 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Processes with Differential Privacy
Jun 01, 2021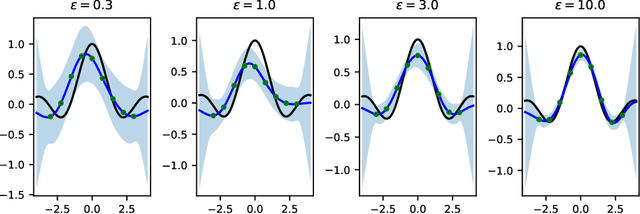
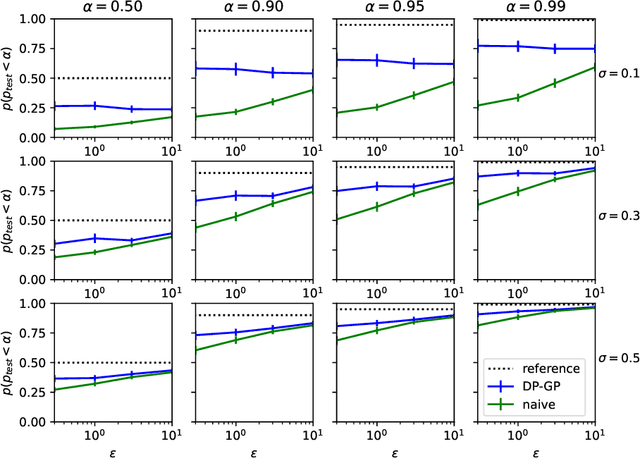
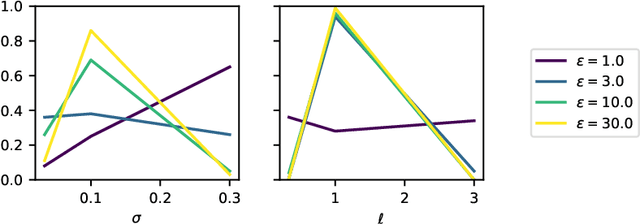
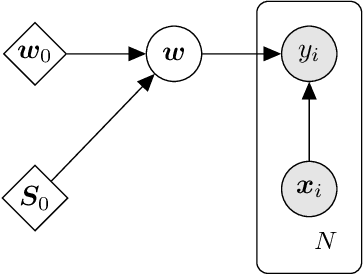
Gaussian processes (GPs) are non-parametric Bayesian models that are widely used for diverse prediction tasks. Previous work in adding strong privacy protection to GPs via differential privacy (DP) has been limited to protecting only the privacy of the prediction targets (model outputs) but not inputs. We break this limitation by introducing GPs with DP protection for both model inputs and outputs. We achieve this by using sparse GP methodology and publishing a private variational approximation on known inducing points. The approximation covariance is adjusted to approximately account for the added uncertainty from DP noise. The approximation can be used to compute arbitrary predictions using standard sparse GP techniques. We propose a method for hyperparameter learning using a private selection protocol applied to validation set log-likelihood. Our experiments demonstrate that given sufficient amount of data, the method can produce accurate models under strong privacy protection.
d3p -- A Python Package for Differentially-Private Probabilistic Programming
Mar 22, 2021
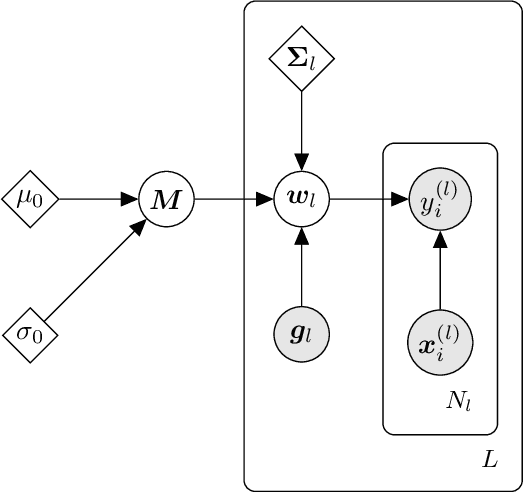

We present d3p, a software package designed to help fielding runtime efficient widely-applicable Bayesian inference under differential privacy guarantees. d3p achieves general applicability to a wide range of probabilistic modelling problems by implementing the differentially private variational inference algorithm, allowing users to fit any parametric probabilistic model with a differentiable density function. d3p adopts the probabilistic programming paradigm as a powerful way for the user to flexibly define such models. We demonstrate the use of our software on a hierarchical logistic regression example, showing the expressiveness of the modelling approach as well as the ease of running the parameter inference. We also perform an empirical evaluation of the runtime of the private inference on a complex model and find an $\sim$10 fold speed-up compared to an implementation using TensorFlow Privacy.
Computing Differential Privacy Guarantees for Heterogeneous Compositions Using FFT
Feb 24, 2021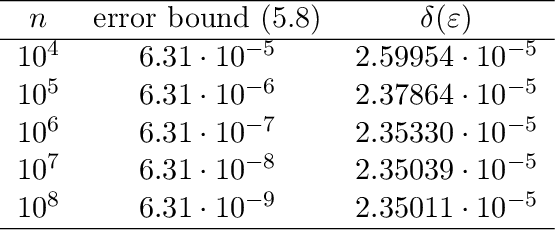
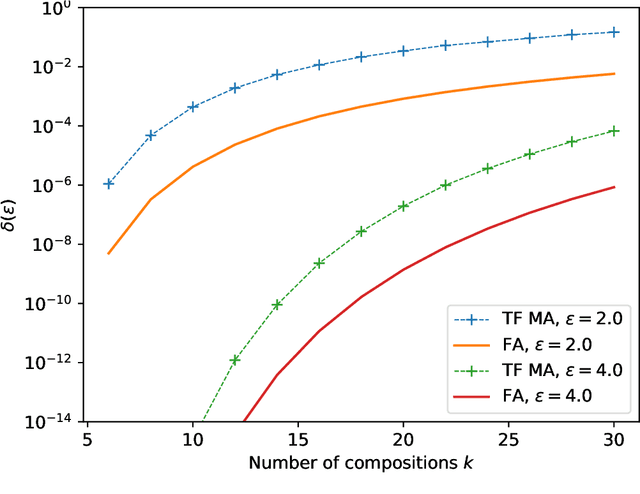
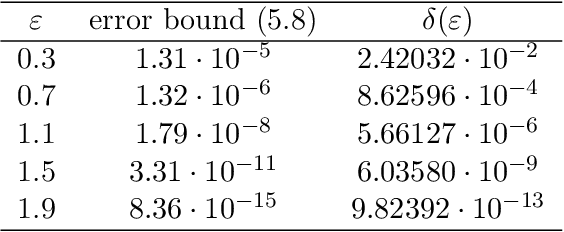
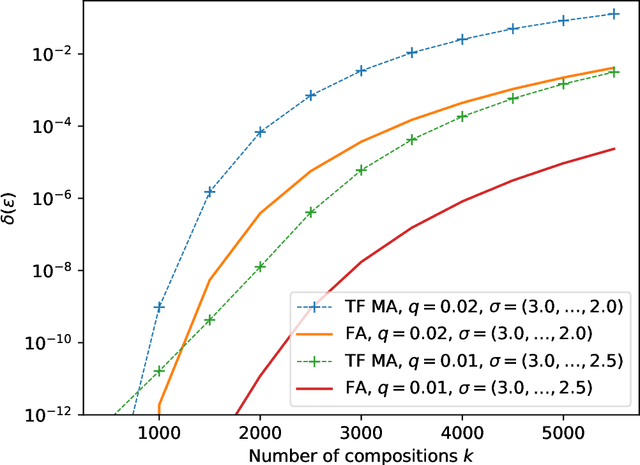
The recently proposed Fast Fourier Transform (FFT)-based accountant for evaluating $(\varepsilon,\delta)$-differential privacy guarantees using the privacy loss distribution formalism has been shown to give tighter bounds than commonly used methods such as R\'enyi accountants when applied to compositions of homogeneous mechanisms. This approach is also applicable to certain discrete mechanisms that cannot be analysed with R\'enyi accountants. In this paper, we extend this approach to compositions of heterogeneous mechanisms. We carry out a full error analysis that allows choosing the parameters of the algorithm such that a desired accuracy is obtained. Using our analysis, we also give a bound for the computational complexity in terms of the error which is analogous to and slightly tightens the one given by Murtagh and Vadhan (2018). We also show how to speed up the evaluation of tight privacy guarantees using the Plancherel theorem at the cost of increased pre-computation and memory usage.
Differentially Private Bayesian Inference for Generalized Linear Models
Nov 09, 2020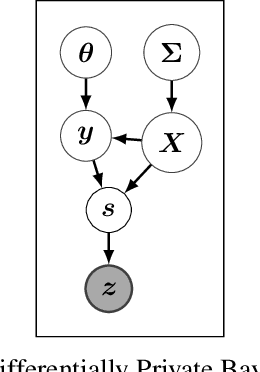
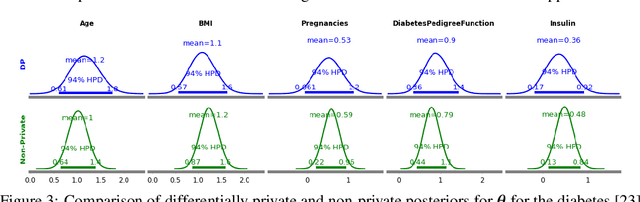
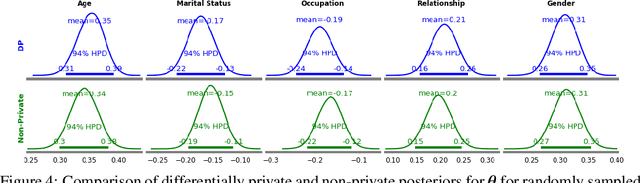
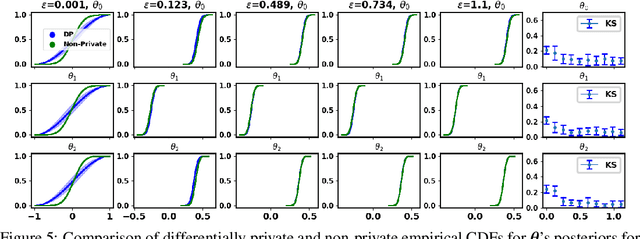
The framework of differential privacy (DP) upper bounds the information disclosure risk involved in using sensitive datasets for statistical analysis. A DP mechanism typically operates by adding carefully calibrated noise to the data release procedure. Generalized linear models (GLMs) are among the most widely used arms in data analyst's repertoire. In this work, with logistic and Poisson regression as running examples, we propose a generic noise-aware Bayesian framework to quantify the parameter uncertainty for a GLM at hand, given noisy sufficient statistics. We perform a tight privacy analysis and experimentally demonstrate that the posteriors obtained from our model, while adhering to strong privacy guarantees, are similar to the non-private posteriors.
Privacy-preserving Data Sharing on Vertically Partitioned Data
Oct 19, 2020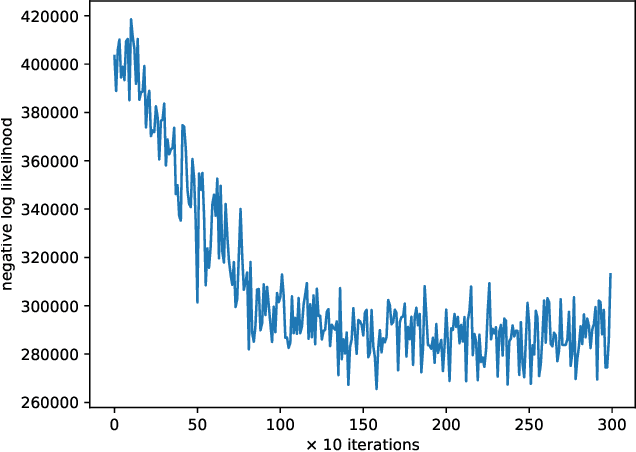
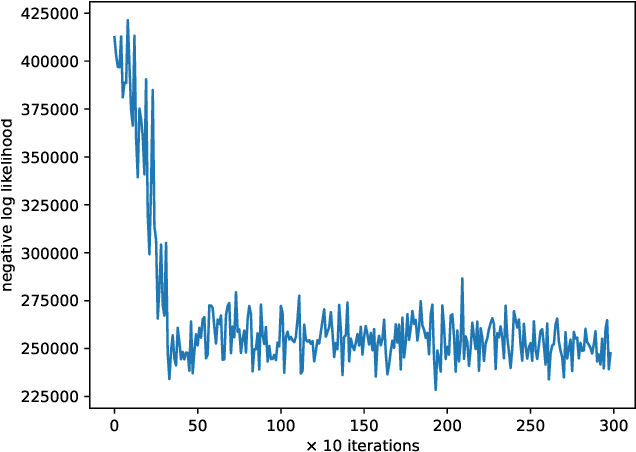
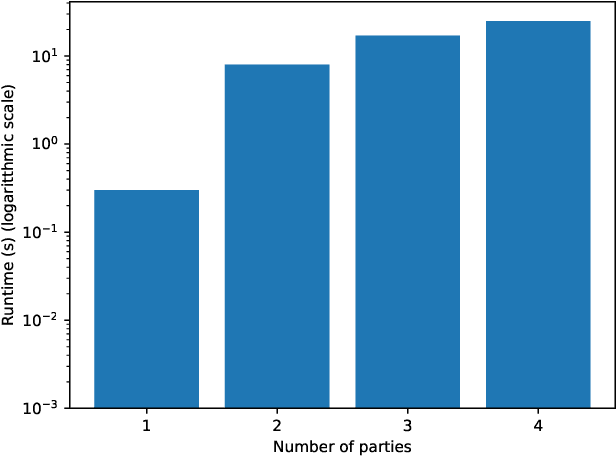
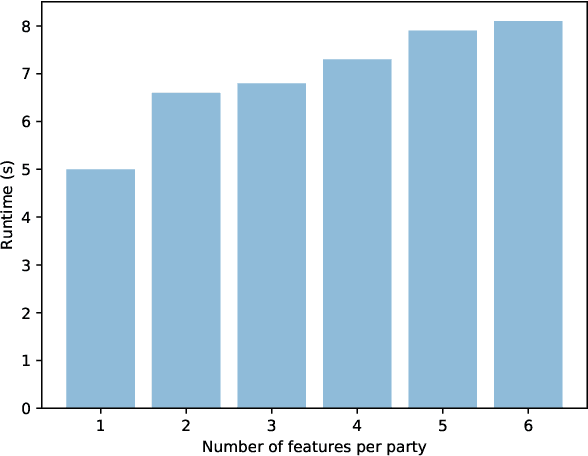
In this work, we present a method for differentially private data sharing by training a mixture model on vertically partitioned data, where each party holds different features for the same set of individuals. We use secure multi-party computation (MPC) to combine the contribution of the data from the parties to train the model. We apply the differentially private variational inference (DPVI) for learning the model. Assuming the mixture components contain no dependencies across different parties, the objective function can be factorized into a sum of products of individual components of each party. Therefore, each party can calculate its shares on its own without the use of MPC. Then MPC is only needed to get the product between the different shares and add the noise. Applying the method to demographic data from the US Census, we obtain comparable accuracy to the non-partitioned case with approximately 20-fold increase in computing time.
Differentially private cross-silo federated learning
Jul 10, 2020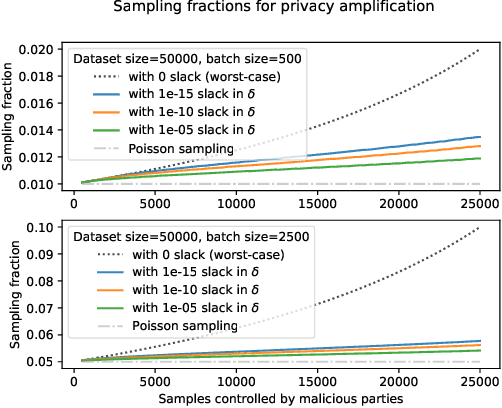
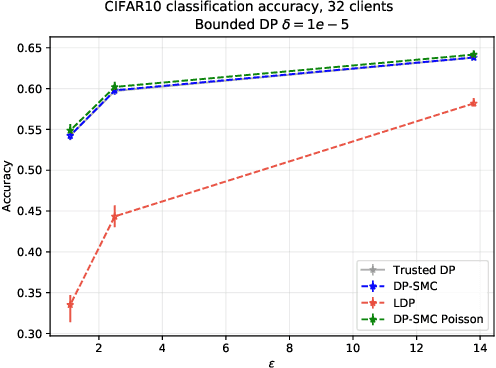
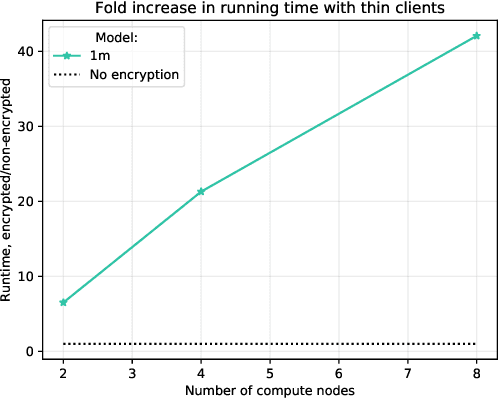
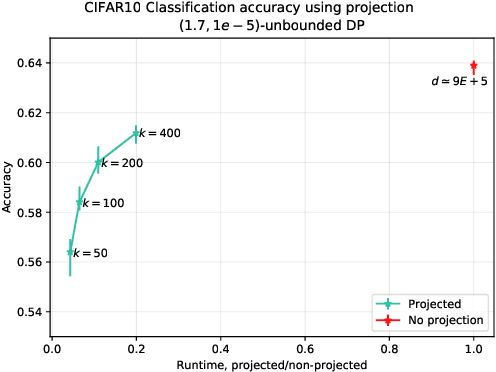
Strict privacy is of paramount importance in distributed machine learning. Federated learning, with the main idea of communicating only what is needed for learning, has been recently introduced as a general approach for distributed learning to enhance learning and improve security. However, federated learning by itself does not guarantee any privacy for data subjects. To quantify and control how much privacy is compromised in the worst-case, we can use differential privacy. In this paper we combine additively homomorphic secure summation protocols with differential privacy in the so-called cross-silo federated learning setting. The goal is to learn complex models like neural networks while guaranteeing strict privacy for the individual data subjects. We demonstrate that our proposed solutions give prediction accuracy that is comparable to the non-distributed setting, and are fast enough to enable learning models with millions of parameters in a reasonable time. To enable learning under strict privacy guarantees that need privacy amplification by subsampling, we present a general algorithm for oblivious distributed subsampling. However, we also argue that when malicious parties are present, a simple approach using distributed Poisson subsampling gives better privacy. Finally, we show that by leveraging random projections we can further scale-up our approach to larger models while suffering only a modest performance loss.
Tight Approximate Differential Privacy for Discrete-Valued Mechanisms Using FFT
Jun 12, 2020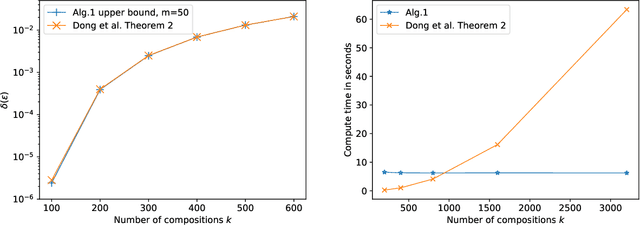
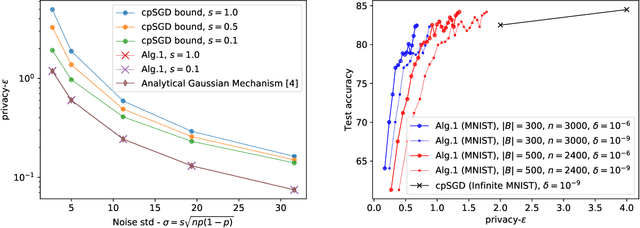
We propose a numerical accountant for evaluating the tight $(\varepsilon,\delta)$-privacy loss for algorithms with discrete one-dimensional output. The method is based on the privacy loss distribution formalism and it is able to exploit the recently introduced Fast Fourier Transform based accounting technique. We carry out a complete error analysis of the method in terms of the moment bounds for the numerical estimate of the privacy loss distribution. We demonstrate the performance on the binomial mechanism and show that our approach allows decreasing noise variance up to an order of magnitude at equal privacy compared to existing bounds in the literature. We also give a novel approach for evaluating $(\varepsilon,\delta)$-upper bound for the subsampled Gaussian mechanism. This completes the previously proposed analysis by giving a strict upper bound for $(\varepsilon,\delta)$. We also illustrate how to compute tight bounds for the exponential mechanism applied to counting queries.
Privacy-preserving data sharing via probabilistic modelling
Jan 29, 2020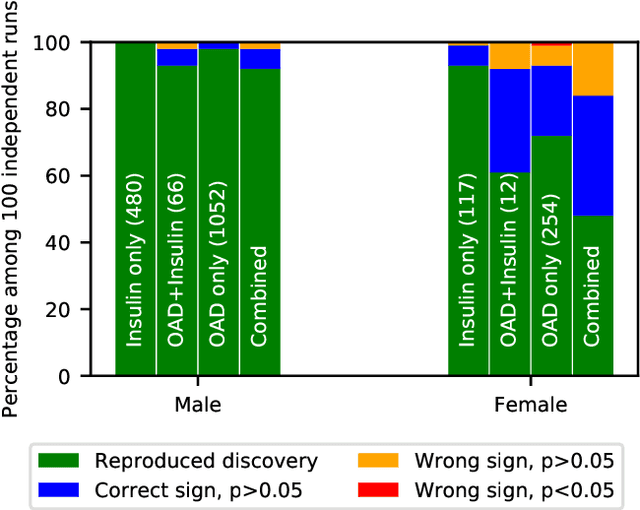
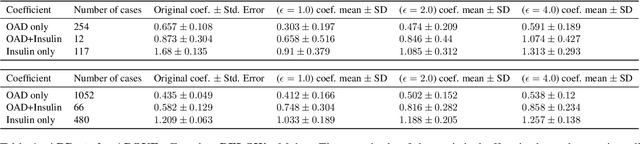
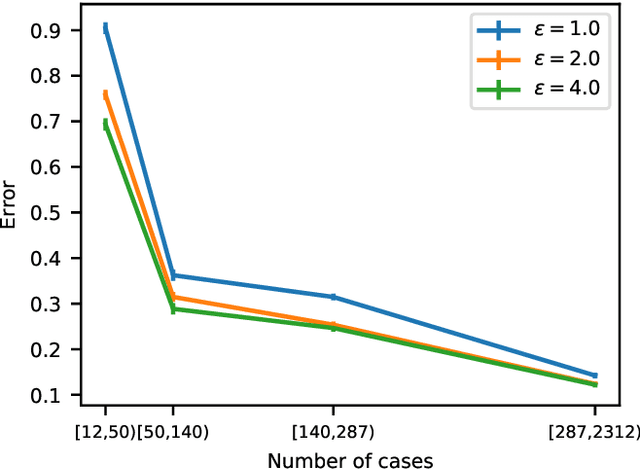
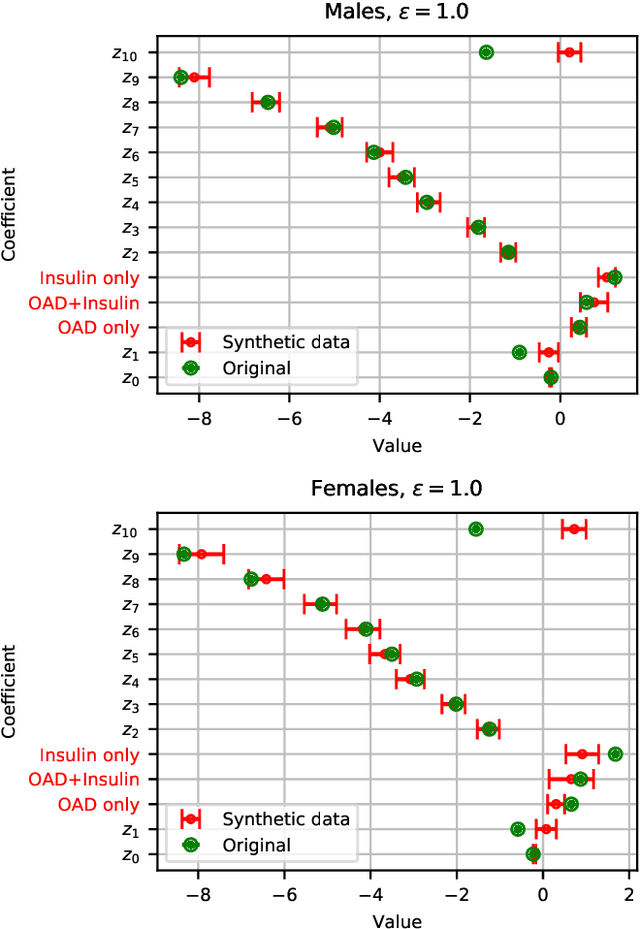
Differential privacy allows quantifying privacy loss from computations on sensitive personal data. This loss grows with the number of accesses to the data, making it hard to open the use of such data while respecting privacy. To avoid this limitation, we propose privacy-preserving release of a synthetic version of a data set, which can be used for an unlimited number of analyses with any methods, without affecting the privacy guarantees. The synthetic data generation is based on differentially private learning of a generative probabilistic model which can capture the probability distribution of the original data. We demonstrate empirically that we can reliably reproduce statistical discoveries from the synthetic data. We expect the method to have broad use in sharing anonymized versions of key data sets for research.
Differentially Private Federated Variational Inference
Nov 24, 2019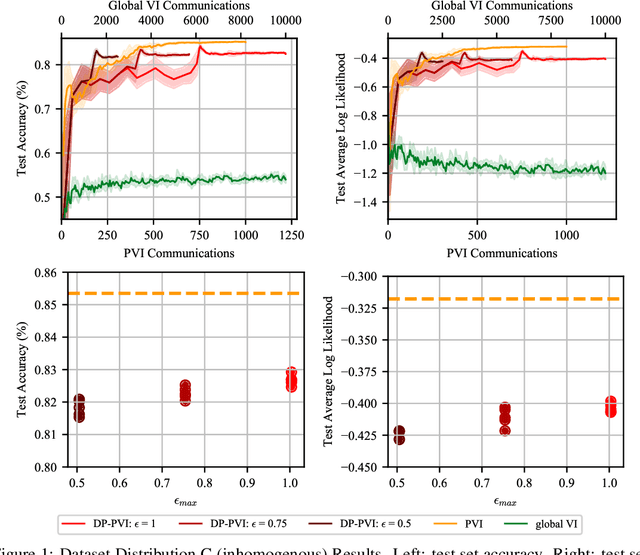
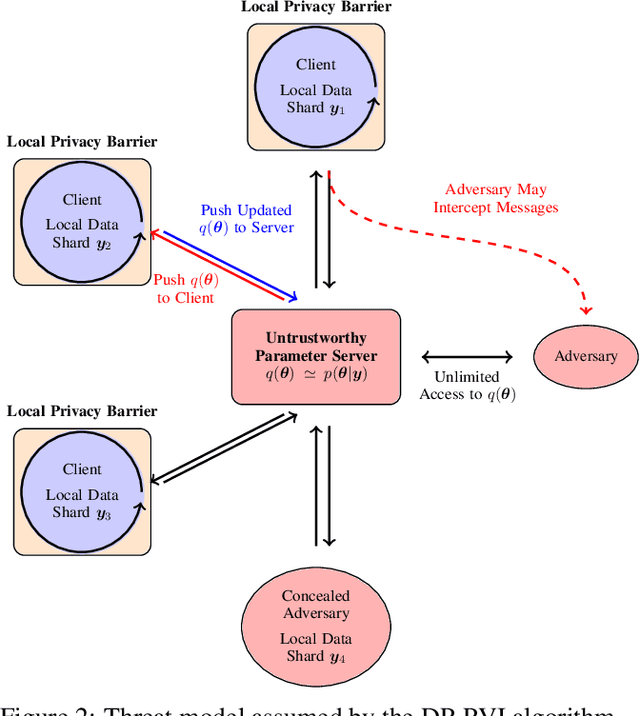

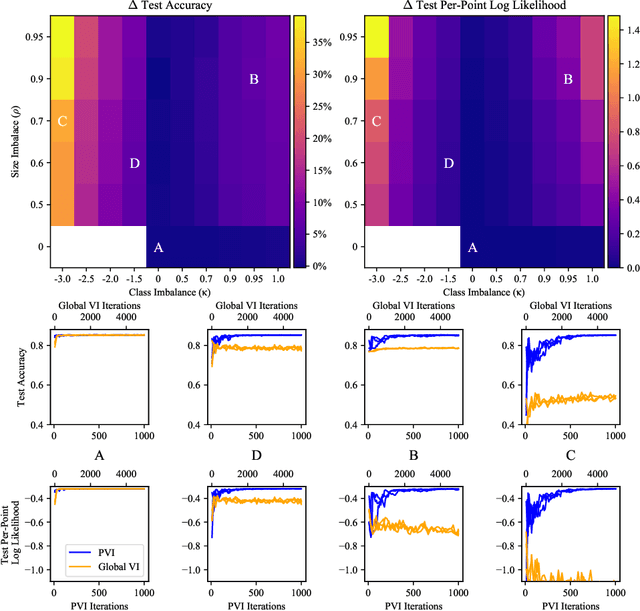
In many real-world applications of machine learning, data are distributed across many clients and cannot leave the devices they are stored on. Furthermore, each client's data, computational resources and communication constraints may be very different. This setting is known as federated learning, in which privacy is a key concern. Differential privacy is commonly used to provide mathematical privacy guarantees. This work, to the best of our knowledge, is the first to consider federated, differentially private, Bayesian learning. We build on Partitioned Variational Inference (PVI) which was recently developed to support approximate Bayesian inference in the federated setting. We modify the client-side optimisation of PVI to provide an (${\epsilon}$, ${\delta}$)-DP guarantee. We show that it is possible to learn moderately private logistic regression models in the federated setting that achieve similar performance to models trained non-privately on centralised data.
Computing Exact Guarantees for Differential Privacy
Jun 07, 2019
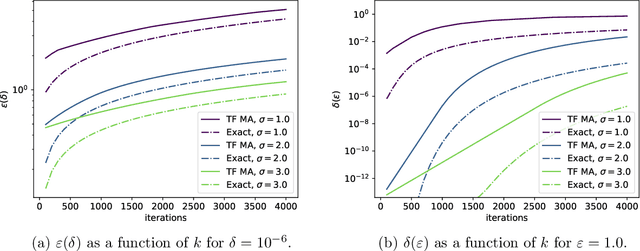
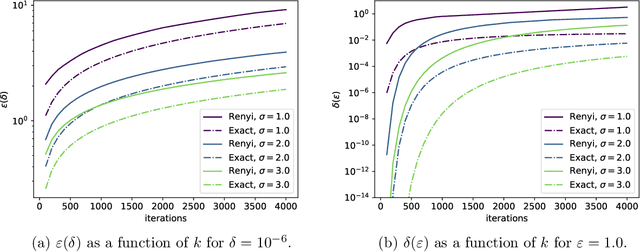
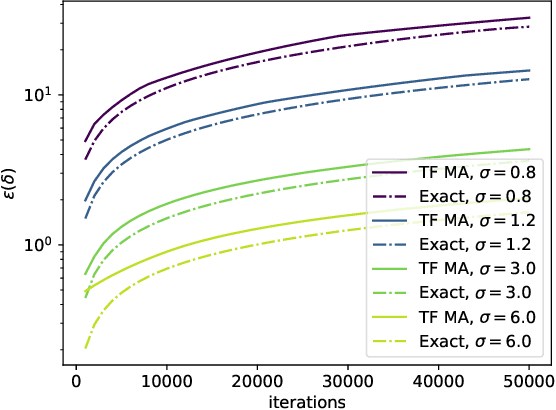
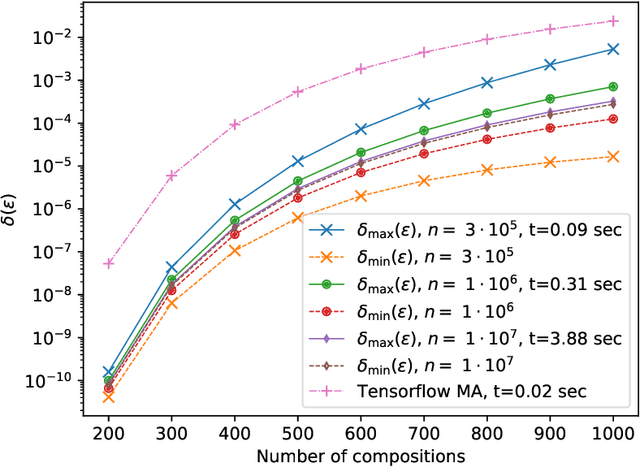
Quantification of the privacy loss associated with a randomised algorithm has become an active area of research and $(\varepsilon,\delta)$-differential privacy has arisen as the standard measure of it. We propose a numerical method for evaluating the parameters of differential privacy for algorithms with continuous one dimensional output. In this way the parameters $\varepsilon$ and $\delta$ can be evaluated, for example, for the subsampled multidimensional Gaussian mechanism which is also the underlying mechanism of differentially private stochastic gradient descent. The proposed method is based on a numerical approximation of an integral formula which gives the exact $(\varepsilon,\delta)$-values. The approximation is carried out by discretising the integral and by evaluating discrete convolutions using a fast Fourier transform algorithm. We give theoretical error bounds which show the convergence of the approximation and guarantee its accuracy to an arbitrary degree. Experimental comparisons with state-of-the-art techniques illustrate the efficacy of the method. Python code for the proposed method can be found in Github (https://github.com/DPBayes/PLD-Accountant/).