 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVectorized Adaptive Histograms for Sparse Oblique Forests
Feb 27, 2026Classification using sparse oblique random forests provides guarantees on uncertainty and confidence while controlling for specific error types. However, they use more data and more compute than other tree ensembles because they create deep trees and need to sort or histogram linear combinations of data at runtime. We provide a method for dynamically switching between histograms and sorting to find the best split. We further optimize histogram construction using vector intrinsics. Evaluating this on large datasets, our optimizations speedup training by 1.7-2.5x compared to existing oblique forests and 1.5-2x compared to standard random forests. We also provide a GPU and hybrid CPU-GPU implementation.
Auditing Significance, Metric Choice, and Demographic Fairness in Medical AI Challenges
Dec 22, 2025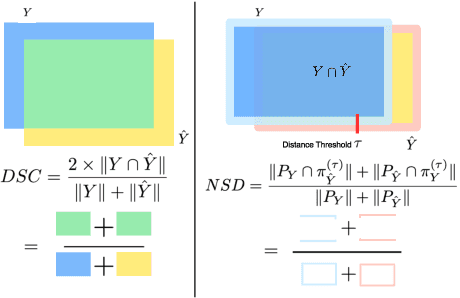
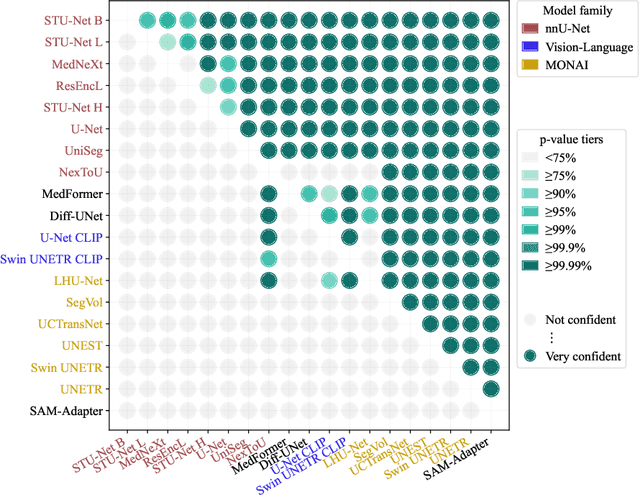
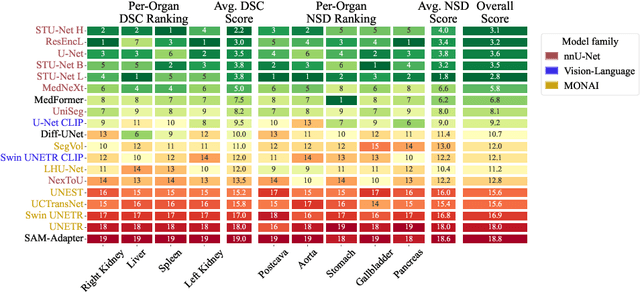
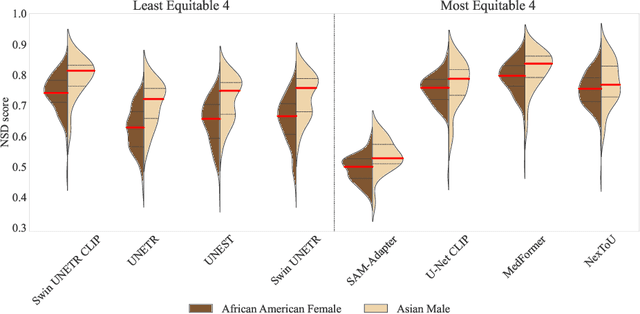
Open challenges have become the de facto standard for comparative ranking of medical AI methods. Despite their importance, medical AI leaderboards exhibit three persistent limitations: (1) score gaps are rarely tested for statistical significance, so rank stability is unknown; (2) single averaged metrics are applied to every organ, hiding clinically important boundary errors; (3) performance across intersecting demographics is seldom reported, masking fairness and equity gaps. We introduce RankInsight, an open-source toolkit that seeks to address these limitations. RankInsight (1) computes pair-wise significance maps that show the nnU-Net family outperforms Vision-Language and MONAI submissions with high statistical certainty; (2) recomputes leaderboards with organ-appropriate metrics, reversing the order of the top four models when Dice is replaced by NSD for tubular structures; and (3) audits intersectional fairness, revealing that more than half of the MONAI-based entries have the largest gender-race discrepancy on our proprietary Johns Hopkins Hospital dataset. The RankInsight toolkit is publicly released and can be directly applied to past, ongoing, and future challenges. It enables organizers and participants to publish rankings that are statistically sound, clinically meaningful, and demographically fair.
Edge-Parallel Graph Encoder Embedding
Feb 06, 2024



New algorithms for embedding graphs have reduced the asymptotic complexity of finding low-dimensional representations. One-Hot Graph Encoder Embedding (GEE) uses a single, linear pass over edges and produces an embedding that converges asymptotically to the spectral embedding. The scaling and performance benefits of this approach have been limited by a serial implementation in an interpreted language. We refactor GEE into a parallel program in the Ligra graph engine that maps functions over the edges of the graph and uses lock-free atomic instrutions to prevent data races. On a graph with 1.8B edges, this results in a 500 times speedup over the original implementation and a 17 times speedup over a just-in-time compiled version.