 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Dataset for Presence-Only Passive Reconnaissance in Wireless Smart-Grid Communications
Mar 10, 2026Benchmarking presence-only passive reconnaissance in smart-grid communications is challenging because the adversary is receive-only, yet nearby observers can still alter propagation through additional shadowing and multipath that reshapes channel coherence. Public smart-grid cybersecurity datasets largely target active protocol- or measurement-layer attacks and rarely provide propagation-driven observables with tiered topology context, which limits reproducible evaluation under strictly passive threat models. This paper introduces an IEEE-inspired, literature-anchored benchmark dataset generator for passive reconnaissance over a tiered Home Area Network (HAN), Neighborhood Area Network (NAN), and Wide Area Network (WAN) communication graph with heterogeneous wireless and wireline links. Node-level time series are produced through a physically consistent channel-to-metrics mapping where channel state information (CSI) is represented via measurement-realistic amplitude and phase proxies that drive inferred signal-to-noise ratio (SNR), packet error behavior, and delay dynamics. Passive attacks are modeled only as windowed excess attenuation and coherence degradation with increased channel innovation, so reliability and latency deviations emerge through the same causal mapping without labels or feature shortcuts. The release provides split-independent realizations with burn-in removal, strictly causal temporal descriptors, adjacency-weighted neighbor aggregates and deviation features, and federated-ready per-node train, validation, and test partitions with train-only normalization metadata. Baseline federated experiments highlight technology-dependent detectability and enable standardized benchmarking of graph-temporal and federated detectors for passive reconnaissance.
On the Effectiveness of Membership Inference in Targeted Data Extraction from Large Language Models
Dec 15, 2025Large Language Models (LLMs) are prone to memorizing training data, which poses serious privacy risks. Two of the most prominent concerns are training data extraction and Membership Inference Attacks (MIAs). Prior research has shown that these threats are interconnected: adversaries can extract training data from an LLM by querying the model to generate a large volume of text and subsequently applying MIAs to verify whether a particular data point was included in the training set. In this study, we integrate multiple MIA techniques into the data extraction pipeline to systematically benchmark their effectiveness. We then compare their performance in this integrated setting against results from conventional MIA benchmarks, allowing us to evaluate their practical utility in real-world extraction scenarios.
Privacy-preserving Data Sharing on Vertically Partitioned Data
Oct 19, 2020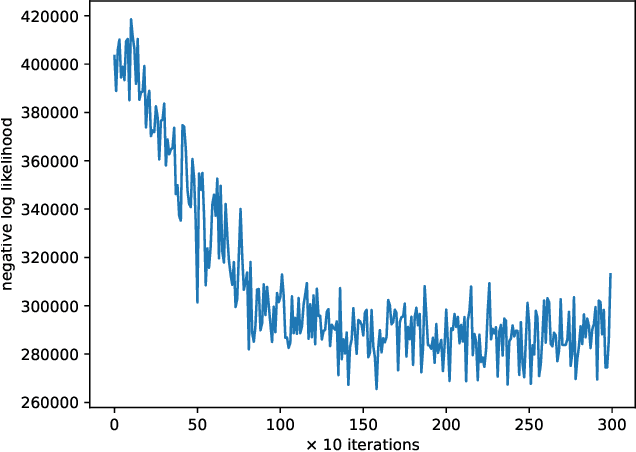
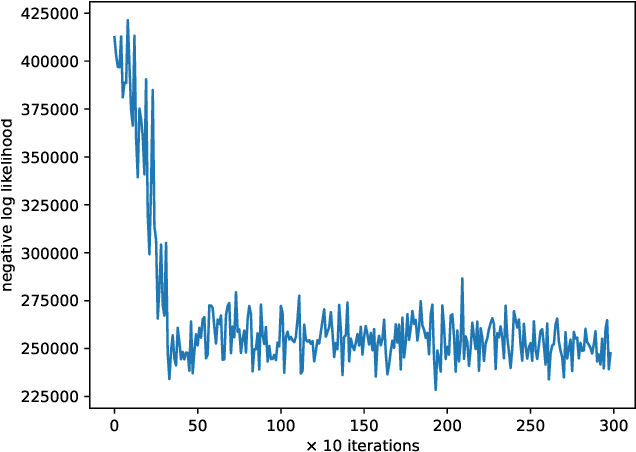
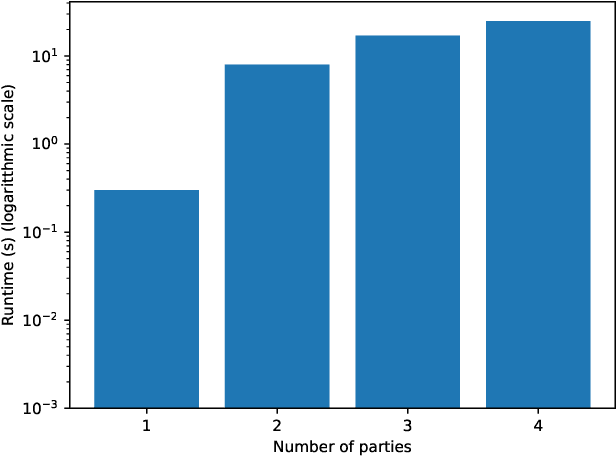
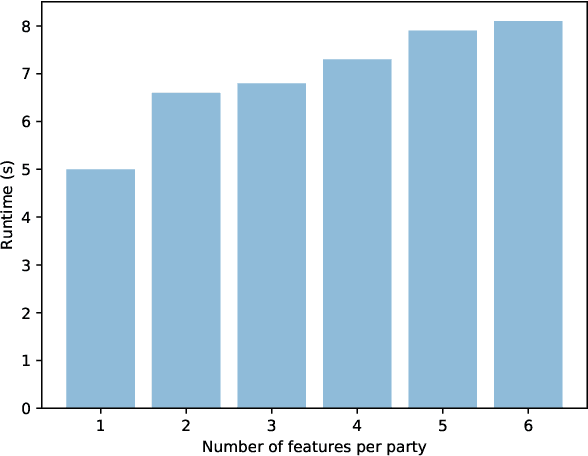
In this work, we present a method for differentially private data sharing by training a mixture model on vertically partitioned data, where each party holds different features for the same set of individuals. We use secure multi-party computation (MPC) to combine the contribution of the data from the parties to train the model. We apply the differentially private variational inference (DPVI) for learning the model. Assuming the mixture components contain no dependencies across different parties, the objective function can be factorized into a sum of products of individual components of each party. Therefore, each party can calculate its shares on its own without the use of MPC. Then MPC is only needed to get the product between the different shares and add the noise. Applying the method to demographic data from the US Census, we obtain comparable accuracy to the non-partitioned case with approximately 20-fold increase in computing time.