 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Frontier on Approximate EFX Allocations
Jun 18, 2024We study the problem of allocating a set of indivisible goods to a set of agents with additive valuation functions, aiming to achieve approximate envy-freeness up to any good ($\alpha$-EFX). The state-of-the-art results on the problem include that (exact) EFX allocations exist when (a) there are at most three agents, or (b) the agents' valuation functions can take at most two values, or (c) the agents' valuation functions can be represented via a graph. For $\alpha$-EFX, it is known that a $0.618$-EFX allocation exists for any number of agents with additive valuation functions. In this paper, we show that $2/3$-EFX allocations exist when (a) there are at most \emph{seven agents}, (b) the agents' valuation functions can take at most \emph{three values}, or (c) the agents' valuation functions can be represented via a \emph{multigraph}. Our results can be interpreted in two ways. First, by relaxing the notion of EFX to $2/3$-EFX, we obtain existence results for strict generalizations of the settings for which exact EFX allocations are known to exist. Secondly, by imposing restrictions on the setting, we manage to beat the barrier of $0.618$ and achieve an approximation guarantee of $2/3$. Therefore, our results push the \emph{frontier} of existence and computation of approximate EFX allocations, and provide insights into the challenges of settling the existence of exact EFX allocations.
Achieving Diverse Objectives with AI-driven Prices in Deep Reinforcement Learning Multi-agent Markets
Jun 10, 2021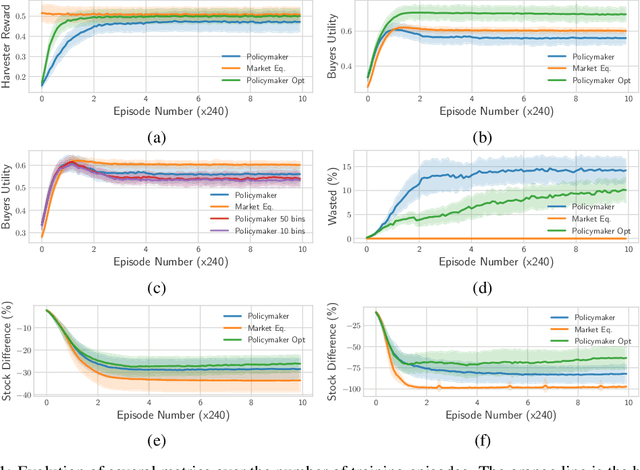
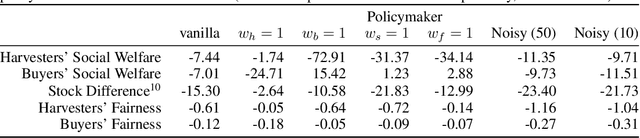

We propose a practical approach to computing market prices and allocations via a deep reinforcement learning policymaker agent, operating in an environment of other learning agents. Compared to the idealized market equilibrium outcome -- which we use as a benchmark -- our policymaker is much more flexible, allowing us to tune the prices with regard to diverse objectives such as sustainability and resource wastefulness, fairness, buyers' and sellers' welfare, etc. To evaluate our approach, we design a realistic market with multiple and diverse buyers and sellers. Additionally, the sellers, which are deep learning agents themselves, compete for resources in a common-pool appropriation environment based on bio-economic models of commercial fisheries. We demonstrate that: (a) The introduced policymaker is able to achieve comparable performance to the market equilibrium, showcasing the potential of such approaches in markets where the equilibrium prices can not be efficiently computed. (b) Our policymaker can notably outperform the equilibrium solution on certain metrics, while at the same time maintaining comparable performance for the remaining ones. (c) As a highlight of our findings, our policymaker is significantly more successful in maintaining resource sustainability, compared to the market outcome, in scarce resource environments.
Putting Ridesharing to the Test: Efficient and Scalable Solutions and the Power of Dynamic Vehicle Relocation
Feb 12, 2020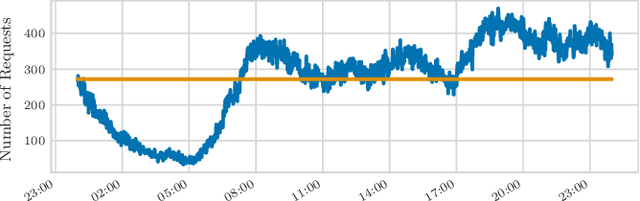
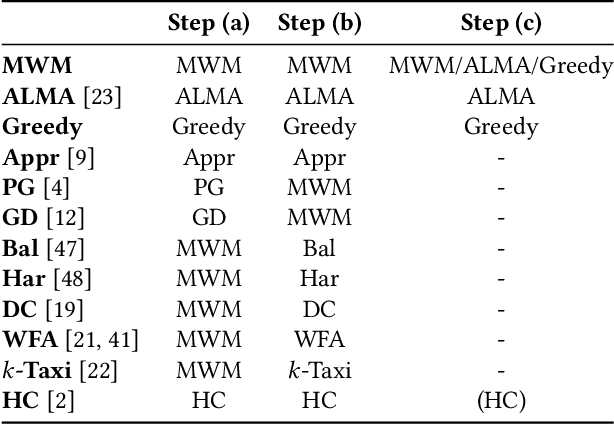
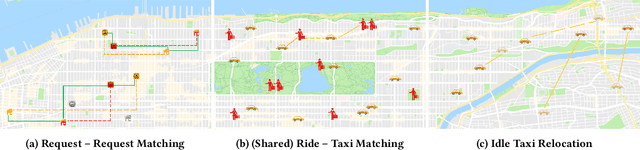
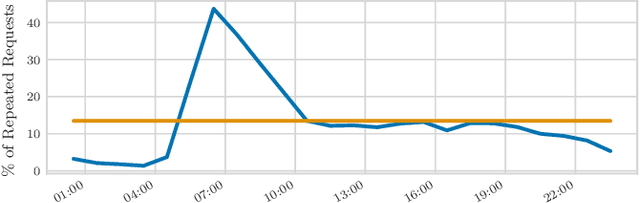
We perform a systematic evaluation of a diverse set of algorithms for the ridesharing problem which is, to the best of our knowledge, one of the largest and most comprehensive to date. In particular, we evaluate 12 different algorithms over 12 metrics related to global efficiency, complexity, passenger, driver, and platform incentives. Our evaluation setting is specifically designed to resemble reality as closely as possible. We achieve this by (a) using actual data from the NYC's yellow taxi trip records, both for modeling customer requests, and taxis (b) following closely the pricing model employed by ridesharing platforms and (c) running our simulations to the scale of the actual problem faced by the ridesharing platforms. Our results provide a clear-cut recommendation to ridesharing platforms on which solutions can be employed in practice and demonstrate the large potential for efficiency gains. Moreover, we show that simple, lightweight relocation schemes -- which can be used as independent components to any ridesharing algorithm -- can significantly improve Quality of Service metrics by up to 50%. As a highlight of our findings, we identify a scalable, on-device heuristic that offers an efficient, end-to-end solution for the Dynamic Ridesharing and Fleet Relocation problem.
Rewarding High-Quality Data via Influence Functions
Aug 30, 2019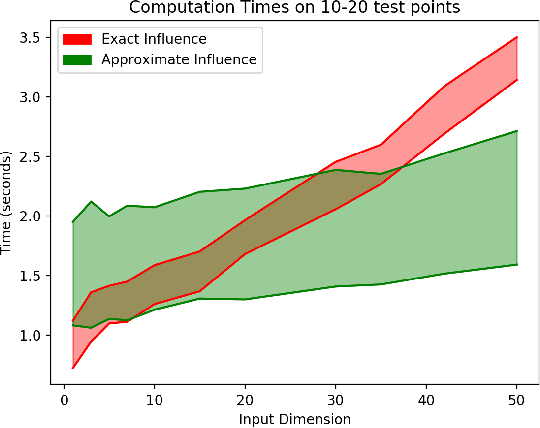
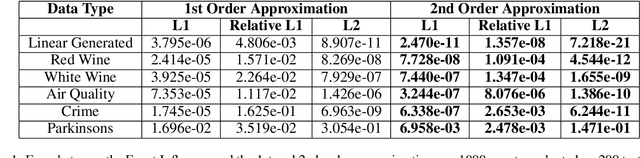
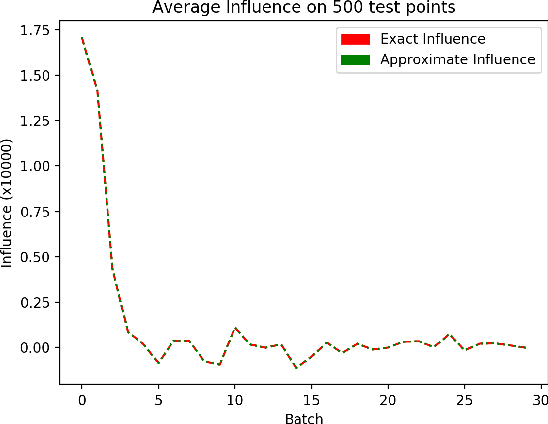
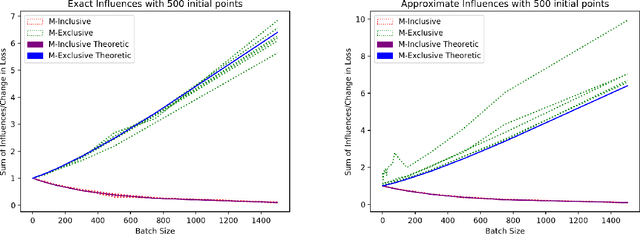
We consider a crowdsourcing data acquisition scenario, such as federated learning, where a Center collects data points from a set of rational Agents, with the aim of training a model. For linear regression models, we show how a payment structure can be designed to incentivize the agents to provide high-quality data as early as possible, based on a characterization of the influence that data points have on the loss function of the model. Our contributions can be summarized as follows: (a) we prove theoretically that this scheme ensures truthful data reporting as a game-theoretic equilibrium and further demonstrate its robustness against mixtures of truthful and heuristic data reports, (b) we design a procedure according to which the influence computation can be efficiently approximated and processed sequentially in batches over time, (c) we develop a theory that allows correcting the difference between the influence and the overall change in loss and (d) we evaluate our approach on real datasets, confirming our theoretical findings.
Anytime Heuristic for Weighted Matching Through Altruism-Inspired Behavior
Feb 25, 2019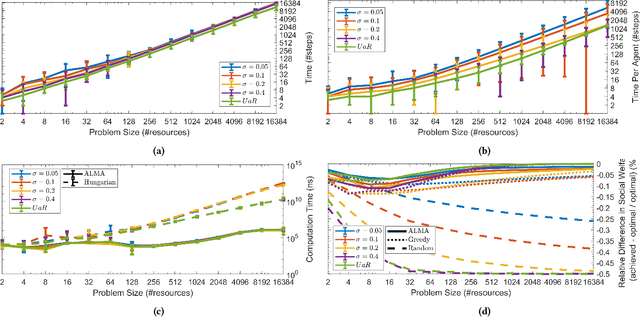

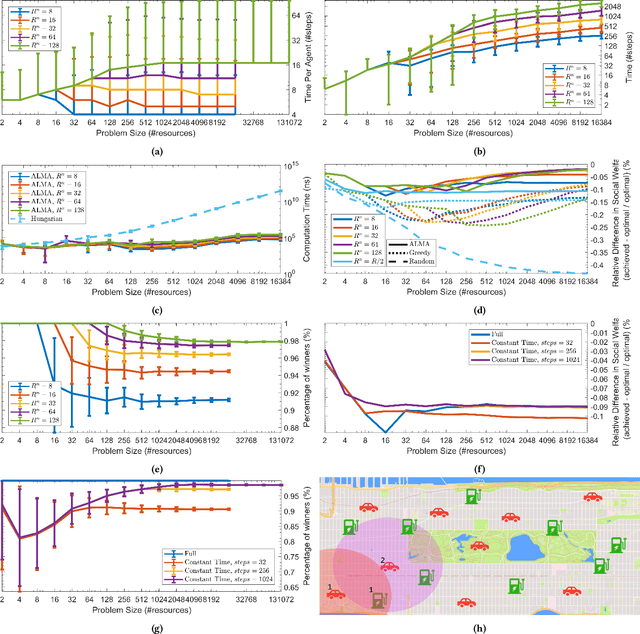
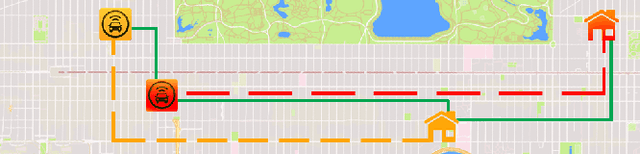
We present a novel anytime heuristic (ALMA), inspired by the human principle of altruism, for solving the assignment problem. ALMA is decentralized, completely uncoupled, and requires no communication between the participants. We prove an upper bound on the convergence speed that is polynomial in the desired number of resources and competing agents per resource; crucially, in the realistic case where the aforementioned quantities are bounded independently of the total number of agents/resources, the convergence time remains constant as the total problem size increases. We have evaluated ALMA under three test cases: (i) an anti-coordination scenario where agents with similar preferences compete over the same set of actions, (ii) a resource allocation scenario in an urban environment, under a constant-time constraint, and finally, (iii) an on-line matching scenario using real passenger-taxi data. In all of the cases, ALMA was able to reach high social welfare, while being orders of magnitude faster than the centralized, optimal algorithm. The latter allows our algorithm to scale to realistic scenarios with hundreds of thousands of agents, e.g., vehicle coordination in urban environments.
The Complexity of Splitting Necklaces and Bisecting Ham Sandwiches
Nov 05, 2018
We resolve the computational complexity of two problems known as NECKLACE-SPLITTING and DISCRETE HAM SANDWICH, showing that they are PPA-complete. For NECKLACE SPLITTING, this result is specific to the important special case in which two thieves share the necklace. We do this via a PPA-completeness result for an approximate version of the CONSENSUS-HALVING problem, strengthening our recent result that the problem is PPA-complete for inverse-exponential precision. At the heart of our construction is a smooth embedding of the high-dimensional M\"obius strip in the CONSENSUS-HALVING problem. These results settle the status of PPA as a class that captures the complexity of "natural" problems whose definitions do not incorporate a circuit.
Reinforcement Mechanism Design for e-commerce
Feb 27, 2018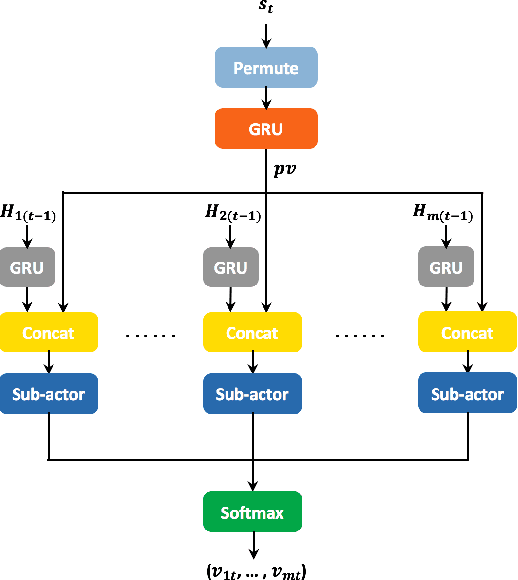
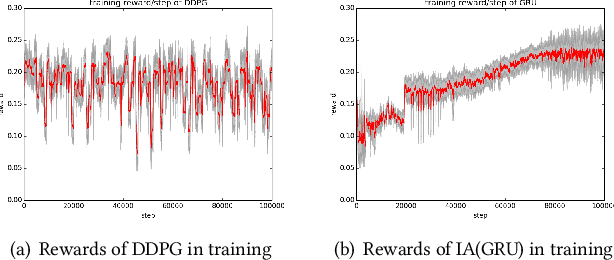
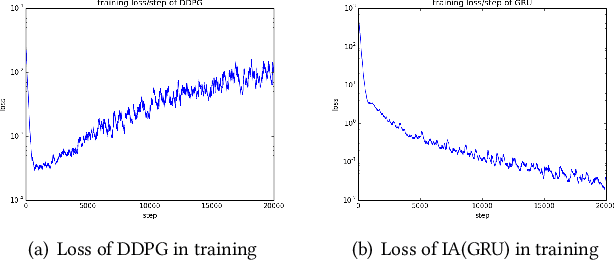
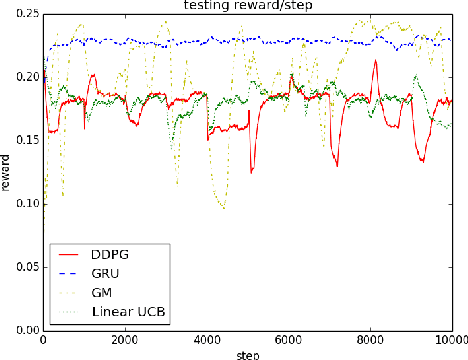
We study the problem of allocating impressions to sellers in e-commerce websites, such as Amazon, eBay or Taobao, aiming to maximize the total revenue generated by the platform. We employ a general framework of reinforcement mechanism design, which uses deep reinforcement learning to design efficient algorithms, taking the strategic behaviour of the sellers into account. Specifically, we model the impression allocation problem as a Markov decision process, where the states encode the history of impressions, prices, transactions and generated revenue and the actions are the possible impression allocations in each round. To tackle the problem of continuity and high-dimensionality of states and actions, we adopt the ideas of the DDPG algorithm to design an actor-critic policy gradient algorithm which takes advantage of the problem domain in order to achieve convergence and stability. We evaluate our proposed algorithm, coined IA(GRU), by comparing it against DDPG, as well as several natural heuristics, under different rationality models for the sellers - we assume that sellers follow well-known no-regret type strategies which may vary in their degree of sophistication. We find that IA(GRU) outperforms all algorithms in terms of the total revenue.