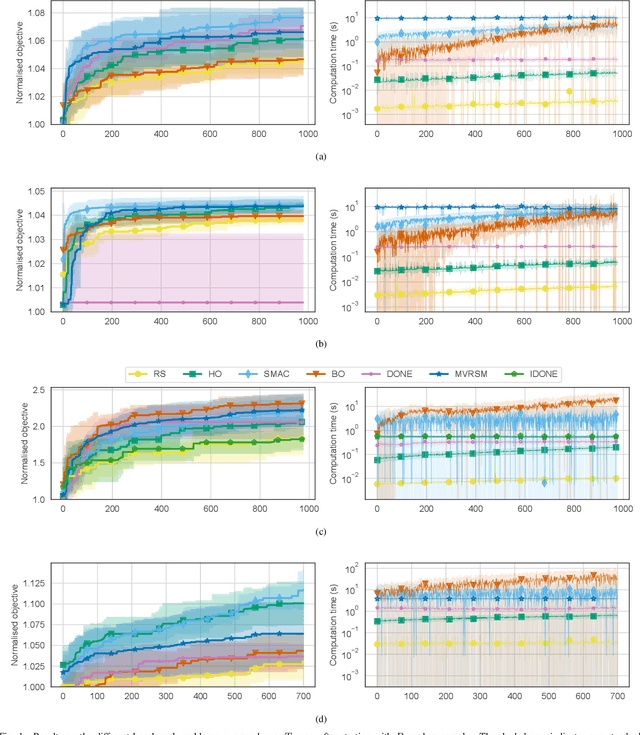
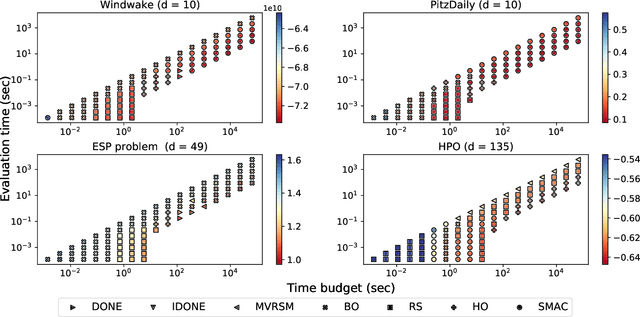
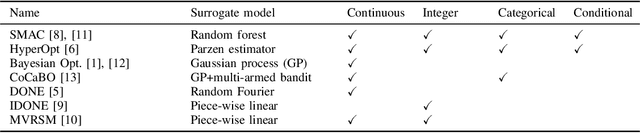
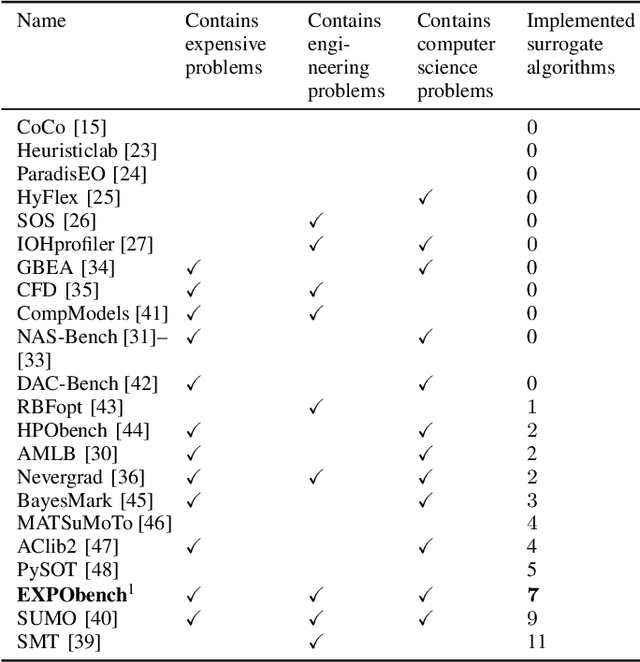
Surrogate algorithms such as Bayesian optimisation are especially designed for black-box optimisation problems with expensive objectives, such as hyperparameter tuning or simulation-based optimisation. In the literature, these algorithms are usually evaluated with synthetic benchmarks which are well established but have no expensive objective, and only on one or two real-life applications which vary wildly between papers. There is a clear lack of standardisation when it comes to benchmarking surrogate algorithms on real-life, expensive, black-box objective functions. This makes it very difficult to draw conclusions on the effect of algorithmic contributions. A new benchmark library, EXPObench, provides first steps towards such a standardisation. The library is used to provide an extensive comparison of six different surrogate algorithms on four expensive optimisation problems from different real-life applications. This has led to new insights regarding the relative importance of exploration, the evaluation time of the objective, and the used model. A further contribution is that we make the algorithms and benchmark problem instances publicly available, contributing to more uniform analysis of surrogate algorithms. Most importantly, we include the performance of the six algorithms on all evaluated problem instances. This results in a unique new dataset that lowers the bar for researching new methods as the number of expensive evaluations required for comparison is significantly reduced.
Order Acceptance and Scheduling with Sequence-dependent Setup Times: a New Memetic Algorithm and Benchmark of the State of the Art
Oct 04, 2019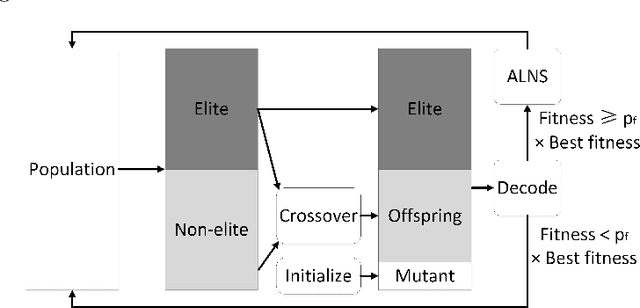
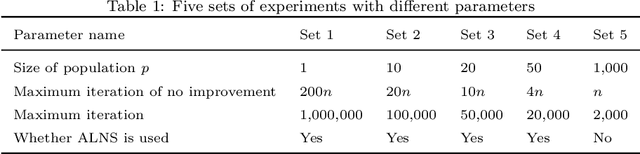
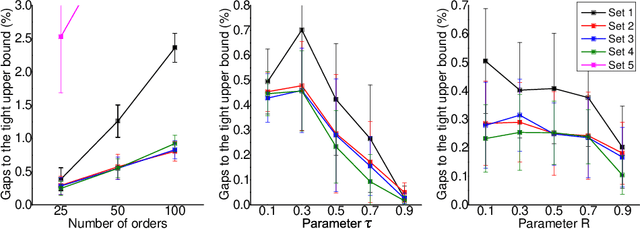
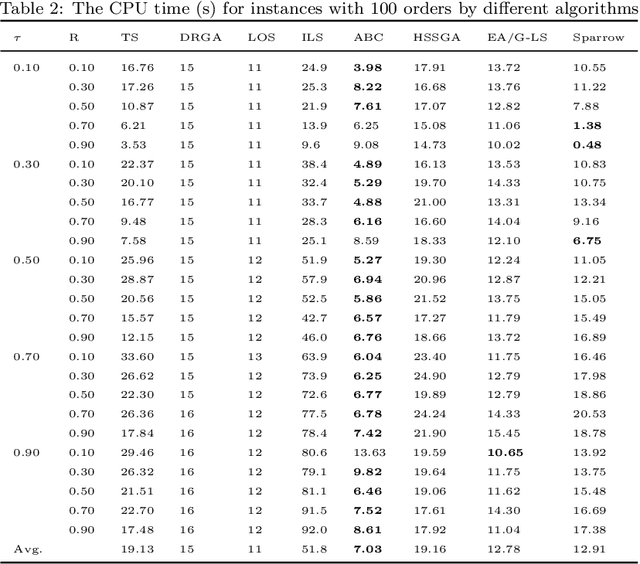
The Order Acceptance and Scheduling (OAS) problem describes a class of real-world problems such as in smart manufacturing and satellite scheduling. This problem consists of simultaneously selecting a subset of orders to be processed as well as determining the associated schedule. A common generalization includes sequence-dependent setup times and time windows. A novel memetic algorithm for this problem, called Sparrow, comprises a hybridization of biased random key genetic algorithm (BRKGA) and adaptive large neighbourhood search (ALNS). Sparrow integrates the exploration ability of BRKGA and the exploitation ability of ALNS. On a set of standard benchmark instances, this algorithm obtains better-quality solutions with runtimes comparable to state-of-the-art algorithms. To further understand the strengths and weaknesses of these algorithms, their performance is also compared on a set of new benchmark instances with more realistic properties. We conclude that Sparrow is distinguished by its ability to solve difficult instances from the OAS literature, and that the hybrid steady-state genetic algorithm (HSSGA) performs well on large instances in terms of optimality gap, although taking more time than Sparrow.