 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeItem Level Exploration Traffic Allocation in Large-scale Recommendation Systems
May 14, 2025



This paper contributes to addressing the item cold start problem in large-scale recommender systems, focusing on how to efficiently gain initial visibility for newly ingested content. We propose an exploration system designed to efficiently allocate impressions to these fresh items. Our approach leverages a learned probabilistic model to predict an item's discoverability, which then informs a scalable and adaptive traffic allocation strategy. This system intelligently distributes exploration budgets, optimizing for the long-term benefit of the recommendation platform. The impact is a demonstrably more efficient cold-start process, leading to a significant increase in the discoverability of new content and ultimately enriching the item corpus available for exploitation, as evidenced by its successful deployment in a large-scale production environment.
Scaling up Dynamic Topic Models
Feb 19, 2016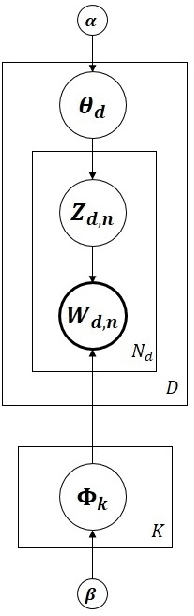

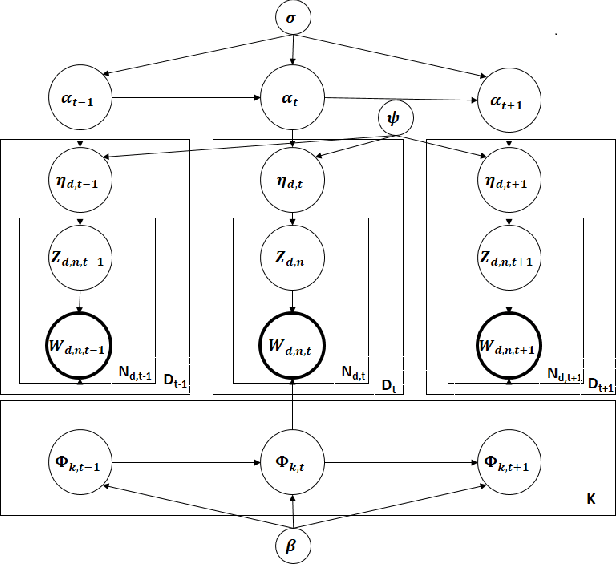

Dynamic topic models (DTMs) are very effective in discovering topics and capturing their evolution trends in time series data. To do posterior inference of DTMs, existing methods are all batch algorithms that scan the full dataset before each update of the model and make inexact variational approximations with mean-field assumptions. Due to a lack of a more scalable inference algorithm, despite the usefulness, DTMs have not captured large topic dynamics. This paper fills this research void, and presents a fast and parallelizable inference algorithm using Gibbs Sampling with Stochastic Gradient Langevin Dynamics that does not make any unwarranted assumptions. We also present a Metropolis-Hastings based $O(1)$ sampler for topic assignments for each word token. In a distributed environment, our algorithm requires very little communication between workers during sampling (almost embarrassingly parallel) and scales up to large-scale applications. We are able to learn the largest Dynamic Topic Model to our knowledge, and learned the dynamics of 1,000 topics from 2.6 million documents in less than half an hour, and our empirical results show that our algorithm is not only orders of magnitude faster than the baselines but also achieves lower perplexity.