 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bias-Variance Decomposition for Ensembles over Multiple Synthetic Datasets
Feb 06, 2024



Recent studies have highlighted the benefits of generating multiple synthetic datasets for supervised learning, from increased accuracy to more effective model selection and uncertainty estimation. These benefits have clear empirical support, but the theoretical understanding of them is currently very light. We seek to increase the theoretical understanding by deriving bias-variance decompositions for several settings of using multiple synthetic datasets. Our theory predicts multiple synthetic datasets to be especially beneficial for high-variance downstream predictors, and yields a simple rule of thumb to select the appropriate number of synthetic datasets in the case of mean-squared error and Brier score. We investigate how our theory works in practice by evaluating the performance of an ensemble over many synthetic datasets for several real datasets and downstream predictors. The results follow our theory, showing that our insights are also practically relevant.
Privacy-Aware Document Visual Question Answering
Dec 15, 2023



Document Visual Question Answering (DocVQA) is a fast growing branch of document understanding. Despite the fact that documents contain sensitive or copyrighted information, none of the current DocVQA methods offers strong privacy guarantees. In this work, we explore privacy in the domain of DocVQA for the first time. We highlight privacy issues in state of the art multi-modal LLM models used for DocVQA, and explore possible solutions. Specifically, we focus on the invoice processing use case as a realistic, widely used scenario for document understanding, and propose a large scale DocVQA dataset comprising invoice documents and associated questions and answers. We employ a federated learning scheme, that reflects the real-life distribution of documents in different businesses, and we explore the use case where the ID of the invoice issuer is the sensitive information to be protected. We demonstrate that non-private models tend to memorise, behaviour that can lead to exposing private information. We then evaluate baseline training schemes employing federated learning and differential privacy in this multi-modal scenario, where the sensitive information might be exposed through any of the two input modalities: vision (document image) or language (OCR tokens). Finally, we design an attack exploiting the memorisation effect of the model, and demonstrate its effectiveness in probing different DocVQA models.
Collaborative Learning From Distributed Data With Differentially Private Synthetic Twin Data
Aug 09, 2023



Consider a setting where multiple parties holding sensitive data aim to collaboratively learn population level statistics, but pooling the sensitive data sets is not possible. We propose a framework in which each party shares a differentially private synthetic twin of their data. We study the feasibility of combining such synthetic twin data sets for collaborative learning on real-world health data from the UK Biobank. We discover that parties engaging in the collaborative learning via shared synthetic data obtain more accurate estimates of target statistics compared to using only their local data. This finding extends to the difficult case of small heterogeneous data sets. Furthermore, the more parties participate, the larger and more consistent the improvements become. Finally, we find that data sharing can especially help parties whose data contain underrepresented groups to perform better-adjusted analysis for said groups. Based on our results we conclude that sharing of synthetic twins is a viable method for enabling learning from sensitive data without violating privacy constraints even if individual data sets are small or do not represent the overall population well. The setting of distributed sensitive data is often a bottleneck in biomedical research, which our study shows can be alleviated with privacy-preserving collaborative learning methods.
On the Efficacy of Differentially Private Few-shot Image Classification
Feb 02, 2023There has been significant recent progress in training differentially private (DP) models which achieve accuracy that approaches the best non-private models. These DP models are typically pretrained on large public datasets and then fine-tuned on downstream datasets that are (i) relatively large, and (ii) similar in distribution to the pretraining data. However, in many applications including personalization, it is crucial to perform well in the few-shot setting, as obtaining large amounts of labeled data may be problematic; and on images from a wide variety of domains for use in various specialist settings. To understand under which conditions few-shot DP can be effective, we perform an exhaustive set of experiments that reveals how the accuracy and vulnerability to attack of few-shot DP image classification models are affected as the number of shots per class, privacy level, model architecture, dataset, and subset of learnable parameters in the model vary. We show that to achieve DP accuracy on par with non-private models, the shots per class must be increased as the privacy level increases by as much as 32$\times$ for CIFAR-100 at $\epsilon=1$. We also find that few-shot non-private models are highly susceptible to membership inference attacks. DP provides clear mitigation against the attacks, but a small $\epsilon$ is required to effectively prevent them. Finally, we evaluate DP federated learning systems and establish state-of-the-art performance on the challenging FLAIR federated learning benchmark.
DPVIm: Differentially Private Variational Inference Improved
Oct 28, 2022



Differentially private (DP) release of multidimensional statistics typically considers an aggregate sensitivity, e.g. the vector norm of a high-dimensional vector. However, different dimensions of that vector might have widely different magnitudes and therefore DP perturbation disproportionately affects the signal across dimensions. We observe this problem in the gradient release of the DP-SGD algorithm when using it for variational inference (VI), where it manifests in poor convergence as well as high variance in outputs for certain variational parameters, and make the following contributions: (i) We mathematically isolate the cause for the difference in magnitudes between gradient parts corresponding to different variational parameters. Using this as prior knowledge we establish a link between the gradients of the variational parameters, and propose an efficient while simple fix for the problem to obtain a less noisy gradient estimator, which we call $\textit{aligned}$ gradients. This approach allows us to obtain the updates for the covariance parameter of a Gaussian posterior approximation without a privacy cost. We compare this to alternative approaches for scaling the gradients using analytically derived preconditioning, e.g. natural gradients. (ii) We suggest using iterate averaging over the DP parameter traces recovered during the training, to reduce the DP-induced noise in parameter estimates at no additional cost in privacy. Finally, (iii) to accurately capture the additional uncertainty DP introduces to the model parameters, we infer the DP-induced noise from the parameter traces and include that in the learned posteriors to make them $\textit{noise aware}$. We demonstrate the efficacy of our proposed improvements through various experiments on real data.
Individual Privacy Accounting with Gaussian Differential Privacy
Sep 30, 2022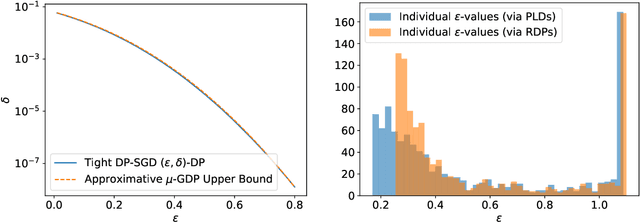
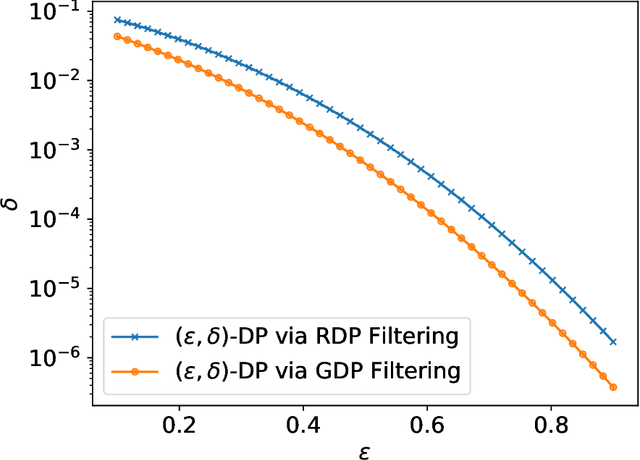
Individual privacy accounting enables bounding differential privacy (DP) loss individually for each participant involved in the analysis. This can be informative as often the individual privacy losses are considerably smaller than those indicated by the DP bounds that are based on considering worst-case bounds at each data access. In order to account for the individual privacy losses in a principled manner, we need a privacy accountant for adaptive compositions of randomised mechanisms, where the loss incurred at a given data access is allowed to be smaller than the worst-case loss. This kind of analysis has been carried out for the R\'enyi differential privacy (RDP) by Feldman and Zrnic (2021), however not yet for the so-called optimal privacy accountants. We make first steps in this direction by providing a careful analysis using the Gaussian differential privacy which gives optimal bounds for the Gaussian mechanism, one of the most versatile DP mechanisms. This approach is based on determining a certain supermartingale for the hockey-stick divergence and on extending the R\'enyi divergence-based fully adaptive composition results by Feldman and Zrnic (2021). We also consider measuring the individual $(\varepsilon,\delta)$-privacy losses using the so-called privacy loss distributions. With the help of the Blackwell theorem, we can then make use of the RDP analysis to construct an approximative individual $(\varepsilon,\delta)$-accountant.
Differentially private partitioned variational inference
Sep 23, 2022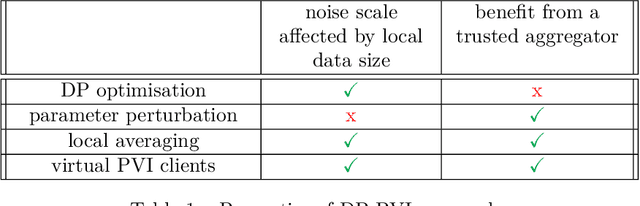
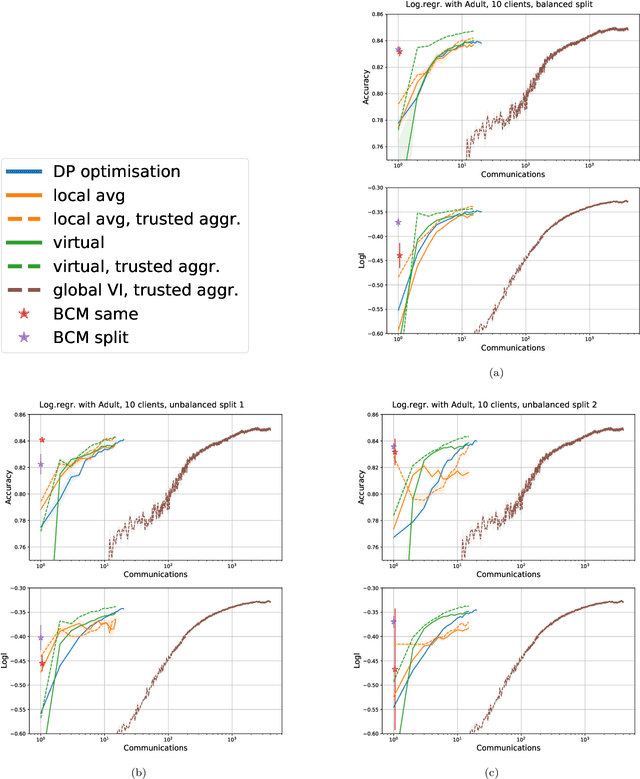
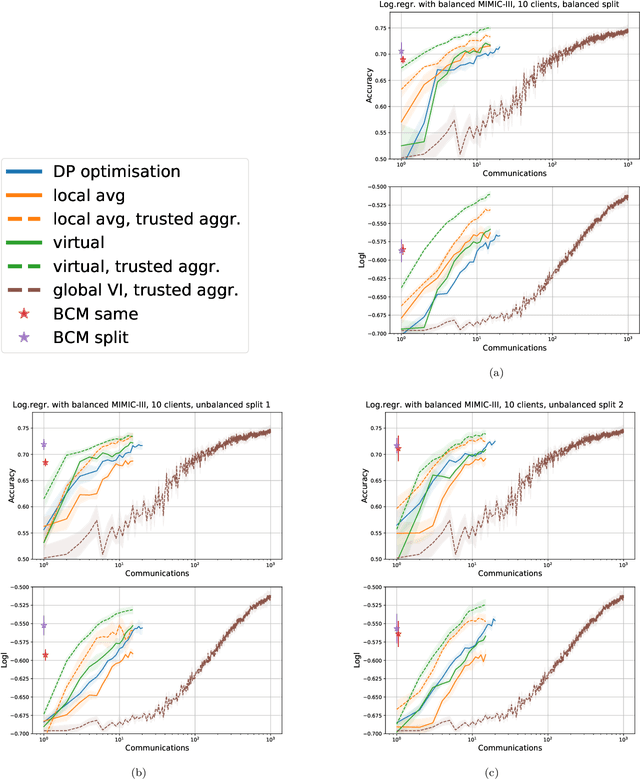

Learning a privacy-preserving model from distributed sensitive data is an increasingly important problem, often formulated in the federated learning context. Variational inference has recently been extended to the non-private federated learning setting via the partitioned variational inference algorithm. For privacy protection, the current gold standard is called differential privacy. Differential privacy guarantees privacy in a strong, mathematically clearly defined sense. In this paper, we present differentially private partitioned variational inference, the first general framework for learning a variational approximation to a Bayesian posterior distribution in the federated learning setting while minimising the number of communication rounds and providing differential privacy guarantees for data subjects. We propose three alternative implementations in the general framework, one based on perturbing local optimisation done by individual parties, and two based on perturbing global updates (one using a version of federated averaging, one adding virtual parties to the protocol), and compare their properties both theoretically and empirically. We show that perturbing the local optimisation works well with simple and complex models as long as each party has enough local data. However, the privacy is always guaranteed independently by each party. In contrast, perturbing the global updates works best with relatively simple models. Given access to suitable secure primitives, such as secure aggregation or secure shuffling, the performance can be improved by all parties guaranteeing privacy jointly.
Noise-Aware Statistical Inference with Differentially Private Synthetic Data
May 28, 2022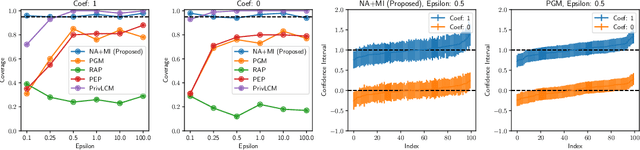
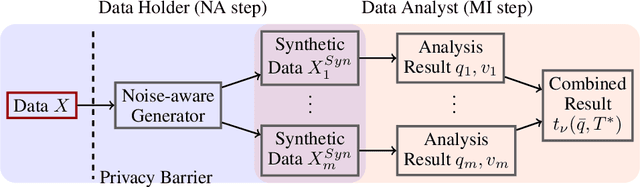
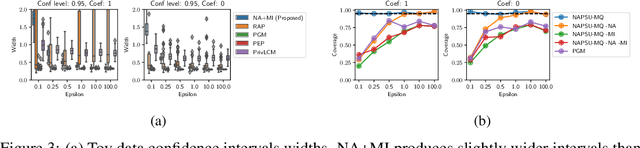
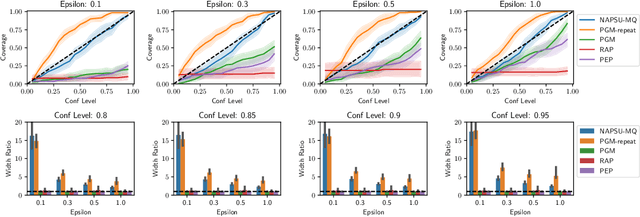
While generation of synthetic data under differential privacy (DP) has received a lot of attention in the data privacy community, analysis of synthetic data has received much less. Existing work has shown that simply analysing DP synthetic data as if it were real does not produce valid inferences of population-level quantities. For example, confidence intervals become too narrow, which we demonstrate with a simple experiment. We tackle this problem by combining synthetic data analysis techniques from the field of multiple imputation, and synthetic data generation using noise-aware Bayesian modeling into a pipeline NA+MI that allows computing accurate uncertainty estimates for population-level quantities from DP synthetic data. To implement NA+MI for discrete data generation from marginal queries, we develop a novel noise-aware synthetic data generation algorithm NAPSU-MQ using the principle of maximum entropy. Our experiments demonstrate that the pipeline is able to produce accurate confidence intervals from DP synthetic data. The intervals become wider with tighter privacy to accurately capture the additional uncertainty stemming from DP noise.
Locally Differentially Private Bayesian Inference
Oct 27, 2021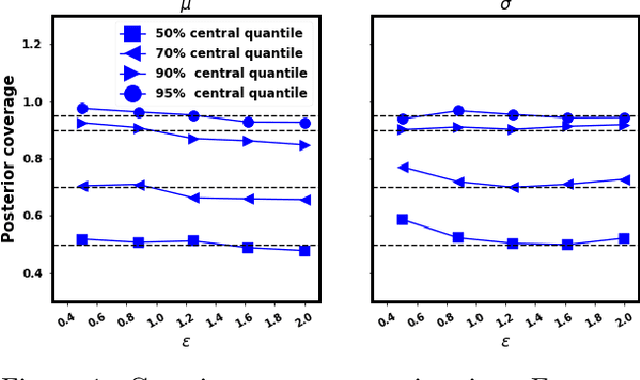
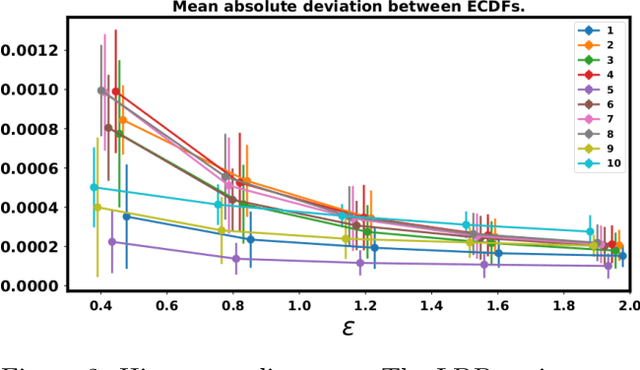
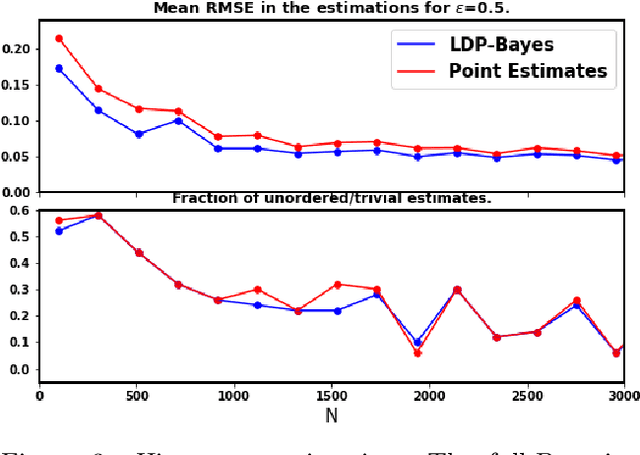
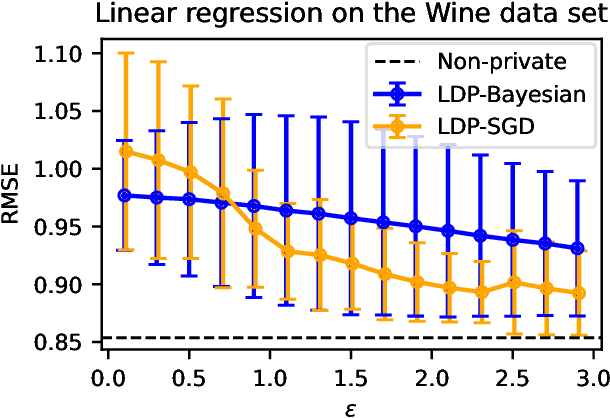
In recent years, local differential privacy (LDP) has emerged as a technique of choice for privacy-preserving data collection in several scenarios when the aggregator is not trustworthy. LDP provides client-side privacy by adding noise at the user's end. Thus, clients need not rely on the trustworthiness of the aggregator. In this work, we provide a noise-aware probabilistic modeling framework, which allows Bayesian inference to take into account the noise added for privacy under LDP, conditioned on locally perturbed observations. Stronger privacy protection (compared to the central model) provided by LDP protocols comes at a much harsher privacy-utility trade-off. Our framework tackles several computational and statistical challenges posed by LDP for accurate uncertainty quantification under Bayesian settings. We demonstrate the efficacy of our framework in parameter estimation for univariate and multi-variate distributions as well as logistic and linear regression.
Tight Accounting in the Shuffle Model of Differential Privacy
Jun 01, 2021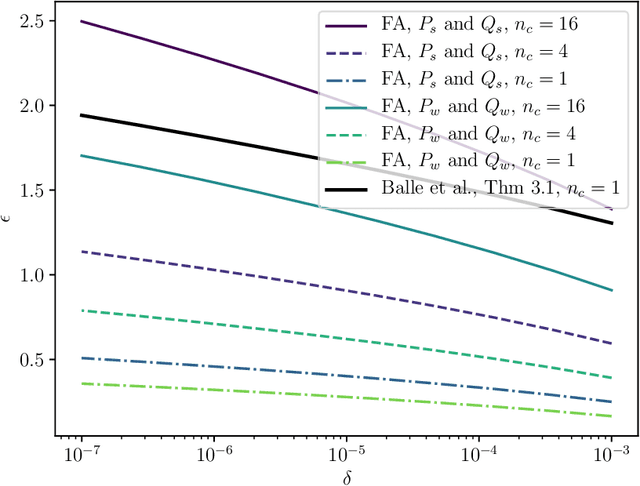
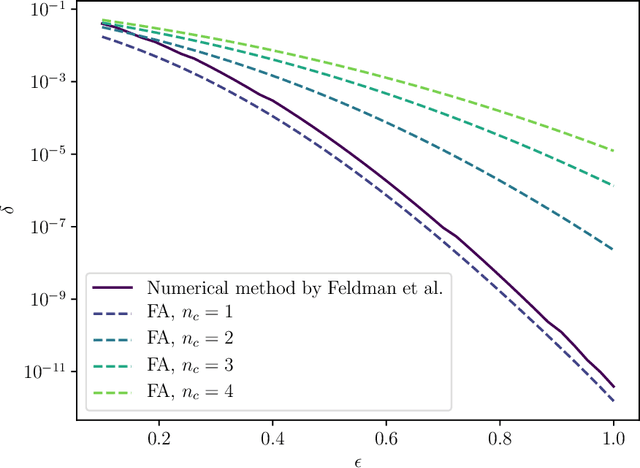
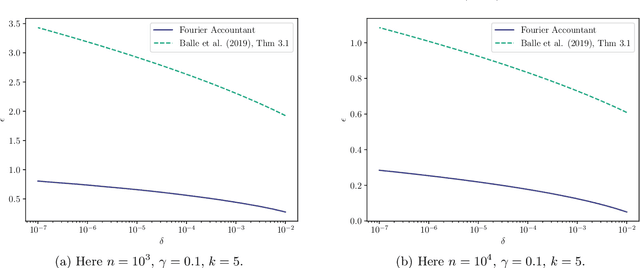
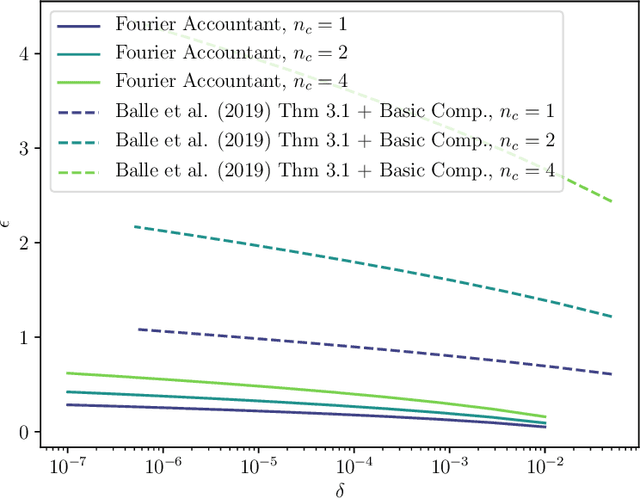
Shuffle model of differential privacy is a novel distributed privacy model based on a combination of local privacy mechanisms and a trusted shuffler. It has been shown that the additional randomisation provided by the shuffler improves privacy bounds compared to the purely local mechanisms. Accounting tight bounds, especially for multi-message protocols, is complicated by the complexity brought by the shuffler. The recently proposed Fourier Accountant for evaluating $(\varepsilon,\delta)$-differential privacy guarantees has been shown to give tighter bounds than commonly used methods for non-adaptive compositions of various complex mechanisms. In this paper we show how to compute tight privacy bounds using the Fourier Accountant for multi-message versions of several ubiquitous mechanisms in the shuffle model and demonstrate looseness of the existing bounds in the literature.