 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOVID-19: Strategies for Allocation of Test Kits
Apr 03, 2020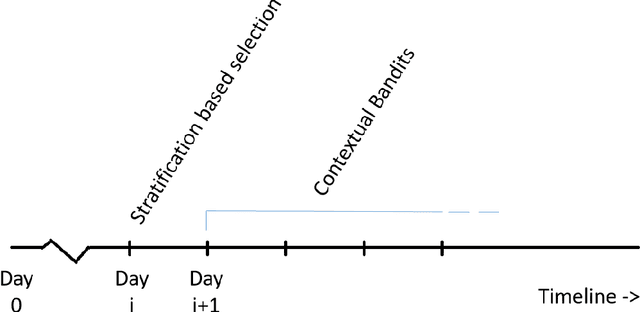
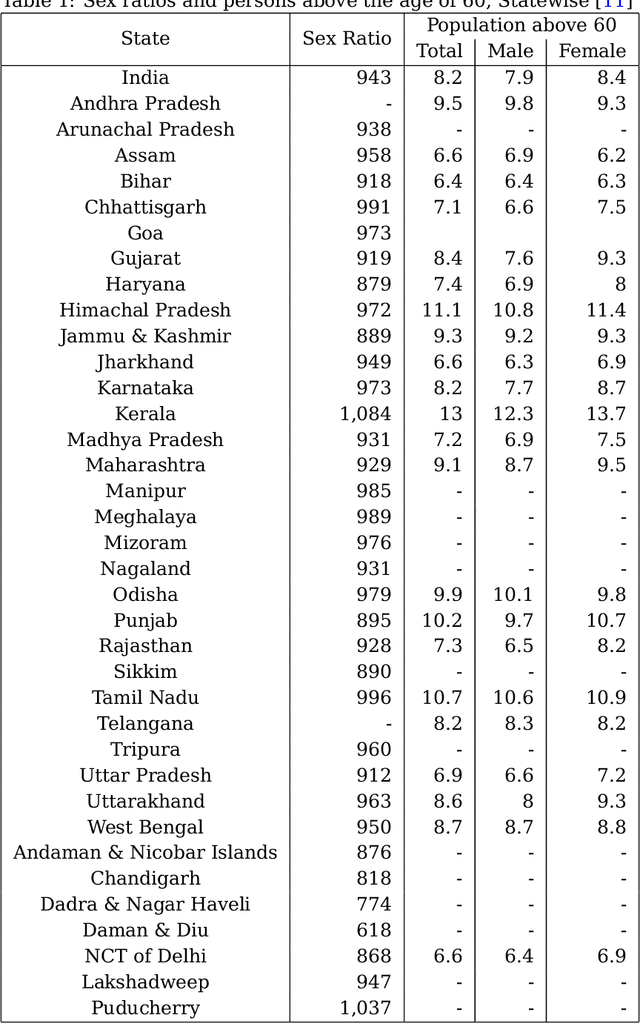
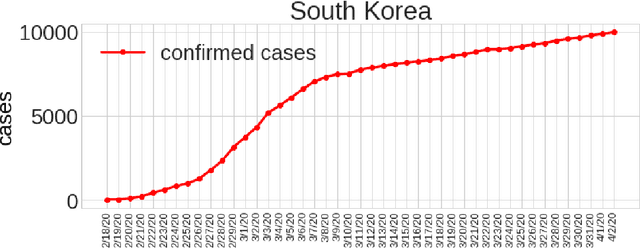
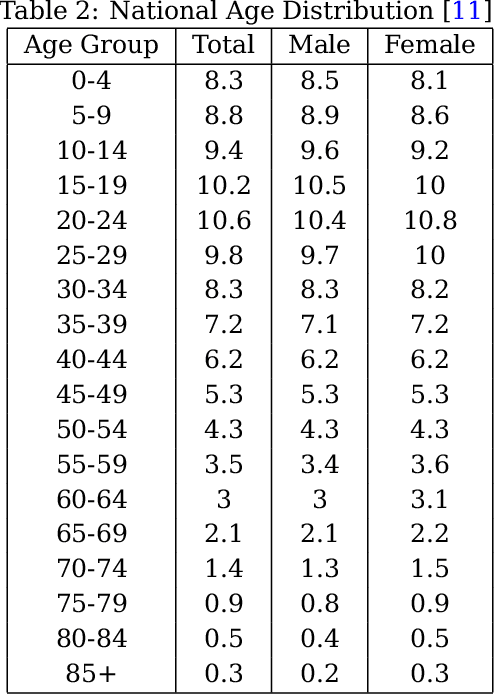
With the increasing spread of COVID-19, it is important to systematically test more and more people. The current strategy for test-kit allocation is mostly rule-based, focusing on individuals having (a) symptoms for COVID-19, (b) travel history or (c) contact history with confirmed COVID-19 patients. Such testing strategy may miss out on detecting asymptomatic individuals who got infected via community spread. Thus, it is important to allocate a separate budget of test-kits per day targeted towards preventing community spread and detecting new cases early on. In this report, we consider the problem of allocating test-kits and discuss some solution approaches. We believe that these approaches will be useful to contain community spread and detect new cases early on. Additionally, these approaches would help in collecting unbiased data which can then be used to improve the accuracy of machine learning models trained to predict COVID-19 infections.
FairRec: Two-Sided Fairness for Personalized Recommendations in Two-Sided Platforms
Feb 25, 2020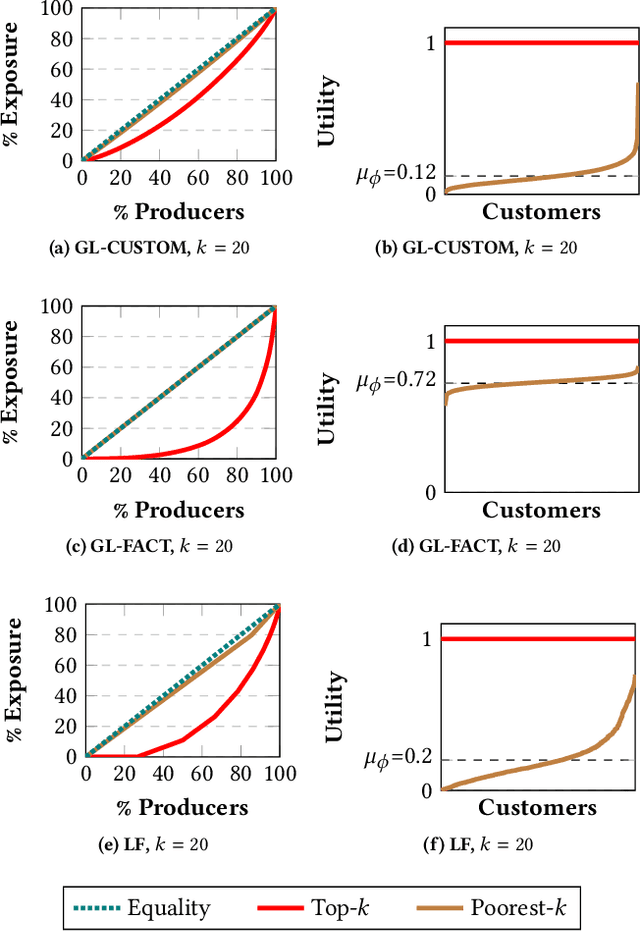
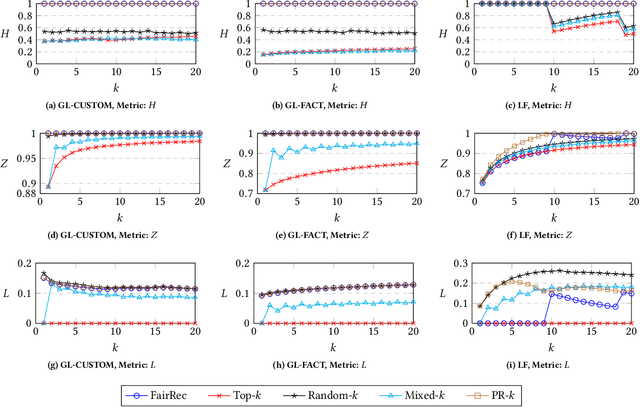
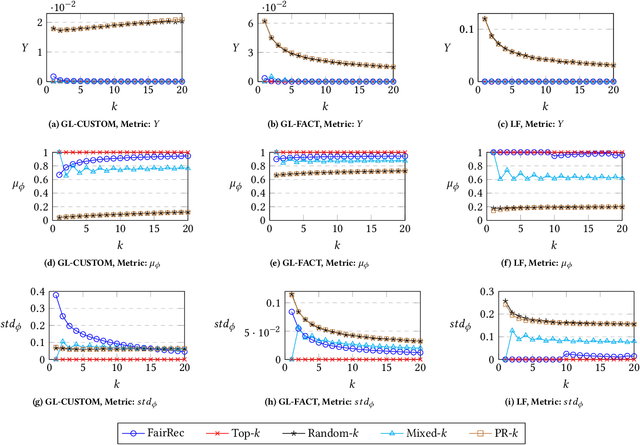
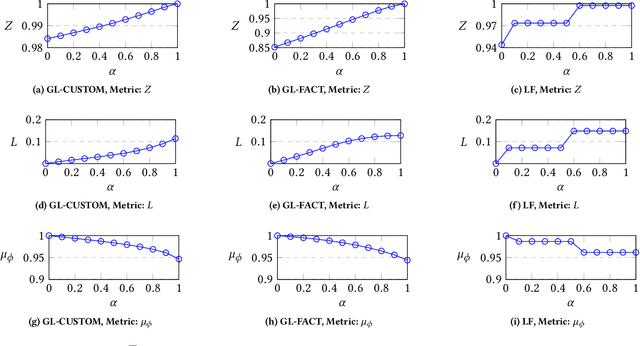
We investigate the problem of fair recommendation in the context of two-sided online platforms, comprising customers on one side and producers on the other. Traditionally, recommendation services in these platforms have focused on maximizing customer satisfaction by tailoring the results according to the personalized preferences of individual customers. However, our investigation reveals that such customer-centric design may lead to unfair distribution of exposure among the producers, which may adversely impact their well-being. On the other hand, a producer-centric design might become unfair to the customers. Thus, we consider fairness issues that span both customers and producers. Our approach involves a novel mapping of the fair recommendation problem to a constrained version of the problem of fairly allocating indivisible goods. Our proposed FairRec algorithm guarantees at least Maximin Share (MMS) of exposure for most of the producers and Envy-Free up to One item (EF1) fairness for every customer. Extensive evaluations over multiple real-world datasets show the effectiveness of FairRec in ensuring two-sided fairness while incurring a marginal loss in the overall recommendation quality.
Quantifying Infra-Marginality and Its Trade-off with Group Fairness
Sep 03, 2019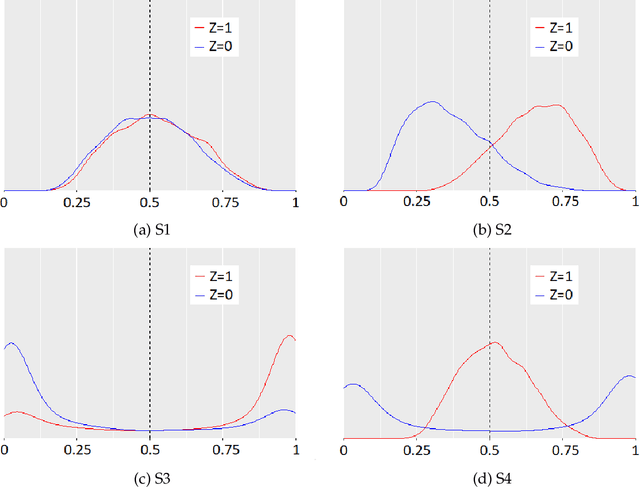
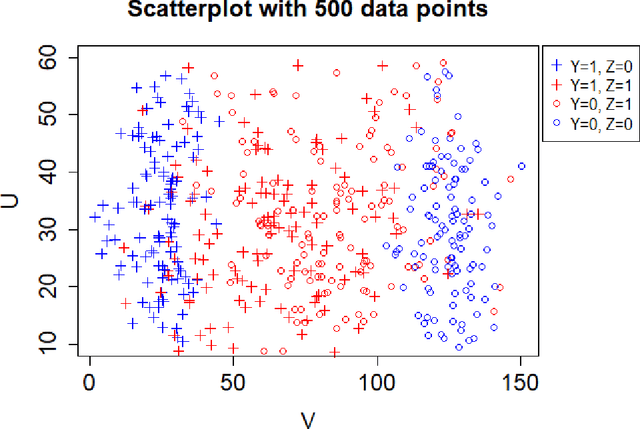
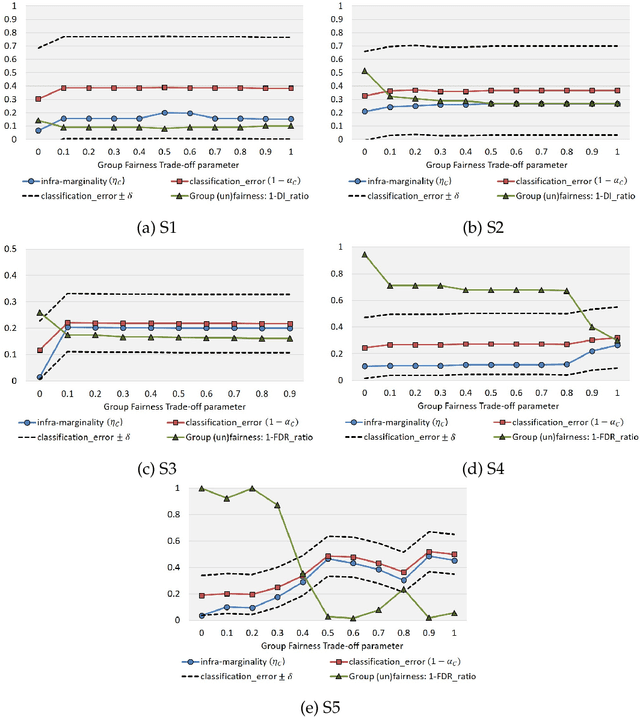
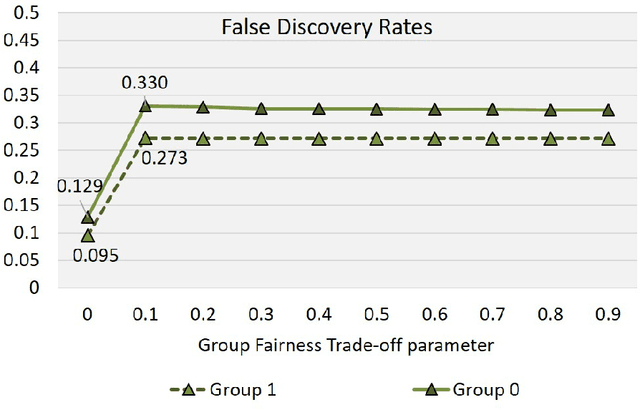
In critical decision-making scenarios, optimizing accuracy can lead to a biased classifier, hence past work recommends enforcing group-based fairness metrics in addition to maximizing accuracy. However, doing so exposes the classifier to another kind of bias called infra-marginality. This refers to individual-level bias where some individuals/subgroups can be worse off than under simply optimizing for accuracy. For instance, a classifier implementing race-based parity may significantly disadvantage women of the advantaged race. To quantify this bias, we propose a general notion of $\eta$-infra-marginality that can be used to evaluate the extent of this bias. We prove theoretically that, unlike other fairness metrics, infra-marginality does not have a trade-off with accuracy: high accuracy directly leads to low infra-marginality. This observation is confirmed through empirical analysis on multiple simulated and real-world datasets. Further, we find that maximizing group fairness often increases infra-marginality, suggesting the consideration of both group-level fairness and individual-level infra-marginality. However, measuring infra-marginality requires knowledge of the true distribution of individual-level outcomes correctly and explicitly. We propose a practical method to measure infra-marginality, and a simple algorithm to maximize group-wise accuracy and avoid infra-marginality.
Fair Division Under Cardinality Constraints
Jul 23, 2018We consider the problem of fairly allocating indivisible goods, among agents, under cardinality constraints and additive valuations. In this setting, we are given a partition of the entire set of goods---i.e., the goods are categorized---and a limit is specified on the number of goods that can be allocated from each category to any agent. The objective here is to find a fair allocation in which the subset of goods assigned to any agent satisfies the given cardinality constraints. This problem naturally captures a number of resource-allocation applications, and is a generalization of the well-studied (unconstrained) fair division problem. The two central notions of fairness, in the context of fair division of indivisible goods, are envy freeness up to one good (EF1) and the (approximate) maximin share guarantee (MMS). We show that the existence and algorithmic guarantees established for these solution concepts in the unconstrained setting can essentially be achieved under cardinality constraints. Specifically, we develop efficient algorithms which compute EF1 and approximately MMS allocations in the constrained setting. Furthermore, focusing on the case wherein all the agents have the same additive valuation, we establish that EF1 allocations exist and can be computed efficiently even under matroid constraints.
Groupwise Maximin Fair Allocation of Indivisible Goods
Nov 21, 2017We study the problem of allocating indivisible goods among n agents in a fair manner. For this problem, maximin share (MMS) is a well-studied solution concept which provides a fairness threshold. Specifically, maximin share is defined as the minimum utility that an agent can guarantee for herself when asked to partition the set of goods into n bundles such that the remaining (n-1) agents pick their bundles adversarially. An allocation is deemed to be fair if every agent gets a bundle whose valuation is at least her maximin share. Even though maximin shares provide a natural benchmark for fairness, it has its own drawbacks and, in particular, it is not sufficient to rule out unsatisfactory allocations. Motivated by these considerations, in this work we define a stronger notion of fairness, called groupwise maximin share guarantee (GMMS). In GMMS, we require that the maximin share guarantee is achieved not just with respect to the grand bundle, but also among all the subgroups of agents. Hence, this solution concept strengthens MMS and provides an ex-post fairness guarantee. We show that in specific settings, GMMS allocations always exist. We also establish the existence of approximate GMMS allocations under additive valuations, and develop a polynomial-time algorithm to find such allocations. Moreover, we establish a scale of fairness wherein we show that GMMS implies approximate envy freeness. Finally, we empirically demonstrate the existence of GMMS allocations in a large set of randomly generated instances. For the same set of instances, we additionally show that our algorithm achieves an approximation factor better than the established, worst-case bound.
Managing Overstaying Electric Vehicles in Park-and-Charge Facilities
Jul 14, 2016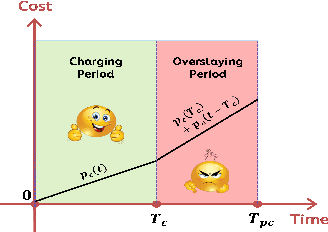
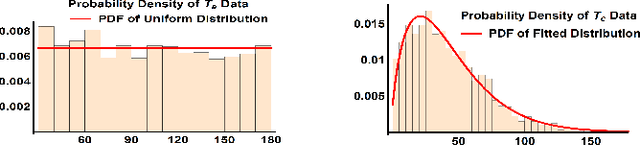
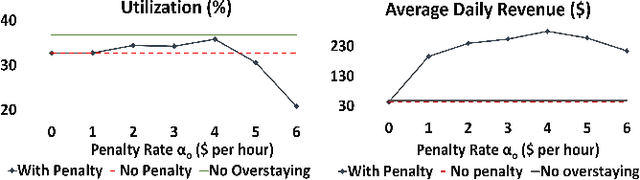
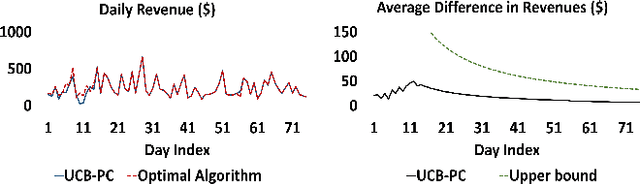
With the increase in adoption of Electric Vehicles (EVs), proper utilization of the charging infrastructure is an emerging challenge for service providers. Overstaying of an EV after a charging event is a key contributor to low utilization. Since overstaying is easily detectable by monitoring the power drawn from the charger, managing this problem primarily involves designing an appropriate "penalty" during the overstaying period. Higher penalties do discourage overstaying; however, due to uncertainty in parking duration, less people would find such penalties acceptable, leading to decreased utilization (and revenue). To analyze this central trade-off, we develop a novel framework that integrates models for realistic user behavior into queueing dynamics to locate the optimal penalty from the points of view of utilization and revenue, for different values of the external charging demand. Next, when the model parameters are unknown, we show how an online learning algorithm, such as UCB, can be adapted to learn the optimal penalty. Our experimental validation, based on charging data from London, shows that an appropriate penalty can increase both utilization and revenue while significantly reducing overstaying.
Demand Prediction and Placement Optimization for Electric Vehicle Charging Stations
Jul 13, 2016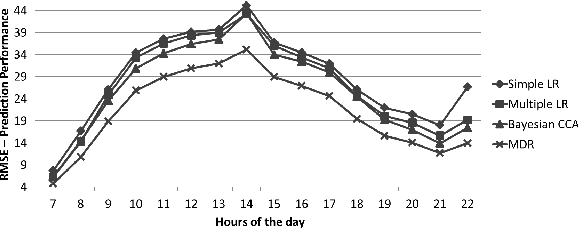

Effective placement of charging stations plays a key role in Electric Vehicle (EV) adoption. In the placement problem, given a set of candidate sites, an optimal subset needs to be selected with respect to the concerns of both (a) the charging station service provider, such as the demand at the candidate sites and the budget for deployment, and (b) the EV user, such as charging station reachability and short waiting times at the station. This work addresses these concerns, making the following three novel contributions: (i) a supervised multi-view learning framework using Canonical Correlation Analysis (CCA) for demand prediction at candidate sites, using multiple datasets such as points of interest information, traffic density, and the historical usage at existing charging stations; (ii) a mixed-packing-and- covering optimization framework that models competing concerns of the service provider and EV users; (iii) an iterative heuristic to solve these problems by alternately invoking knapsack and set cover algorithms. The performance of the demand prediction model and the placement optimization heuristic are evaluated using real world data.