 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Dynamical Systems using Local Stability Priors
Aug 23, 2020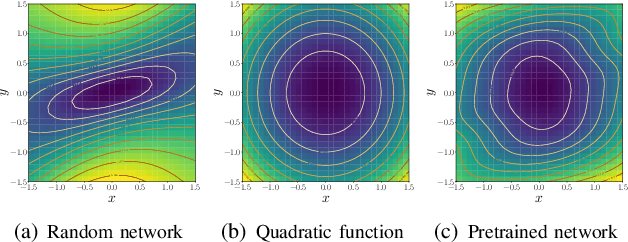
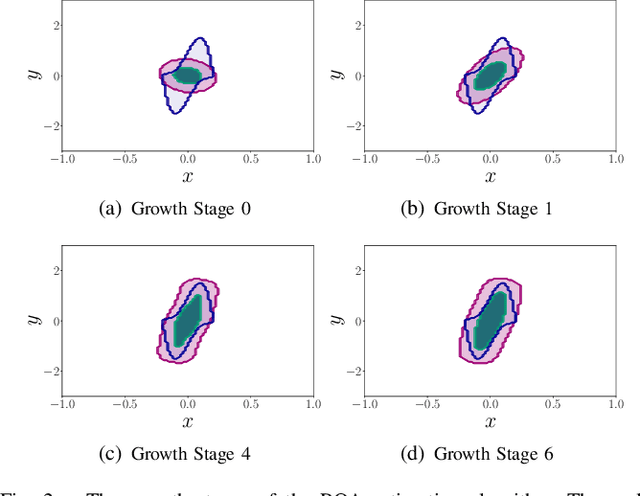
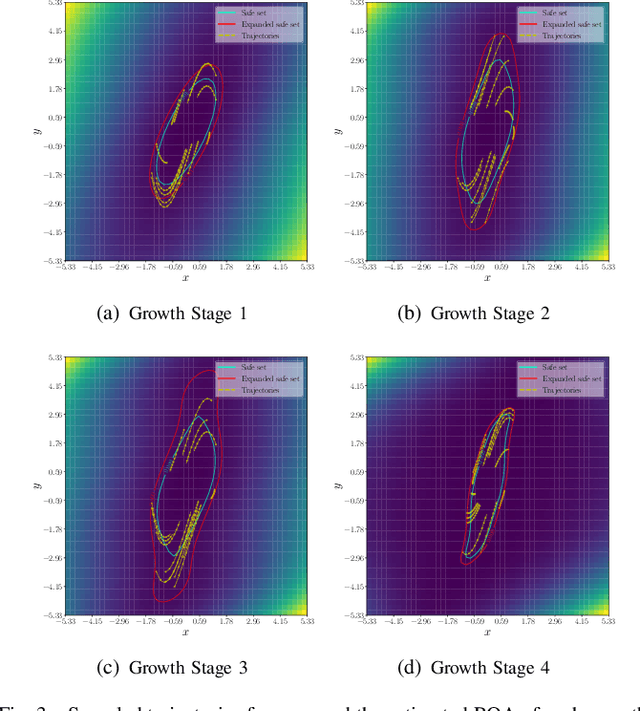
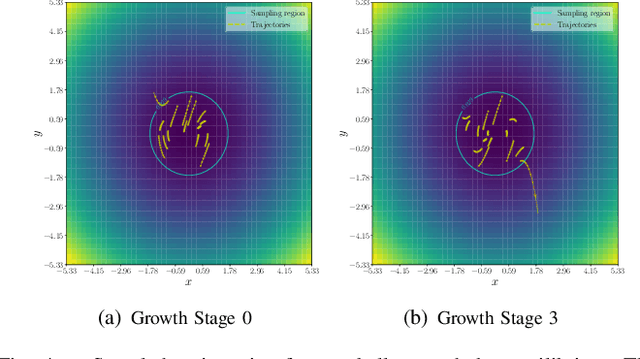
A coupled computational approach to simultaneously learn a vector field and the region of attraction of an equilibrium point from generated trajectories of the system is proposed. The nonlinear identification leverages the local stability information as a prior on the system, effectively endowing the estimate with this important structural property. In addition, the knowledge of the region of attraction plays an experiment design role by informing the selection of initial conditions from which trajectories are generated and by enabling the use of a Lyapunov function of the system as a regularization term. Numerical results show that the proposed method allows efficient sampling and provides an accurate estimate of the dynamics in an inner approximation of its region of attraction.
Automatic Policy Synthesis to Improve the Safety of Nonlinear Dynamical Systems
Jun 06, 2020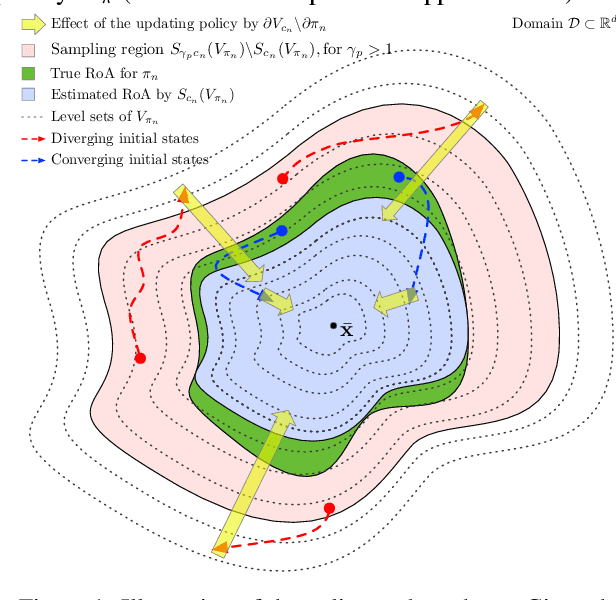
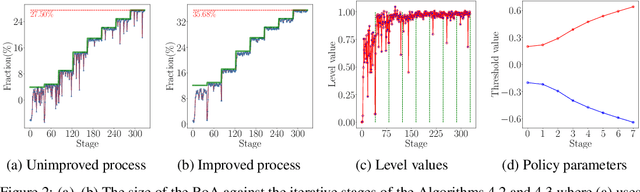
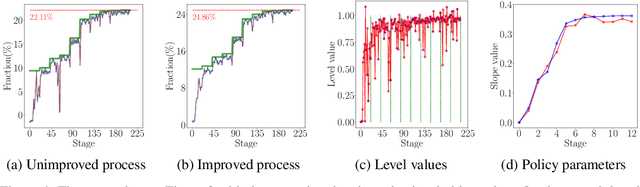
Learning controllers merely based on a performance metric has been proven effective in many physical and non-physical tasks in both control theory and reinforcement learning. However, in practice, the controller must guarantee some notion of safety to ensure that it does not harm either the agent or the environment. Stability is a crucial notion of safety, whose violation can certainly cause unsafe behaviors. Lyapunov functions are effective tools to assess stability in nonlinear dynamical systems. In this paper, we combine an improving Lyapunov function with automatic controller synthesis to obtain control policies with large safe regions. We propose a two-player collaborative algorithm that alternates between estimating a Lyapunov function and deriving a controller that gradually enlarges the stability region of the closed-loop system. We provide theoretical results on the class of systems that can be treated with the proposed algorithm and empirically evaluate the effectiveness of our method using an exemplary dynamical system.
Kernel-Guided Training of Implicit Generative Models with Stability Guarantees
Nov 03, 2019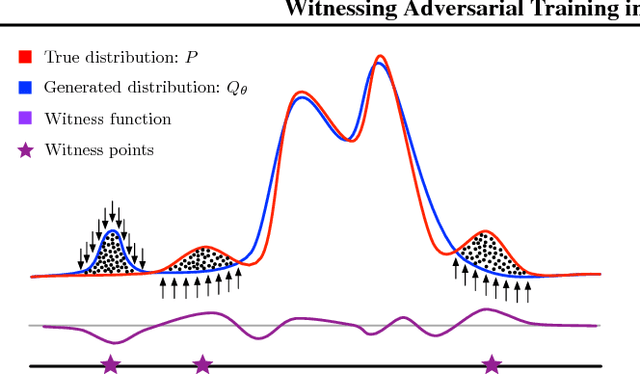
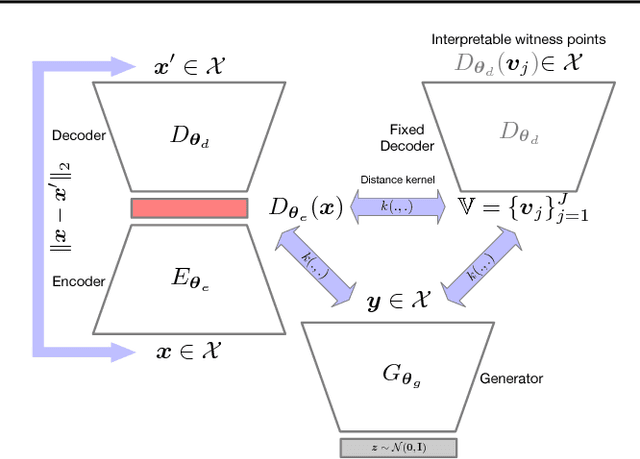
Modern implicit generative models such as generative adversarial networks (GANs) are generally known to suffer from issues such as instability, uninterpretability, and difficulty in assessing their performance. If we see these implicit models as dynamical systems, some of these issues are caused by being unable to control their behavior in a meaningful way during the course of training. In this work, we propose a theoretically grounded method to guide the training trajectories of GANs by augmenting the GAN loss function with a kernel-based regularization term that controls local and global discrepancies between the model and true distributions. This control signal allows us to inject prior knowledge into the model. We provide theoretical guarantees on the stability of the resulting dynamical system and demonstrate different aspects of it via a wide range of experiments.
Dual IV: A Single Stage Instrumental Variable Regression
Oct 27, 2019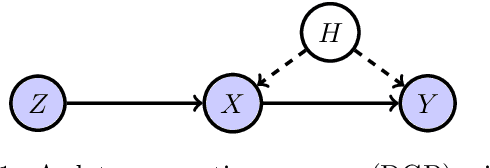
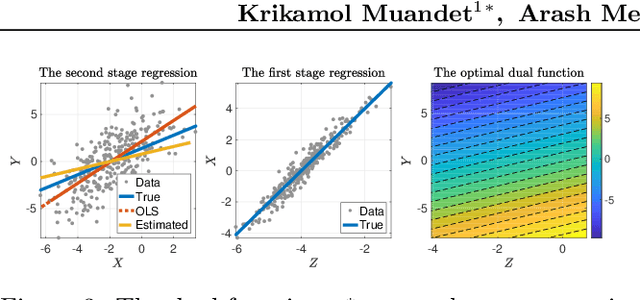
We present a novel single-stage procedure for instrumental variable (IV) regression called DualIV which simplifies traditional two-stage regression via a dual formulation. We show that the common two-stage procedure can alternatively be solved via generalized least squares. Our formulation circumvents the first-stage regression which can be a bottleneck in modern two-stage procedures for IV regression. We also show that our framework is closely related to the generalized method of moments (GMM) with specific assumptions. This highlights the fundamental connection between GMM and two-stage procedures in IV literature. Using the proposed framework, we develop a simple kernel-based algorithm with consistency guarantees. Lastly, we give empirical results illustrating the advantages of our method over the existing two-stage algorithms.
The Incomplete Rosetta Stone Problem: Identifiability Results for Multi-View Nonlinear ICA
May 16, 2019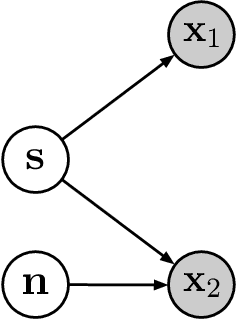
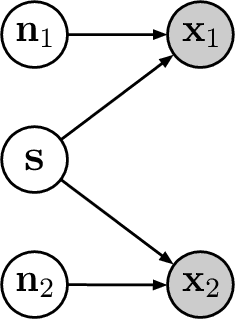
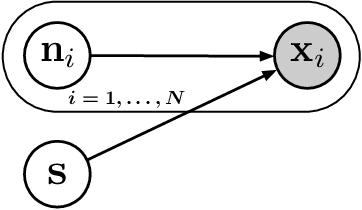

We consider the problem of recovering a common latent source with independent components from multiple views. This applies to settings in which a variable is measured with multiple experimental modalities, and where the goal is to synthesize the disparate measurements into a single unified representation. We consider the case that the observed views are a nonlinear mixing of component-wise corruptions of the sources. When the views are considered separately, this reduces to nonlinear Independent Component Analysis (ICA) for which it is provably impossible to undo the mixing. We present novel identifiability proofs that this is possible when the multiple views are considered jointly, showing that the mixing can theoretically be undone using function approximators such as deep neural networks. In contrast to known identifiability results for nonlinear ICA, we prove that independent latent sources with arbitrary mixing can be recovered as long as multiple, sufficiently different noisy views are available.
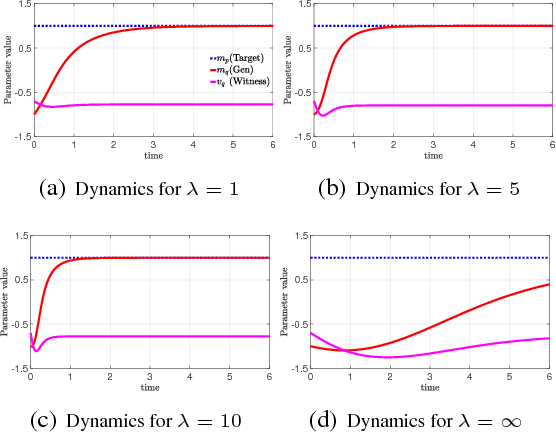
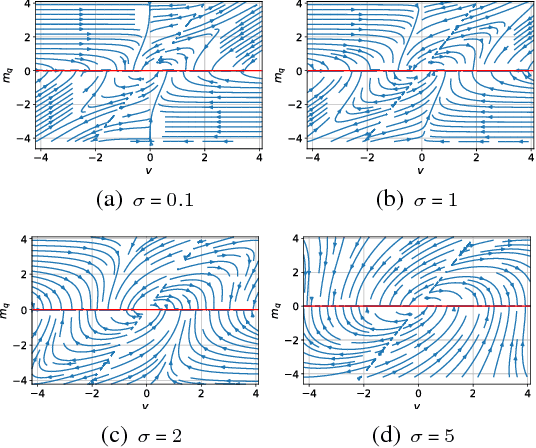
Witnessing Adversarial Training in Reproducing Kernel Hilbert Spaces
Jan 26, 2019Modern implicit generative models such as generative adversarial networks (GANs) are generally known to suffer from instability and lack of interpretability as it is difficult to diagnose what aspects of the target distribution are missed by the generative model. In this work, we propose a theoretically grounded solution to these issues by augmenting the GAN's loss function with a kernel-based regularization term that magnifies local discrepancy between the distributions of generated and real samples. The proposed method relies on so-called witness points in the data space which are jointly trained with the generator and provide an interpretable indication of where the two distributions locally differ during the training procedure. In addition, the proposed algorithm is scaled to higher dimensions by learning the witness locations in a latent space of an autoencoder. We theoretically investigate the dynamics of the training procedure, prove that a desirable equilibrium point exists, and the dynamical system is locally stable around this equilibrium. Finally, we demonstrate different aspects of the proposed algorithm by numerical simulations of analytical solutions and empirical results for low and high-dimensional datasets.
Deep Nonlinear Non-Gaussian Filtering for Dynamical Systems
Nov 14, 2018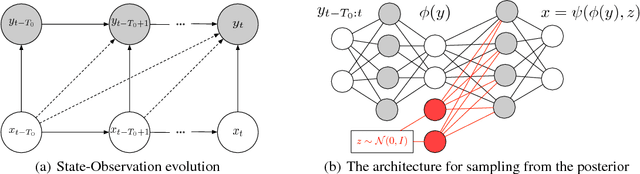
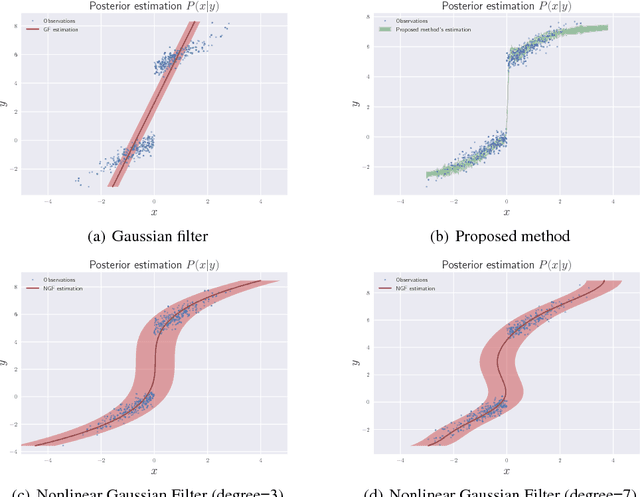
Filtering is a general name for inferring the states of a dynamical system given observations. The most common filtering approach is Gaussian Filtering (GF) where the distribution of the inferred states is a Gaussian whose mean is an affine function of the observations. There are two restrictions in this model: Gaussianity and Affinity. We propose a model to relax both these assumptions based on recent advances in implicit generative models. Empirical results show that the proposed method gives a significant advantage over GF and nonlinear methods based on fixed nonlinear kernels.
Tempered Adversarial Networks
Jul 11, 2018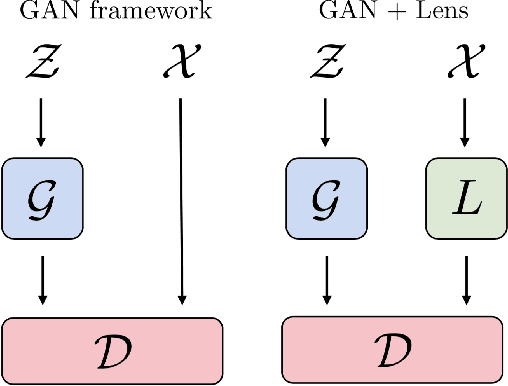
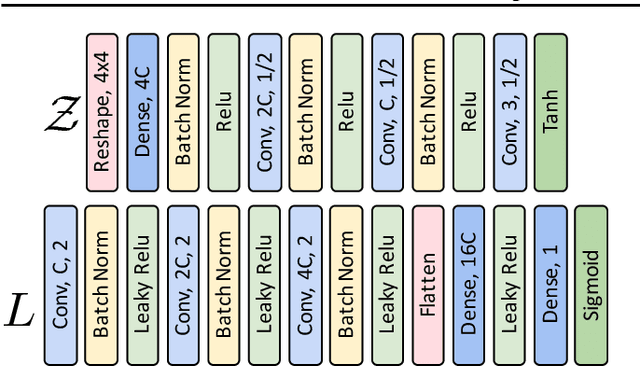
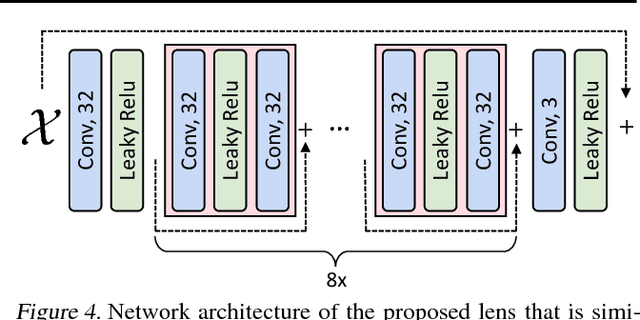
Generative adversarial networks (GANs) have been shown to produce realistic samples from high-dimensional distributions, but training them is considered hard. A possible explanation for training instabilities is the inherent imbalance between the networks: While the discriminator is trained directly on both real and fake samples, the generator only has control over the fake samples it produces since the real data distribution is fixed by the choice of a given dataset. We propose a simple modification that gives the generator control over the real samples which leads to a tempered learning process for both generator and discriminator. The real data distribution passes through a lens before being revealed to the discriminator, balancing the generator and discriminator by gradually revealing more detailed features necessary to produce high-quality results. The proposed module automatically adjusts the learning process to the current strength of the networks, yet is generic and easy to add to any GAN variant. In a number of experiments, we show that this can improve quality, stability and/or convergence speed across a range of different GAN architectures (DCGAN, LSGAN, WGAN-GP).
A Local Information Criterion for Dynamical Systems
May 27, 2018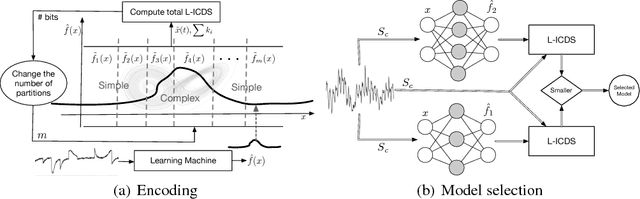

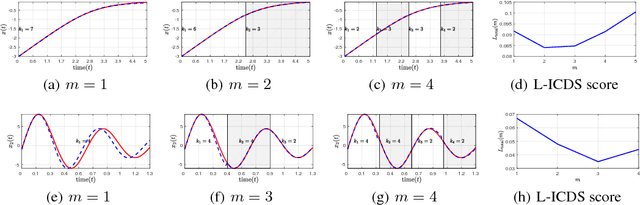
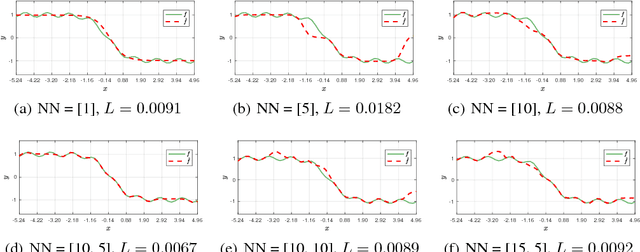
Encoding a sequence of observations is an essential task with many applications. The encoding can become highly efficient when the observations are generated by a dynamical system. A dynamical system imposes regularities on the observations that can be leveraged to achieve a more efficient code. We propose a method to encode a given or learned dynamical system. Apart from its application for encoding a sequence of observations, we propose to use the compression achieved by this encoding as a criterion for model selection. Given a dataset, different learning algorithms result in different models. But not all learned models are equally good. We show that the proposed encoding approach can be used to choose the learned model which is closer to the true underlying dynamics. We provide experiments for both encoding and model selection, and theoretical results that shed light on why the approach works.
Fidelity-Weighted Learning
May 23, 2018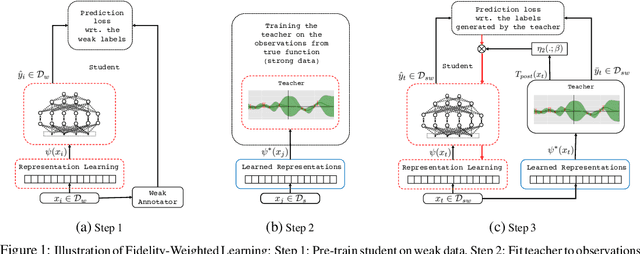
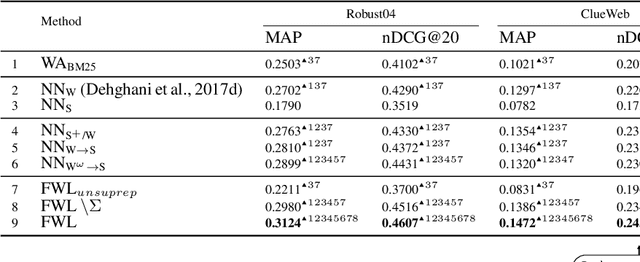
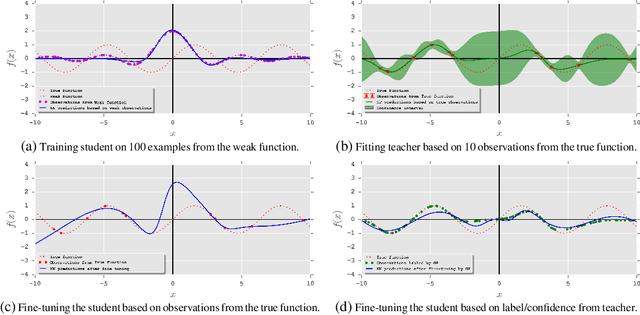
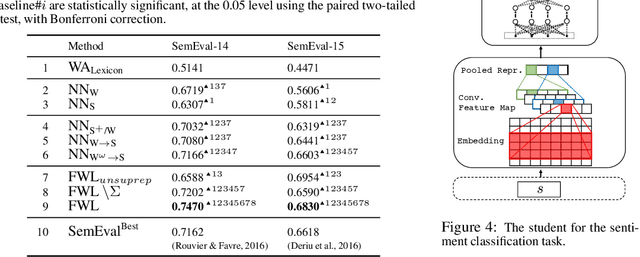
Training deep neural networks requires many training samples, but in practice training labels are expensive to obtain and may be of varying quality, as some may be from trusted expert labelers while others might be from heuristics or other sources of weak supervision such as crowd-sourcing. This creates a fundamental quality versus-quantity trade-off in the learning process. Do we learn from the small amount of high-quality data or the potentially large amount of weakly-labeled data? We argue that if the learner could somehow know and take the label-quality into account when learning the data representation, we could get the best of both worlds. To this end, we propose "fidelity-weighted learning" (FWL), a semi-supervised student-teacher approach for training deep neural networks using weakly-labeled data. FWL modulates the parameter updates to a student network (trained on the task we care about) on a per-sample basis according to the posterior confidence of its label-quality estimated by a teacher (who has access to the high-quality labels). Both student and teacher are learned from the data. We evaluate FWL on two tasks in information retrieval and natural language processing where we outperform state-of-the-art alternative semi-supervised methods, indicating that our approach makes better use of strong and weak labels, and leads to better task-dependent data representations.