 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe emojification of sentiment on social media: Collection and analysis of a longitudinal Twitter sentiment dataset
Aug 31, 2021
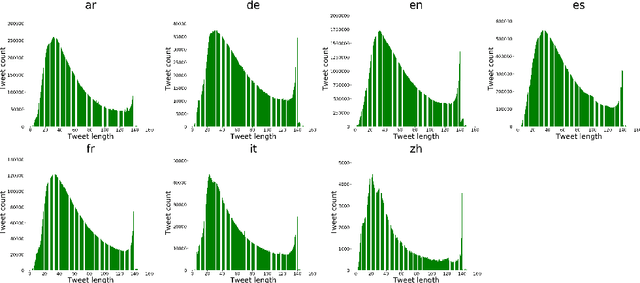
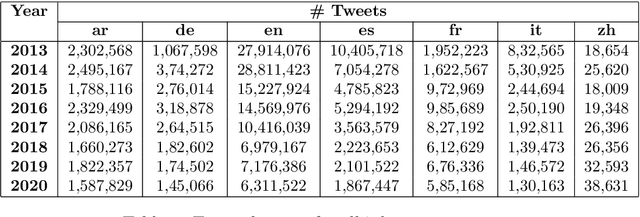
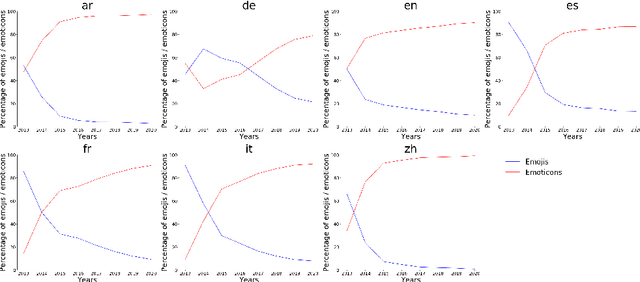
Social media, as a means for computer-mediated communication, has been extensively used to study the sentiment expressed by users around events or topics. There is however a gap in the longitudinal study of how sentiment evolved in social media over the years. To fill this gap, we develop TM-Senti, a new large-scale, distantly supervised Twitter sentiment dataset with over 184 million tweets and covering a time period of over seven years. We describe and assess our methodology to put together a large-scale, emoticon- and emoji-based labelled sentiment analysis dataset, along with an analysis of the resulting dataset. Our analysis highlights interesting temporal changes, among others in the increasing use of emojis over emoticons. We publicly release the dataset for further research in tasks including sentiment analysis and text classification of tweets. The dataset can be fully rehydrated including tweet metadata and without missing tweets thanks to the archive of tweets publicly available on the Internet Archive, which the dataset is based on.
Opinions are Made to be Changed: Temporally Adaptive Stance Classification
Aug 27, 2021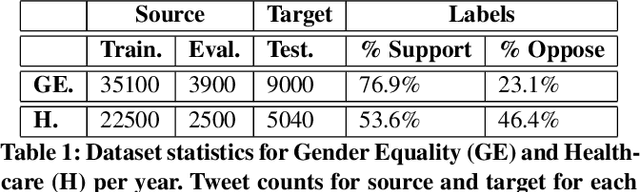
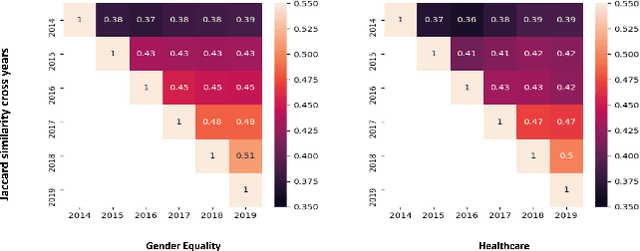
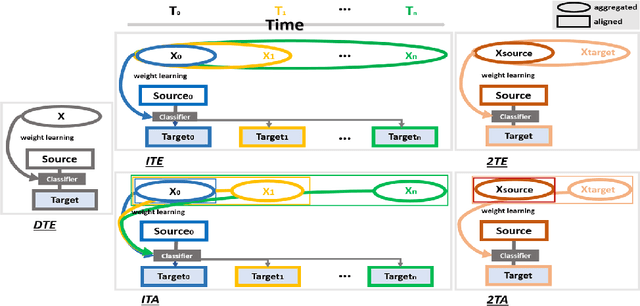
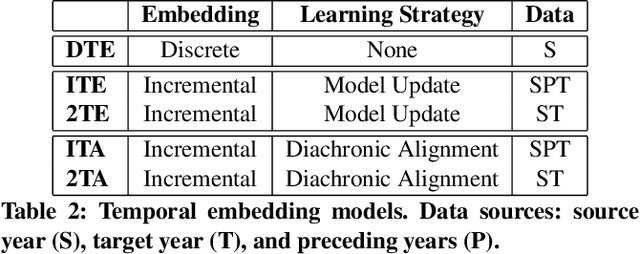
Given the rapidly evolving nature of social media and people's views, word usage changes over time. Consequently, the performance of a classifier trained on old textual data can drop dramatically when tested on newer data. While research in stance classification has advanced in recent years, no effort has been invested in making these classifiers have persistent performance over time. To study this phenomenon we introduce two novel large-scale, longitudinal stance datasets. We then evaluate the performance persistence of stance classifiers over time and demonstrate how it decays as the temporal gap between training and testing data increases. We propose a novel approach to mitigate this performance drop, which is based on temporal adaptation of the word embeddings used for training the stance classifier. This enables us to make use of readily available unlabelled data from the current time period instead of expensive annotation efforts. We propose and compare several approaches to embedding adaptation and find that the Incremental Temporal Alignment (ITA) model leads to the best results in reducing performance drop over time.
Weakly Supervised Cross-platform Teenager Detection with Adversarial BERT
Aug 24, 2021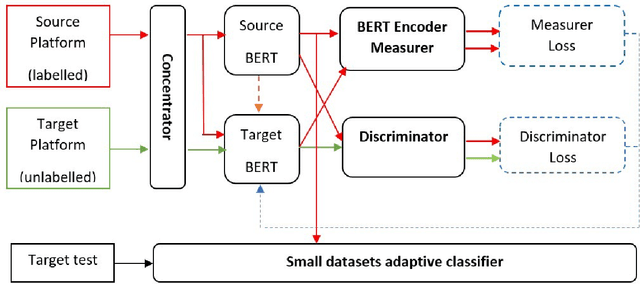
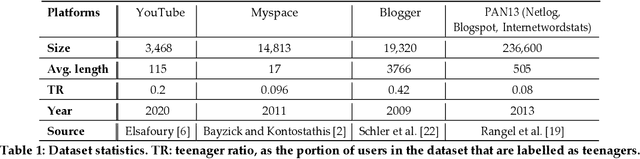
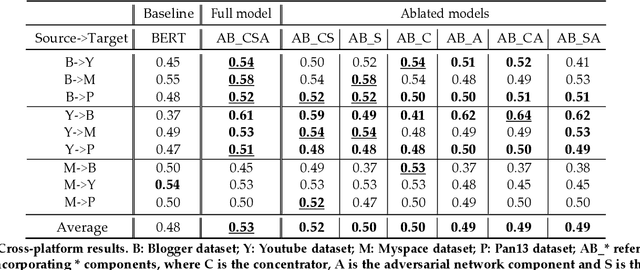
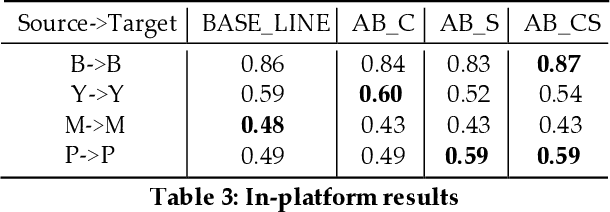
Teenager detection is an important case of the age detection task in social media, which aims to detect teenage users to protect them from negative influences. The teenager detection task suffers from the scarcity of labelled data, which exacerbates the ability to perform well across social media platforms. To further research in teenager detection in settings where no labelled data is available for a platform, we propose a novel cross-platform framework based on Adversarial BERT. Our framework can operate with a limited amount of labelled instances from the source platform and with no labelled data from the target platform, transferring knowledge from the source to the target social media. We experiment on four publicly available datasets, obtaining results demonstrating that our framework can significantly improve over competitive baseline models on the cross-platform teenager detection task.
Cross-lingual Capsule Network for Hate Speech Detection in Social Media
Aug 06, 2021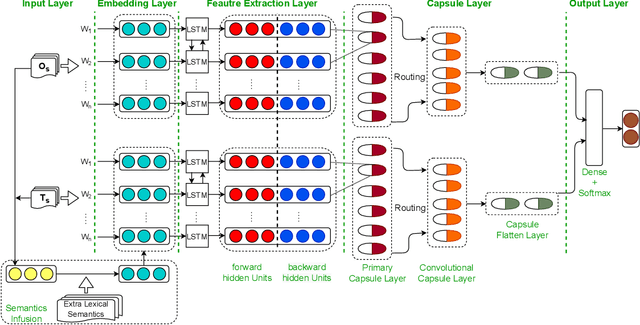
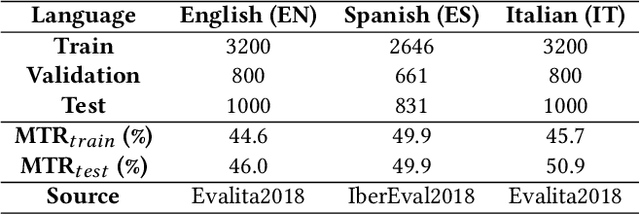
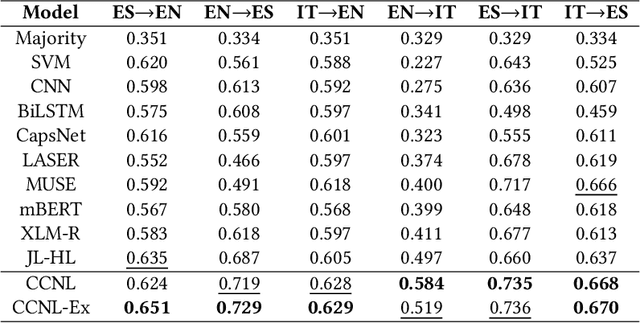
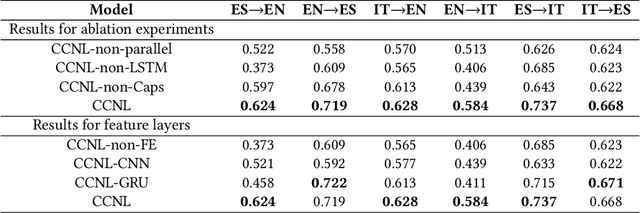
Most hate speech detection research focuses on a single language, generally English, which limits their generalisability to other languages. In this paper we investigate the cross-lingual hate speech detection task, tackling the problem by adapting the hate speech resources from one language to another. We propose a cross-lingual capsule network learning model coupled with extra domain-specific lexical semantics for hate speech (CCNL-Ex). Our model achieves state-of-the-art performance on benchmark datasets from AMI@Evalita2018 and AMI@Ibereval2018 involving three languages: English, Spanish and Italian, outperforming state-of-the-art baselines on all six language pairs.
SWSR: A Chinese Dataset and Lexicon for Online Sexism Detection
Aug 06, 2021
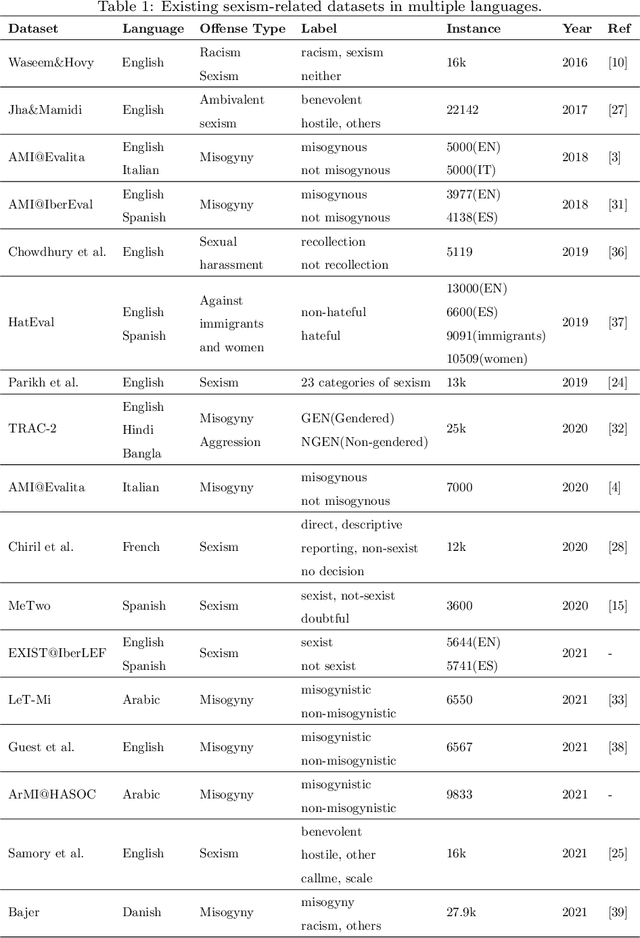
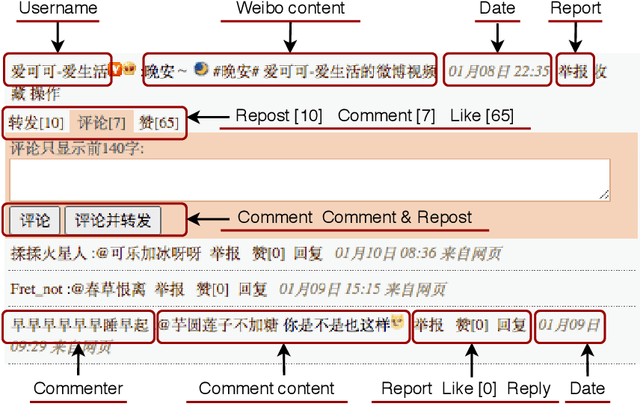
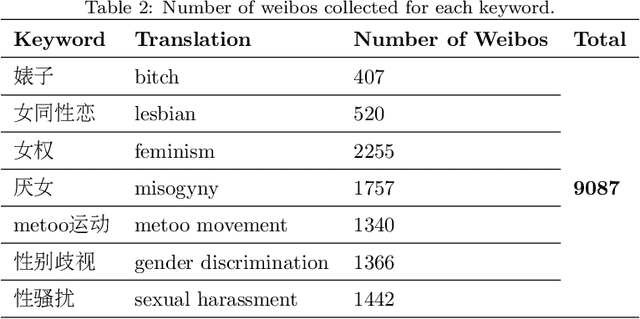
Online sexism has become an increasing concern in social media platforms as it has affected the healthy development of the Internet and can have negative effects in society. While research in the sexism detection domain is growing, most of this research focuses on English as the language and on Twitter as the platform. Our objective here is to broaden the scope of this research by considering the Chinese language on Sina Weibo. We propose the first Chinese sexism dataset -- Sina Weibo Sexism Review (SWSR) dataset --, as well as a large Chinese lexicon SexHateLex made of abusive and gender-related terms. We introduce our data collection and annotation process, and provide an exploratory analysis of the dataset characteristics to validate its quality and to show how sexism is manifested in Chinese. The SWSR dataset provides labels at different levels of granularity including (i) sexism or non-sexism, (ii) sexism category and (iii) target type, which can be exploited, among others, for building computational methods to identify and investigate finer-grained gender-related abusive language. We conduct experiments for the three sexism classification tasks making use of state-of-the-art machine learning models. Our results show competitive performance, providing a benchmark for sexism detection in the Chinese language, as well as an error analysis highlighting open challenges needing more research in Chinese NLP. The SWSR dataset and SexHateLex lexicon are publicly available.
QMUL-SDS at SCIVER: Step-by-Step Binary Classification for Scientific Claim Verification
Apr 23, 2021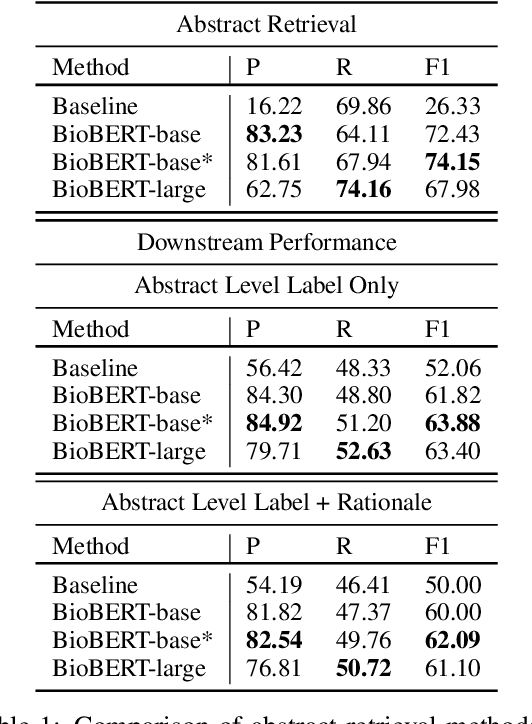
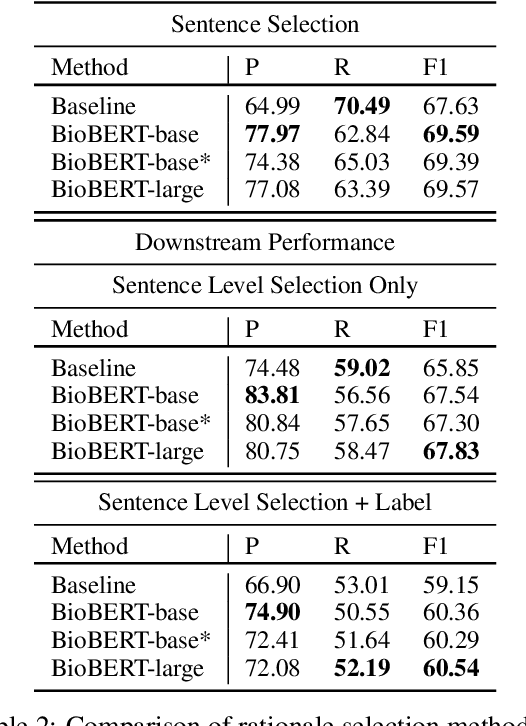
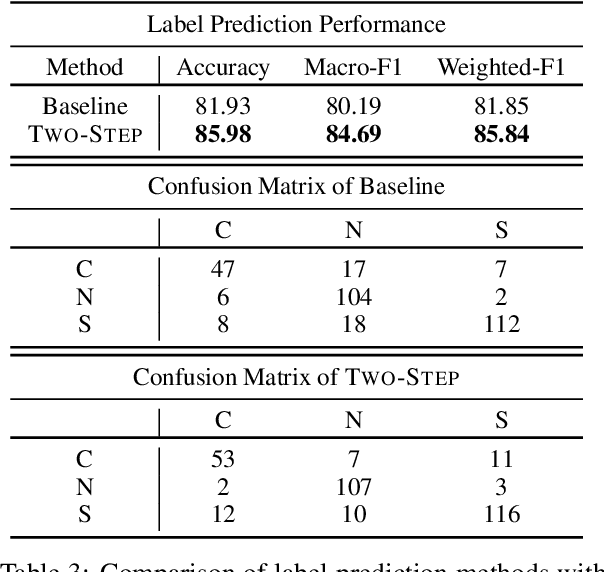
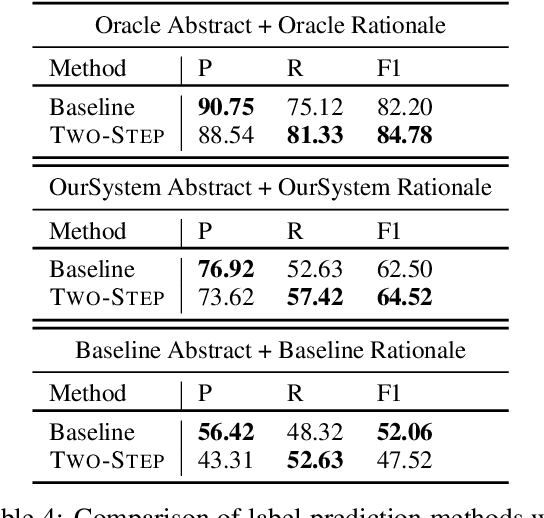
Scientific claim verification is a unique challenge that is attracting increasing interest. The SCIVER shared task offers a benchmark scenario to test and compare claim verification approaches by participating teams and consists in three steps: relevant abstract selection, rationale selection and label prediction. In this paper, we present team QMUL-SDS's participation in the shared task. We propose an approach that performs scientific claim verification by doing binary classifications step-by-step. We trained a BioBERT-large classifier to select abstracts based on pairwise relevance assessments for each <claim, title of the abstract> and continued to train it to select rationales out of each retrieved abstract based on <claim, sentence>. We then propose a two-step setting for label prediction, i.e. first predicting "NOT_ENOUGH_INFO" or "ENOUGH_INFO", then label those marked as "ENOUGH_INFO" as either "SUPPORT" or "CONTRADICT". Compared to the baseline system, we achieve substantial improvements on the dev set. As a result, our team is the No. 4 team on the leaderboard.
Citizen Participation and Machine Learning for a Better Democracy
Feb 28, 2021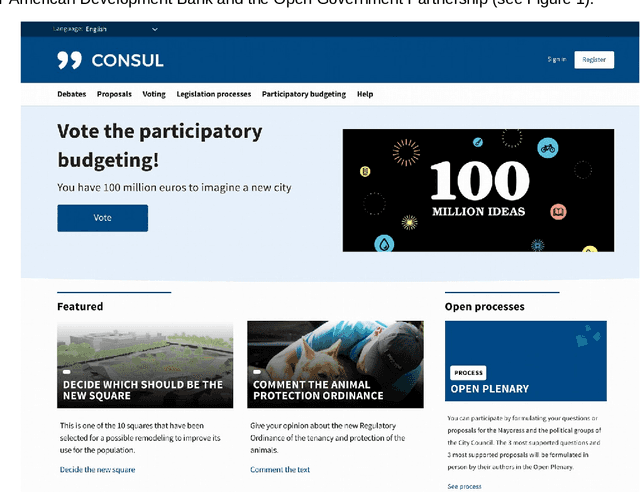

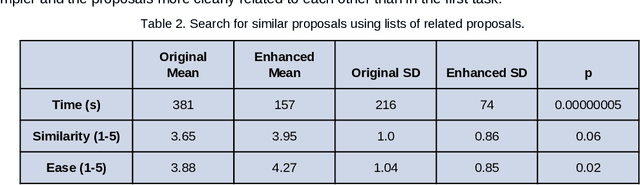
The development of democratic systems is a crucial task as confirmed by its selection as one of the Millennium Sustainable Development Goals by the United Nations. In this article, we report on the progress of a project that aims to address barriers, one of which is information overload, to achieving effective direct citizen participation in democratic decision-making processes. The main objectives are to explore if the application of Natural Language Processing (NLP) and machine learning can improve citizens' experience of digital citizen participation platforms. Taking as a case study the "Decide Madrid" Consul platform, which enables citizens to post proposals for policies they would like to see adopted by the city council, we used NLP and machine learning to provide new ways to (a) suggest to citizens proposals they might wish to support; (b) group citizens by interests so that they can more easily interact with each other; (c) summarise comments posted in response to proposals; (d) assist citizens in aggregating and developing proposals. Evaluation of the results confirms that NLP and machine learning have a role to play in addressing some of the barriers users of platforms such as Consul currently experience.
Towards generalisable hate speech detection: a review on obstacles and solutions
Feb 17, 2021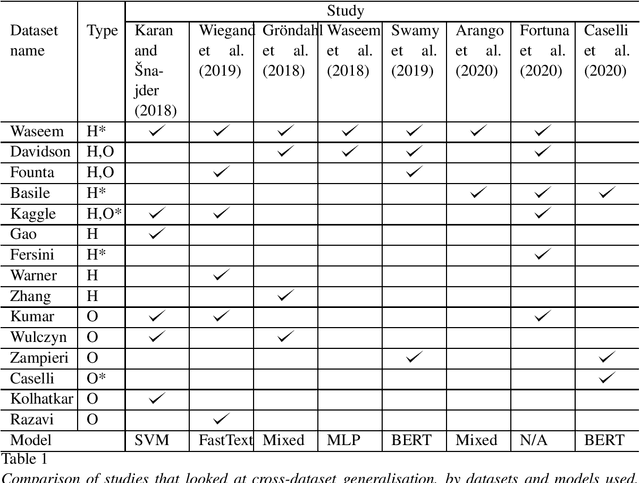
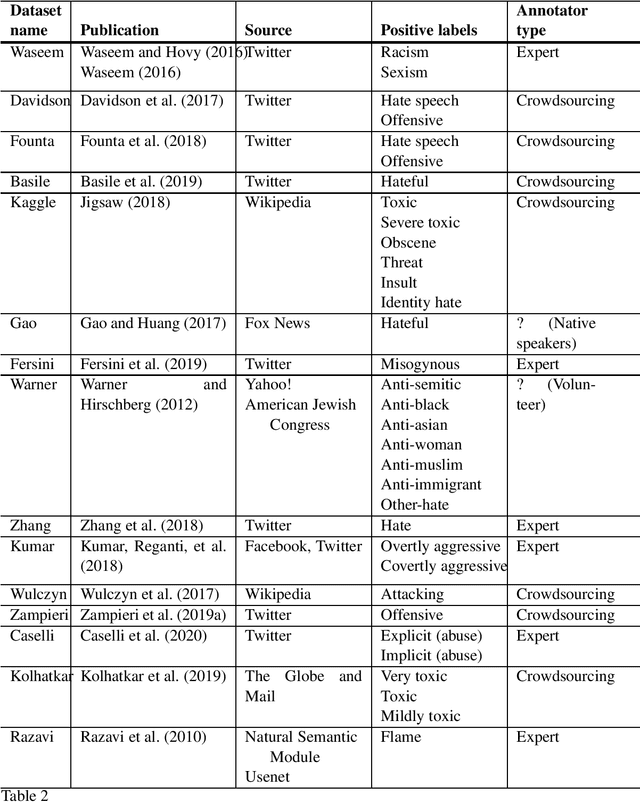
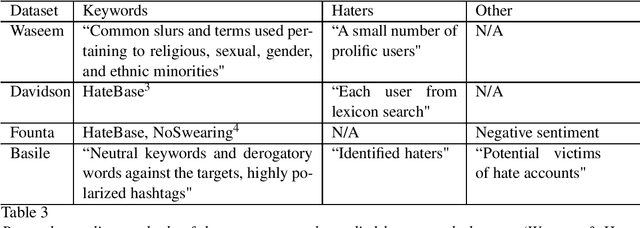
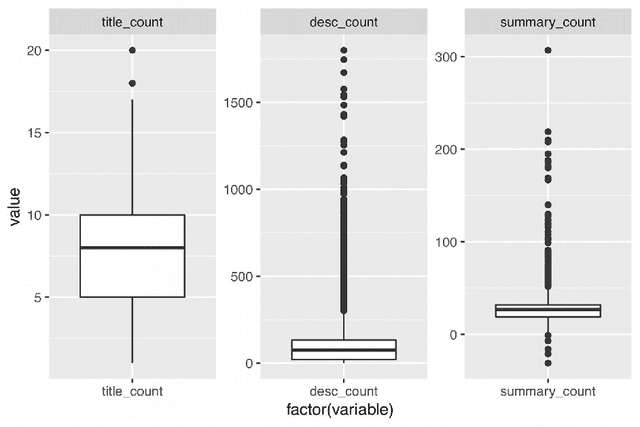
Hate speech is one type of harmful online content which directly attacks or promotes hate towards a group or an individual member based on their actual or perceived aspects of identity, such as ethnicity, religion, and sexual orientation. With online hate speech on the rise, its automatic detection as a natural language processing task is gaining increasing interest. However, it is only recently that it has been shown that existing models generalise poorly to unseen data. This survey paper attempts to summarise how generalisable existing hate speech detection models are, reason why hate speech models struggle to generalise, sums up existing attempts at addressing the main obstacles, and then proposes directions of future research to improve generalisation in hate speech detection.
An Online Multilingual Hate speech Recognition System
Dec 22, 2020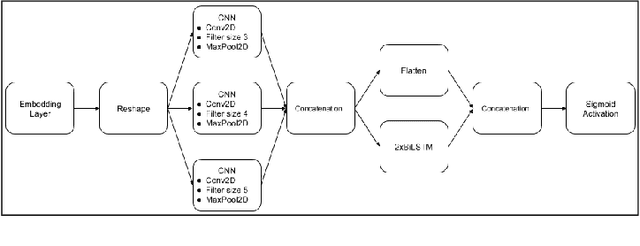
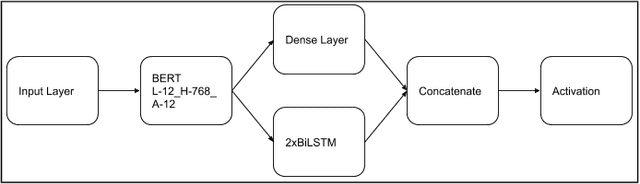

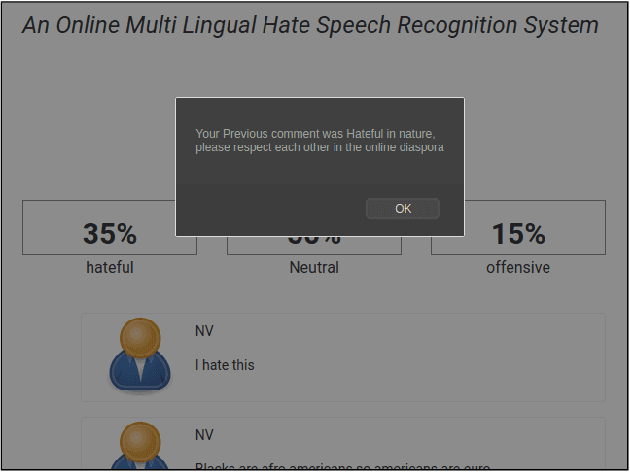
The exponential increase in the use of the Internet and social media over the last two decades has changed human interaction. This has led to many positive outcomes, but at the same time it has brought risks and harms. While the volume of harmful content online, such as hate speech, is not manageable by humans, interest in the academic community to investigate automated means for hate speech detection has increased. In this study, we analyse six publicly available datasets by combining them into a single homogeneous dataset and classify them into three classes, abusive, hateful or neither. We create a baseline model and we improve model performance scores using various optimisation techniques. After attaining a competitive performance score, we create a tool which identifies and scores a page with effective metric in near-real time and uses the same as feedback to re-train our model. We prove the competitive performance of our multilingual model on two langauges, English and Hindi, leading to comparable or superior performance to most monolingual models.
* 11 pages, 5 figures, appear in Special Issue "Natural Language Processing for Social Media" on MDPI Information 2021, 12(1), 5
TF-CR: Weighting Embeddings for Text Classification
Dec 11, 2020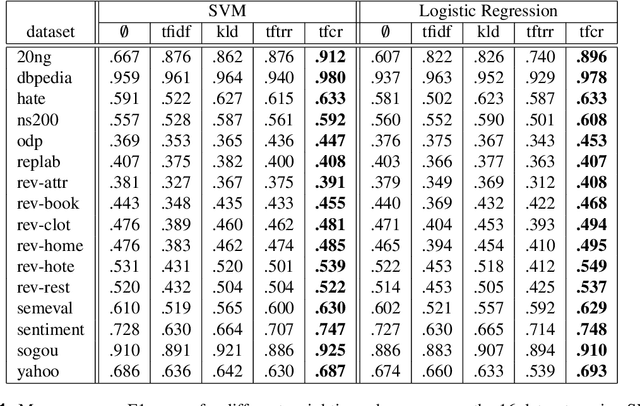
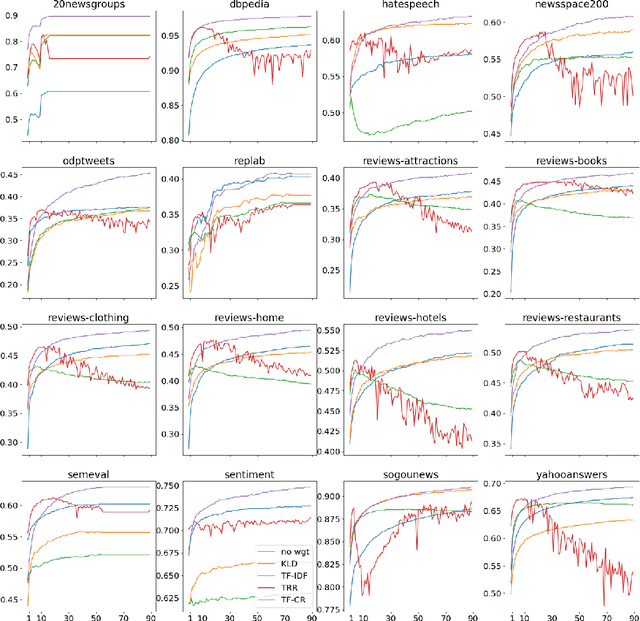
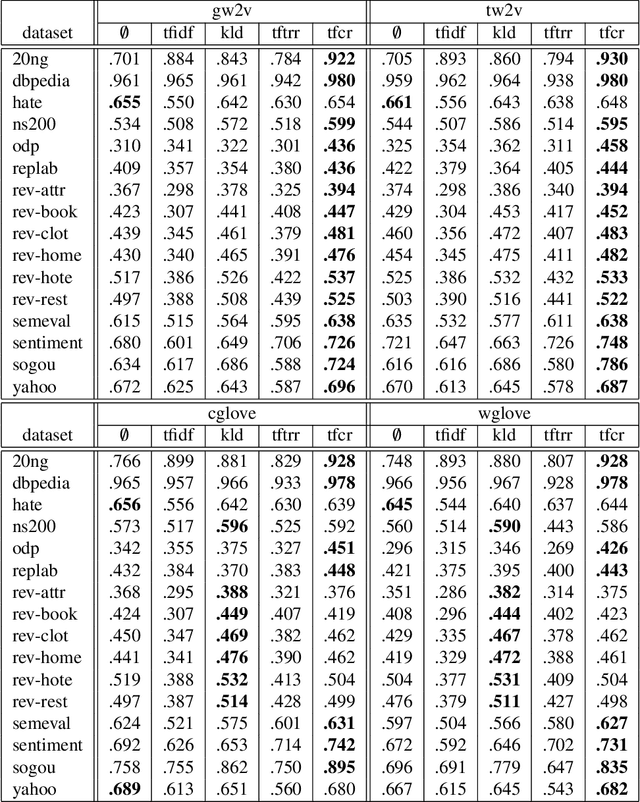
Text classification, as the task consisting in assigning categories to textual instances, is a very common task in information science. Methods learning distributed representations of words, such as word embeddings, have become popular in recent years as the features to use for text classification tasks. Despite the increasing use of word embeddings for text classification, these are generally used in an unsupervised manner, i.e. information derived from class labels in the training data are not exploited. While word embeddings inherently capture the distributional characteristics of words, and contexts observed around them in a large dataset, they aren't optimised to consider the distributions of words across categories in the classification dataset at hand. To optimise text representations based on word embeddings by incorporating class distributions in the training data, we propose the use of weighting schemes that assign a weight to embeddings of each word based on its saliency in each class. To achieve this, we introduce a novel weighting scheme, Term Frequency-Category Ratio (TF-CR), which can weight high-frequency, category-exclusive words higher when computing word embeddings. Our experiments on 16 classification datasets show the effectiveness of TF-CR, leading to improved performance scores over existing weighting schemes, with a performance gap that increases as the size of the training data grows.