 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral-Progressive Thought Flow for Lightweight Multimodal Reasoning
Jun 01, 2026Multimodal spatial reasoning often relies on long chains of intermediate textual and visual thoughts, where accumulating visual tokens and dense cross-modal attention incur substantial computation and memory overhead. To address this challenge, we propose Spectral-Progressive Thought Flow (SpecFlow), a novel lightweight multimodal spatial reasoning framework that represents intermediate visual thoughts in a fixed-size discrete cosine space. By exploiting strong energy compaction, SpecFlow preserves global layout and relational structure while introducing high-frequency details only when increased spatial precision is required. To align visual state evolution with linguistic intent, classifier-free guidance enables autoregressive textual thoughts to steer flow-based updates of the visual workspace/state without expanding the context. As a result, SpecFlow maintains a bounded visual workspace whose updates depend only on the current visual state and accumulated textual trace, enabling long-horizon inference with stable latency and memory usage independent of reasoning depth. Empirical results show that SpecFlow achieves competitive or superior reasoning performance while reducing computation and KV cache costs by up to 2.1 times.
TCL: Enabling Fast and Efficient Cross-Hardware Tensor Program Optimization via Continual Learning
Apr 14, 2026Deep learning (DL) compilers rely on cost models and auto-tuning to optimize tensor programs for target hardware. However, existing approaches depend on large offline datasets, incurring high collection costs and offering suboptimal transferability across platforms. In this paper, we introduce TCL, a novel efficient and transferable compiler framework for fast tensor program optimization across diverse hardware platforms to address these challenges. Specifically, TCL is built on three core enablers: (1) the RDU Sampler, a data-efficient active learning strategy that selects only 10% of tensor programs by jointly optimizing Representativeness, Diversity, and Uncertainty, substantially reducing data collection costs while maintaining near-original model accuracy; (2) a new Mamba-based cost model that efficiently captures long-range schedule dependencies while achieving a favorable trade-off between prediction accuracy and computational cost through reduced parameterization and lightweight sequence modeling; and (3) a continuous knowledge distillation framework that effectively and progressively transfers knowledge across multiple hardware platforms while avoiding the parameter explosion and data dependency issues typically caused by traditional multi-task learning. Extensive experiments validate the effectiveness of each individual enabler and the holistic TCL framework. When optimizing a range of mainstream DL models on both CPU and GPU platforms, TCL achieves, on average, 16.8x and 12.48x faster tuning time, and 1.20x and 1.13x lower inference latency, respectively, compared to Tenset-MLP.
Active Imitation Learning for Thermal- and Kernel-Aware LFM Inference on 3D S-NUCA Many-Cores
Apr 13, 2026Large Foundation Model (LFM) inference is both memory- and compute-intensive, traditionally relying on GPUs. However, the limited availability and high cost have motivated the adoption of high-performance general-purpose CPUs, especially emerging 3D-stacked Static Non-Uniform Cache Architecture (3D S-NUCA) systems. These architectures offer enhanced bandwidth and locality but suffer from severe thermal challenges and uneven cache latencies due to 3D Networks-on-Chip (NoC). Optimal management of thread migration and V/f scaling is non-trivial due to LFM kernel diversity and system heterogeneity. Existing thermal management approaches often rely on oversimplified analytical models and lack adaptability. We propose AILFM, an Active Imitation Learning (AIL)-based scheduling framework that learns near-optimal thermal-aware scheduling policies from Oracle demonstrations with minimal run-time overhead. AILFM accounts for both core-level performance heterogeneity and kernel-specific behavior in LFMs to maintain thermal safety while maximizing performance. Extensive experiments show that AILFM outperforms state-of-the-art baselines and generalizes well across diverse LFM workloads.
MaCP: Minimal yet Mighty Adaptation via Hierarchical Cosine Projection
May 29, 2025



We present a new adaptation method MaCP, Minimal yet Mighty adaptive Cosine Projection, that achieves exceptional performance while requiring minimal parameters and memory for fine-tuning large foundation models. Its general idea is to exploit the superior energy compaction and decorrelation properties of cosine projection to improve both model efficiency and accuracy. Specifically, it projects the weight change from the low-rank adaptation into the discrete cosine space. Then, the weight change is partitioned over different levels of the discrete cosine spectrum, and each partition's most critical frequency components are selected. Extensive experiments demonstrate the effectiveness of MaCP across a wide range of single-modality tasks, including natural language understanding, natural language generation, text summarization, as well as multi-modality tasks such as image classification and video understanding. MaCP consistently delivers superior accuracy, significantly reduced computational complexity, and lower memory requirements compared to existing alternatives.
SSH: Sparse Spectrum Adaptation via Discrete Hartley Transformation
Feb 08, 2025



Low-rank adaptation (LoRA) has been demonstrated effective in reducing the trainable parameter number when fine-tuning a large foundation model (LLM). However, it still encounters computational and memory challenges when scaling to larger models or addressing more complex task adaptation. In this work, we introduce Sparse Spectrum Adaptation via Discrete Hartley Transformation (SSH), a novel approach that significantly reduces the number of trainable parameters while enhancing model performance. It selects the most informative spectral components across all layers, under the guidance of the initial weights after a discrete Hartley transformation (DHT). The lightweight inverse DHT then projects the spectrum back into the spatial domain for updates. Extensive experiments across both single-modality tasks such as language understanding and generation and multi-modality tasks such as video-text understanding demonstrate that SSH outperforms existing parameter-efficient fine-tuning (PEFT) methods while achieving substantial reductions in computational cost and memory requirements.
Parameter-Efficient Fine-Tuning via Selective Discrete Cosine Transform
Oct 09, 2024In the era of large language models, parameter-efficient fine-tuning (PEFT) has been extensively studied. However, these approaches usually rely on the space domain, which encounters storage challenges especially when handling extensive adaptations or larger models. The frequency domain, in contrast, is more effective in compressing trainable parameters while maintaining the expressive capability. In this paper, we propose a novel Selective Discrete Cosine Transformation (sDCTFT) fine-tuning scheme to push this frontier. Its general idea is to exploit the superior energy compaction and decorrelation properties of DCT to improve both model efficiency and accuracy. Specifically, it projects the weight change from the low-rank adaptation into the discrete cosine space. Then, the weight change is partitioned over different levels of the discrete cosine spectrum, and the most critical frequency components in each partition are selected. Extensive experiments on four benchmark datasets demonstrate the superior accuracy, reduced computational cost, and lower storage requirements of the proposed method over the prior arts. For instance, when performing instruction tuning on the LLaMA3.1-8B model, sDCTFT outperforms LoRA with just 0.05M trainable parameters compared to LoRA's 38.2M, and surpasses FourierFT with 30\% less trainable parameters. The source code will be publicly available.
Neural Network Inference on Mobile SoCs
Aug 24, 2019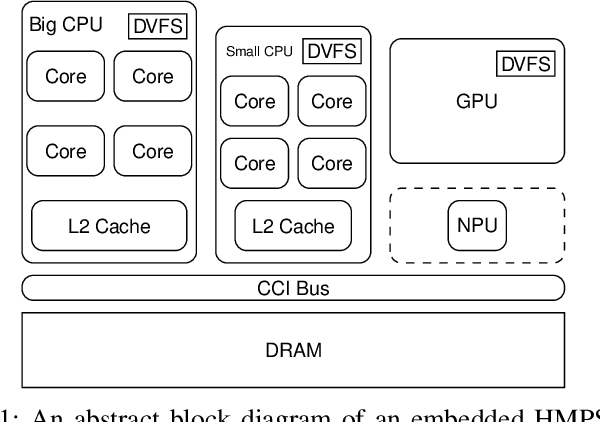
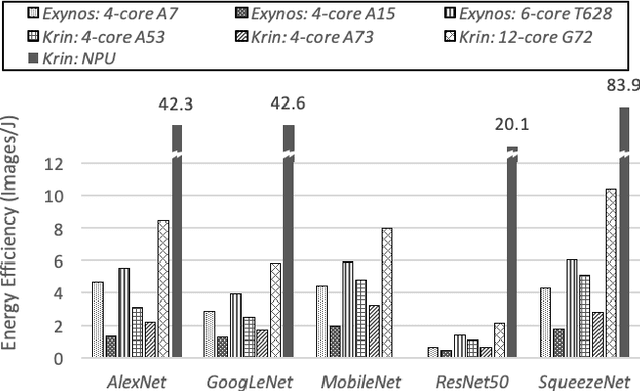
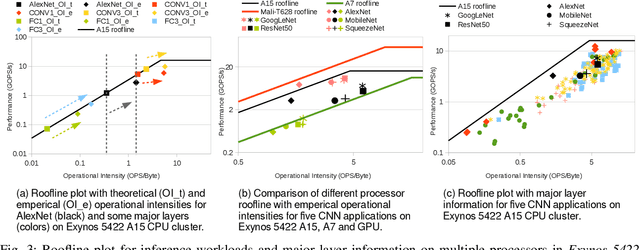
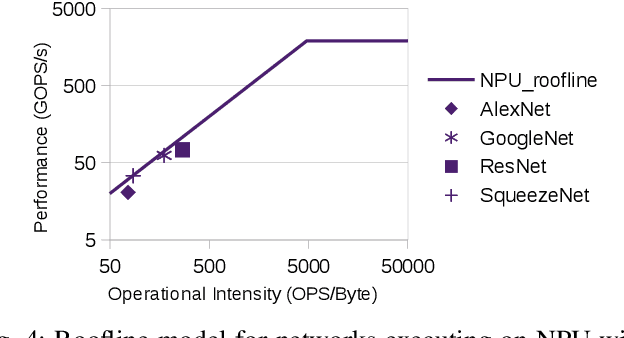
The ever-increasing demand from mobile Machine Learning (ML) applications calls for evermore powerful on-chip computing resources. Mobile devices are empowered with Heterogeneous Multi-Processor Systems on Chips (HMPSoCs) to process ML workloads such as Convolutional Neural Network (CNN) inference. HMPSoCs house several different types of ML capable components on-die, such as CPU, GPU, and accelerators. These different components are capable of independently performing inference but with very different power-performance characteristics. In this article, we provide a quantitative evaluation of the inference capabilities of the different components on HMPSoCs. We also present insights behind their respective power-performance behaviour. Finally, we explore the performance limit of the HMPSoCs by synergistically engaging all the components concurrently.
High-Throughput CNN Inference on Embedded ARM big.LITTLE Multi-Core Processors
Mar 14, 2019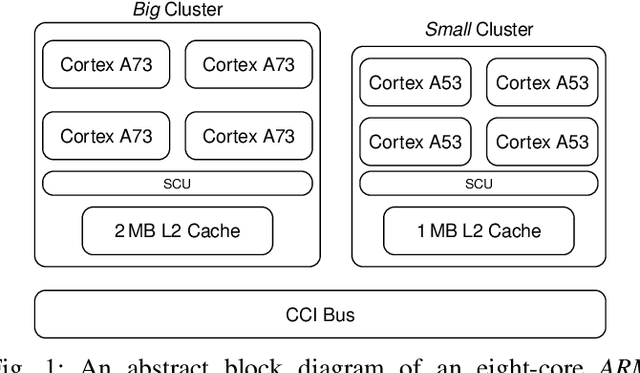
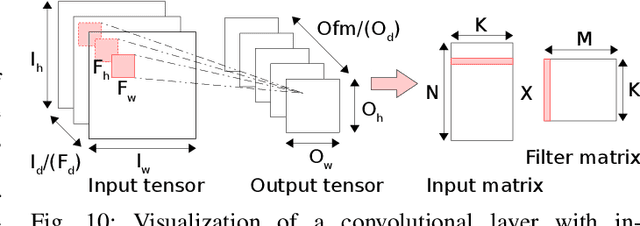
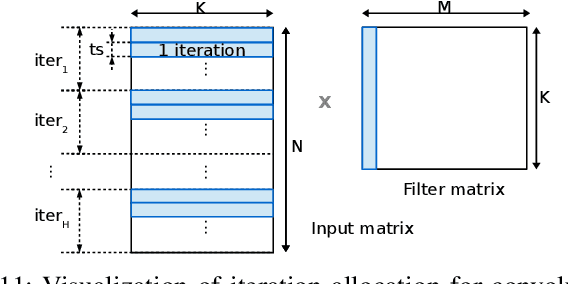
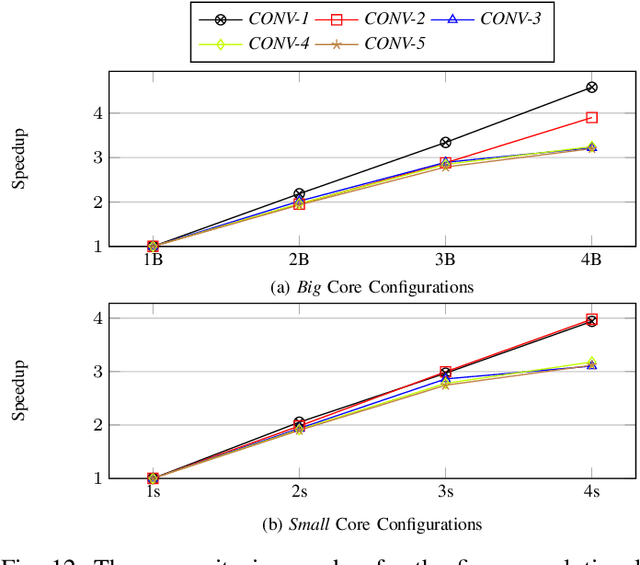
IoT Edge intelligence requires Convolutional Neural Network (CNN) inference to take place in the edge device itself. ARM big.LITTLE architecture is at the heart of common commercial edge devices. It comprises of single-ISA heterogeneous multi-cores grouped in homogeneous clusters that enables performance and power trade-offs. However, high communication overhead involved in parallelization of computation from a convolution kernel across clusters is detrimental to throughput. We present an alternative framework called Pipe-it that employs a pipelined design to split the convolutional layers across clusters while limiting the parallelization of their respective kernels to the assigned clusters. We develop a performance prediction model that, from convolutional layer descriptors, predicts the execution time of each layer individually on all different core types and number of cores. Pipe-it then exploits the predictions to create a balanced pipeline using an efficient design space exploration algorithm. Pipe-it on average results in 39% higher throughput than the highest antecedent throughput.