 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBypassing the Ambient Dimension: Private SGD with Gradient Subspace Identification
Jul 07, 2020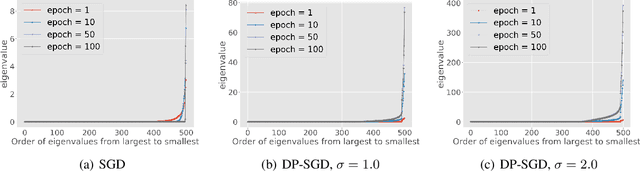
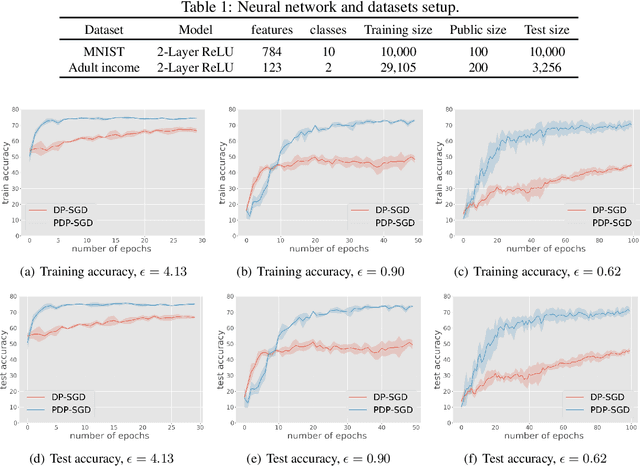
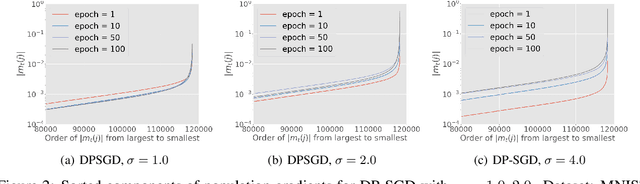
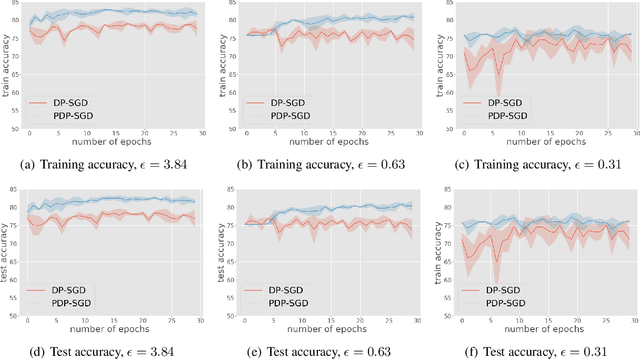
Differentially private SGD (DP-SGD) is one of the most popular methods for solving differentially private empirical risk minimization (ERM). Due to its noisy perturbation on each gradient update, the error rate of DP-SGD scales with the ambient dimension $p$, the number of parameters in the model. Such dependence can be problematic for over-parameterized models where $p \gg n$, the number of training samples. Existing lower bounds on private ERM show that such dependence on $p$ is inevitable in the worst case. In this paper, we circumvent the dependence on the ambient dimension by leveraging a low-dimensional structure of gradient space in deep networks---that is, the stochastic gradients for deep nets usually stay in a low dimensional subspace in the training process. We propose Projected DP-SGD that performs noise reduction by projecting the noisy gradients to a low-dimensional subspace, which is given by the top gradient eigenspace on a small public dataset. We provide a general sample complexity analysis on the public dataset for the gradient subspace identification problem and demonstrate that under certain low-dimensional assumptions the public sample complexity only grows logarithmically in $p$. Finally, we provide a theoretical analysis and empirical evaluations to show that our method can substantially improve the accuracy of DP-SGD.
Sub-Seasonal Climate Forecasting via Machine Learning: Challenges, Analysis, and Advances
Jun 24, 2020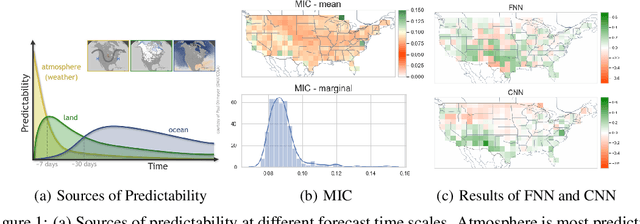
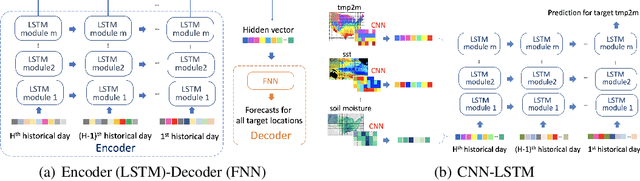
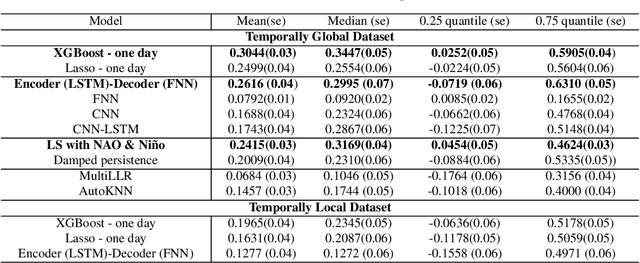
Sub-seasonal climate forecasting (SSF) focuses on predicting key climate variables such as temperature and precipitation in the 2-week to 2-month time scales. Skillful SSF would have immense societal value, in areas such as agricultural productivity, water resource management, transportation and aviation systems, and emergency planning for extreme weather events. However, SSF is considered more challenging than either weather prediction or even seasonal prediction. In this paper, we carefully study a variety of machine learning (ML) approaches for SSF over the US mainland. While atmosphere-land-ocean couplings and the limited amount of good quality data makes it hard to apply black-box ML naively, we show that with carefully constructed feature representations, even linear regression models, e.g., Lasso, can be made to perform well. Among a broad suite of 10 ML approaches considered, gradient boosting performs the best, and deep learning (DL) methods show some promise with careful architecture choices. Overall, suitable ML methods are able to outperform the climatological baseline, i.e., predictions based on the 30-year average at a given location and time. Further, based on studying feature importance, ocean (especially indices based on climatic oscillations such as El Nino) and land (soil moisture) covariates are found to be predictive, whereas atmospheric covariates are not considered helpful.
Private Stochastic Non-Convex Optimization: Adaptive Algorithms and Tighter Generalization Bounds
Jun 24, 2020
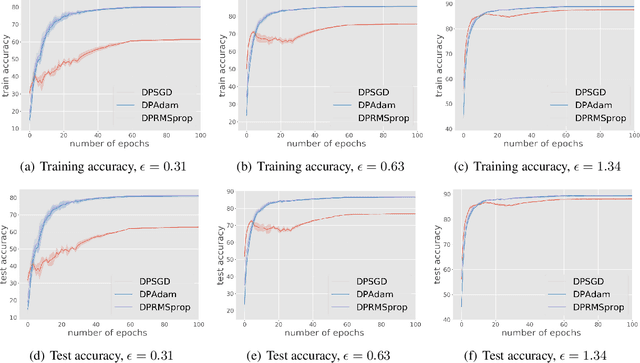

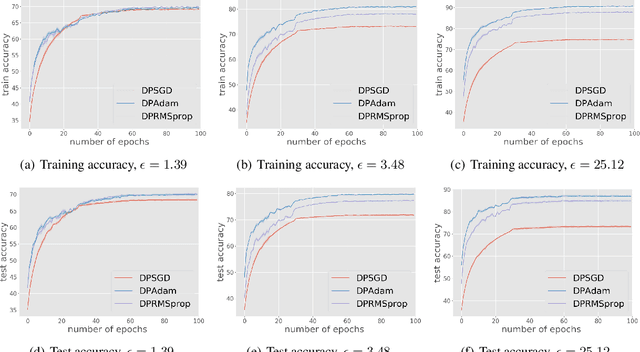
We study differentially private (DP) algorithms for stochastic non-convex optimization. In this problem, the goal is to minimize the population loss over a $p$-dimensional space given $n$ i.i.d. samples drawn from a distribution. We improve upon the population gradient bound of ${\sqrt{p}}/{\sqrt{n}}$ from prior work and obtain a sharper rate of $\sqrt[4]{p}/\sqrt{n}$. We obtain this rate by providing the first analyses on a collection of private gradient-based methods, including adaptive algorithms DP RMSProp and DP Adam. Our proof technique leverages the connection between differential privacy and adaptive data analysis to bound gradient estimation error at every iterate, which circumvents the worse generalization bound from the standard uniform convergence argument. Finally, we evaluate the proposed algorithms on two popular deep learning tasks and demonstrate the empirical advantages of DP adaptive gradient methods over standard DP SGD.
Gradient Boosted Flows
Feb 27, 2020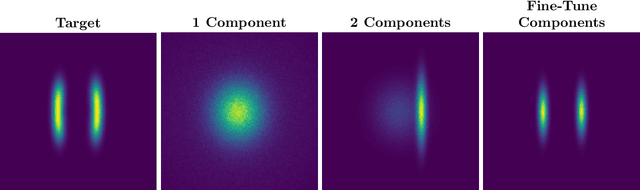
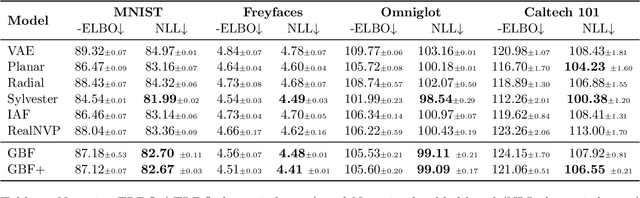
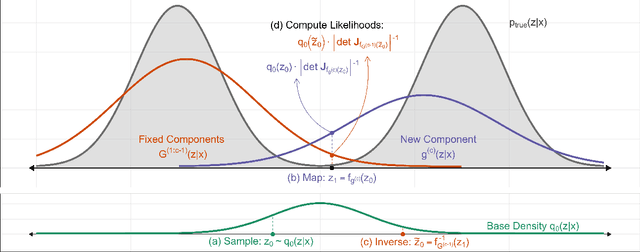
Normalizing flows (NF) are a powerful framework for approximating posteriors. By mapping a simple base density through invertible transformations, flows provide an exact method of density evaluation and sampling. The trend in normalizing flow literature has been to devise deeper, more complex transformations to achieve greater flexibility. We propose an alternative: Gradient Boosted Flows (GBF) model a variational posterior by successively adding new NF components by gradient boosting so that each new NF component is fit to the residuals of the previously trained components. The GBF formulation results in a variational posterior that is a mixture model, whose flexibility increases as more components are added. Moreover, GBFs offer a wider, not deeper, approach that can be incorporated to improve the results of many existing NFs. We demonstrate the effectiveness of this technique for density estimation and, by coupling GBF with a variational autoencoder, generative modeling of images.
Structured Linear Contextual Bandits: A Sharp and Geometric Smoothed Analysis
Feb 26, 2020Bandit learning algorithms typically involve the balance of exploration and exploitation. However, in many practical applications, worst-case scenarios needing systematic exploration are seldom encountered. In this work, we consider a smoothed setting for structured linear contextual bandits where the adversarial contexts are perturbed by Gaussian noise and the unknown parameter $\theta^*$ has structure, e.g., sparsity, group sparsity, low rank, etc. We propose simple greedy algorithms for both the single- and multi-parameter (i.e., different parameter for each context) settings and provide a unified regret analysis for $\theta^*$ with any assumed structure. The regret bounds are expressed in terms of geometric quantities such as Gaussian widths associated with the structure of $\theta^*$. We also obtain sharper regret bounds compared to earlier work for the unstructured $\theta^*$ setting as a consequence of our improved analysis. We show there is implicit exploration in the smoothed setting where a simple greedy algorithm works.
De-randomized PAC-Bayes Margin Bounds: Applications to Non-convex and Non-smooth Predictors
Feb 23, 2020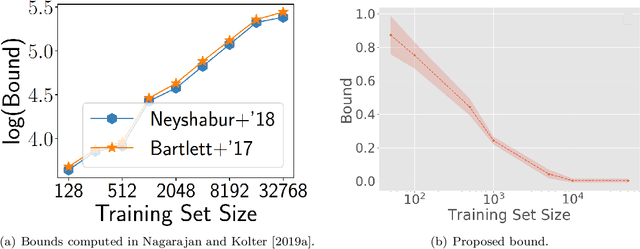
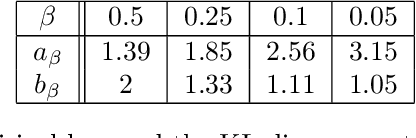
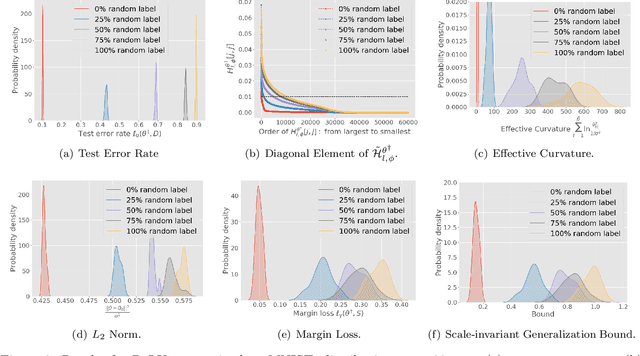
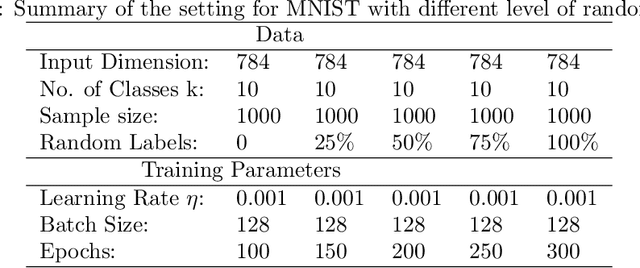
In spite of several notable efforts, explaining the generalization of deterministic deep nets, e.g., ReLU-nets, has remained challenging. Existing approaches usually need to bound the Lipschitz constant of such deep nets but such bounds have been shown to increase substantially with the number of training samples yielding vacuous generalization bounds [Nagarajan and Kolter, 2019a]. In this paper, we present new de-randomized PAC-Bayes margin bounds for deterministic non-convex and non-smooth predictors, e.g., ReLU-nets. The bounds depend on a trade-off between the $L_2$-norm of the weights and the effective curvature (`flatness') of the predictor, avoids any dependency on the Lipschitz constant, and yield meaningful (decreasing) bounds with increase in training set size. Our analysis first develops a de-randomization argument for non-convex but smooth predictors, e.g., linear deep networks (LDNs). We then consider non-smooth predictors which for any given input realize as a smooth predictor, e.g., ReLU-nets become some LDN for a given input, but the realized smooth predictor can be different for different inputs. For such non-smooth predictors, we introduce a new PAC-Bayes analysis that maintains distributions over the structure as well as parameters of smooth predictors, e.g., LDNs corresponding to ReLU-nets, which after de-randomization yields a bound for the deterministic non-smooth predictor. We present empirical results to illustrate the efficacy of our bounds over changing training set size and randomness in labels.
Random Quadratic Forms with Dependence: Applications to Restricted Isometry and Beyond
Oct 11, 2019
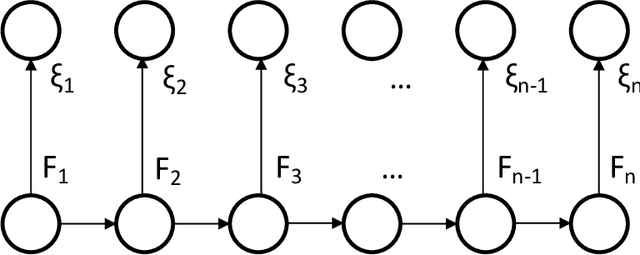
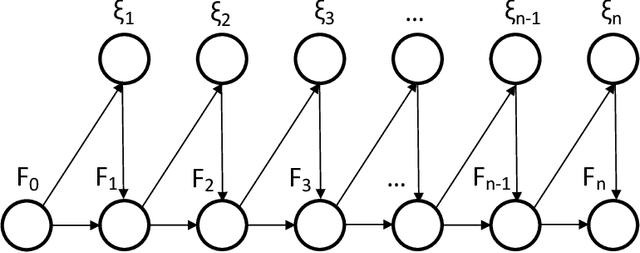
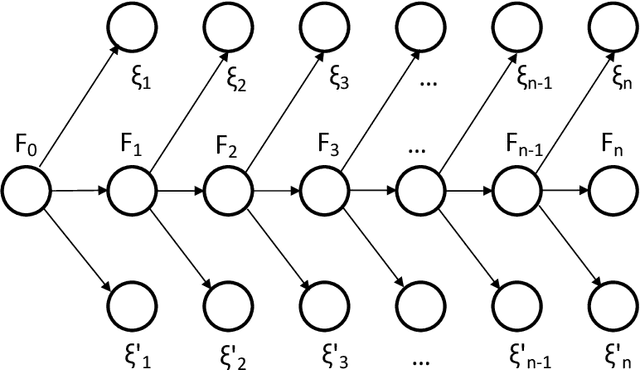
Several important families of computational and statistical results in machine learning and randomized algorithms rely on uniform bounds on quadratic forms of random vectors or matrices. Such results include the Johnson-Lindenstrauss (J-L) Lemma, the Restricted Isometry Property (RIP), randomized sketching algorithms, and approximate linear algebra. The existing results critically depend on statistical independence, e.g., independent entries for random vectors, independent rows for random matrices, etc., which prevent their usage in dependent or adaptive modeling settings. In this paper, we show that such independence is in fact not needed for such results which continue to hold under fairly general dependence structures. In particular, we present uniform bounds on random quadratic forms of stochastic processes which are conditionally independent and sub-Gaussian given another (latent) process. Our setup allows general dependencies of the stochastic process on the history of the latent process and the latent process to be influenced by realizations of the stochastic process. The results are thus applicable to adaptive modeling settings and also allows for sequential design of random vectors and matrices. We also discuss stochastic process based forms of J-L, RIP, and sketching, to illustrate the generality of the results.
Hessian based analysis of SGD for Deep Nets: Dynamics and Generalization
Jul 24, 2019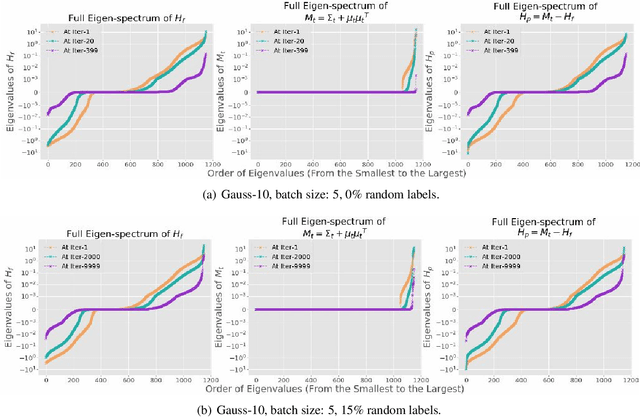
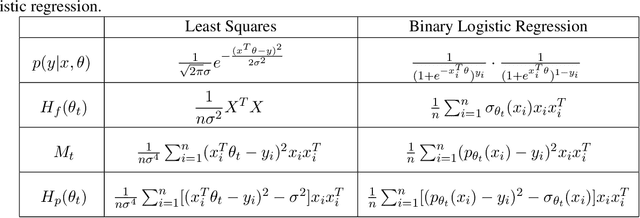
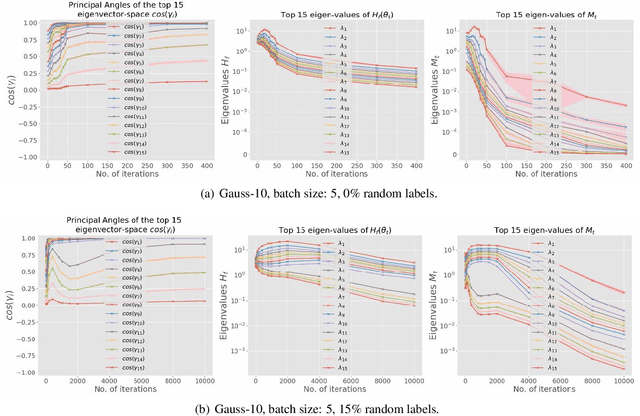
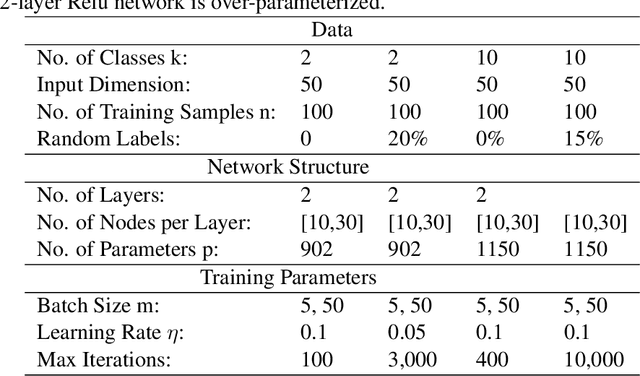
While stochastic gradient descent (SGD) and variants have been surprisingly successful for training deep nets, several aspects of the optimization dynamics and generalization are still not well understood. In this paper, we present new empirical observations and theoretical results on both the optimization dynamics and generalization behavior of SGD for deep nets based on the Hessian of the training loss and associated quantities. We consider three specific research questions: (1) what is the relationship between the Hessian of the loss and the second moment of stochastic gradients (SGs)? (2) how can we characterize the stochastic optimization dynamics of SGD with fixed and adaptive step sizes and diagonal pre-conditioning based on the first and second moments of SGs? and (3) how can we characterize a scale-invariant generalization bound of deep nets based on the Hessian of the loss, which by itself is not scale invariant? We shed light on these three questions using theoretical results supported by extensive empirical observations, with experiments on synthetic data, MNIST, and CIFAR-10, with different batch sizes, and with different difficulty levels by synthetically adding random labels.
Two-block vs. Multi-block ADMM: An empirical evaluation of convergence
Jul 10, 2019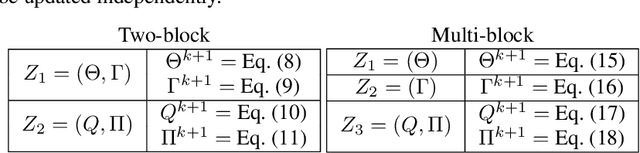
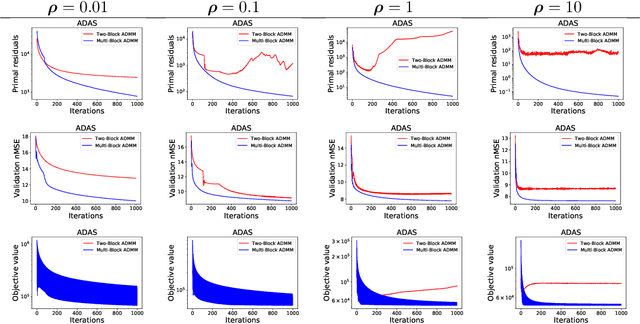

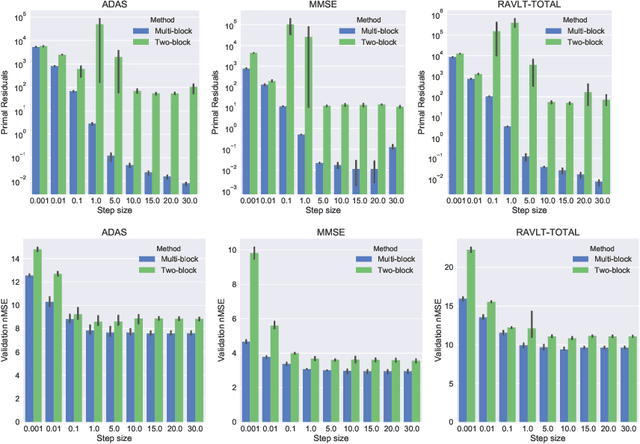
Alternating Direction Method of Multipliers (ADMM) has become a widely used optimization method for convex problems, particularly in the context of data mining in which large optimization problems are often encountered. ADMM has several desirable properties, including the ability to decompose large problems into smaller tractable sub-problems and ease of parallelization, that are essential in these scenarios. The most common form of ADMM is the two-block, in which two sets of primal variables are updated alternatingly. Recent years have seen advances in multi-block ADMM, which update more than two blocks of primal variables sequentially. In this paper, we study the empirical question: {\em Is two-block ADMM always comparable with sequential multi-block ADMM solving an equivalent problem?} In the context of optimization problems arising in multi-task learning, through a comprehensive set of experiments we surprisingly show that multi-block ADMM consistently outperformed two-block ADMM on optimization performance, and as a consequence on prediction performance, across all datasets and for the entire range of dual step sizes. Our results have an important practical implication: rather than simply using the popular two-block ADMM, one may considerably benefit from experimenting with multi-block ADMM applied to an equivalent problem.
DAPPER: Scaling Dynamic Author Persona Topic Model to Billion Word Corpora
Nov 03, 2018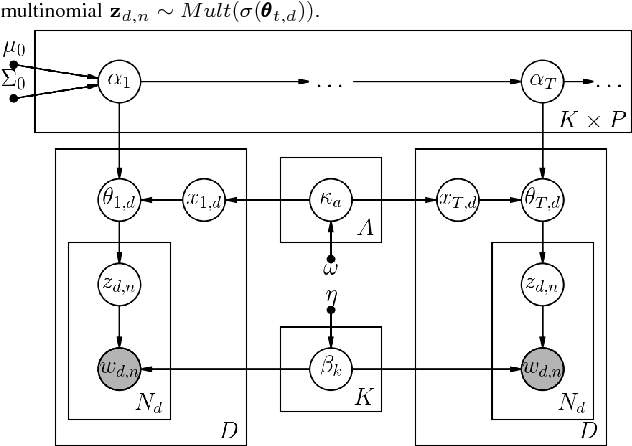
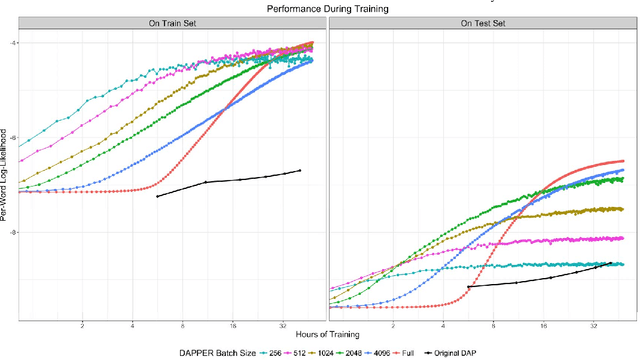
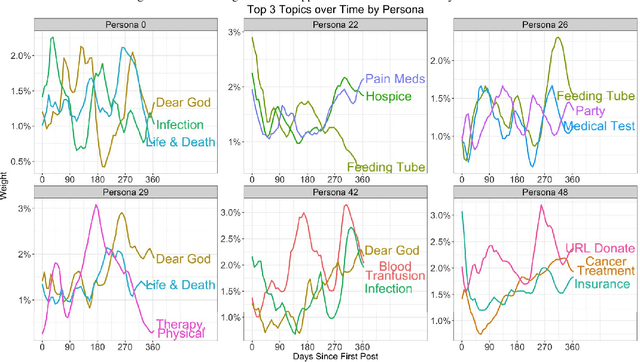
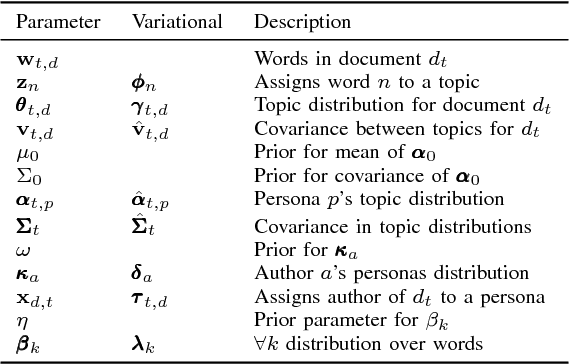
Extracting common narratives from multi-author dynamic text corpora requires complex models, such as the Dynamic Author Persona (DAP) topic model. However, such models are complex and can struggle to scale to large corpora, often because of challenging non-conjugate terms. To overcome such challenges, in this paper we adapt new ideas in approximate inference to the DAP model, resulting in the DAP Performed Exceedingly Rapidly (DAPPER) topic model. Specifically, we develop Conjugate-Computation Variational Inference (CVI) based variational Expectation-Maximization (EM) for learning the model, yielding fast, closed form updates for each document, replacing iterative optimization in earlier work. Our results show significant improvements in model fit and training time without needing to compromise the model's temporal structure or the application of Regularized Variation Inference (RVI). We demonstrate the scalability and effectiveness of the DAPPER model by extracting health journeys from the CaringBridge corpus --- a collection of 9 million journals written by 200,000 authors during health crises.