 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNA-TEQ: An Adaptive Exponential Quantization of Tensors for DNN Inference
Jun 28, 2023Quantization is commonly used in Deep Neural Networks (DNNs) to reduce the storage and computational complexity by decreasing the arithmetical precision of activations and weights, a.k.a. tensors. Efficient hardware architectures employ linear quantization to enable the deployment of recent DNNs onto embedded systems and mobile devices. However, linear uniform quantization cannot usually reduce the numerical precision to less than 8 bits without sacrificing high performance in terms of model accuracy. The performance loss is due to the fact that tensors do not follow uniform distributions. In this paper, we show that a significant amount of tensors fit into an exponential distribution. Then, we propose DNA-TEQ to exponentially quantize DNN tensors with an adaptive scheme that achieves the best trade-off between numerical precision and accuracy loss. The experimental results show that DNA-TEQ provides a much lower quantization bit-width compared to previous proposals, resulting in an average compression ratio of 40% over the linear INT8 baseline, with negligible accuracy loss and without retraining the DNNs. Besides, DNA-TEQ leads the way in performing dot-product operations in the exponential domain, which saves 66% of energy consumption on average for a set of widely used DNNs.
Exploiting Kernel Compression on BNNs
Dec 01, 2022



Binary Neural Networks (BNNs) are showing tremendous success on realistic image classification tasks. Notably, their accuracy is similar to the state-of-the-art accuracy obtained by full-precision models tailored to edge devices. In this regard, BNNs are very amenable to edge devices since they employ 1-bit to store the inputs and weights, and thus, their storage requirements are low. Also, BNNs computations are mainly done using xnor and pop-counts operations which are implemented very efficiently using simple hardware structures. Nonetheless, supporting BNNs efficiently on mobile CPUs is far from trivial since their benefits are hindered by frequent memory accesses to load weights and inputs. In BNNs, a weight or an input is stored using one bit, and aiming to increase storage and computation efficiency, several of them are packed together as a sequence of bits. In this work, we observe that the number of unique sequences representing a set of weights is typically low. Also, we have seen that during the evaluation of a BNN layer, a small group of unique sequences is employed more frequently than others. Accordingly, we propose exploiting this observation by using Huffman Encoding to encode the bit sequences and then using an indirection table to decode them during the BNN evaluation. Also, we propose a clustering scheme to identify the most common sequences of bits and replace the less common ones with some similar common sequences. Hence, we decrease the storage requirements and memory accesses since common sequences are encoded with fewer bits. We extend a mobile CPU by adding a small hardware structure that can efficiently cache and decode the compressed sequence of bits. We evaluate our scheme using the ReAacNet model with the Imagenet dataset. Our experimental results show that our technique can reduce memory requirement by 1.32x and improve performance by 1.35x.
Dynamic Sampling Rate: Harnessing Frame Coherence in Graphics Applications for Energy-Efficient GPUs
Feb 21, 2022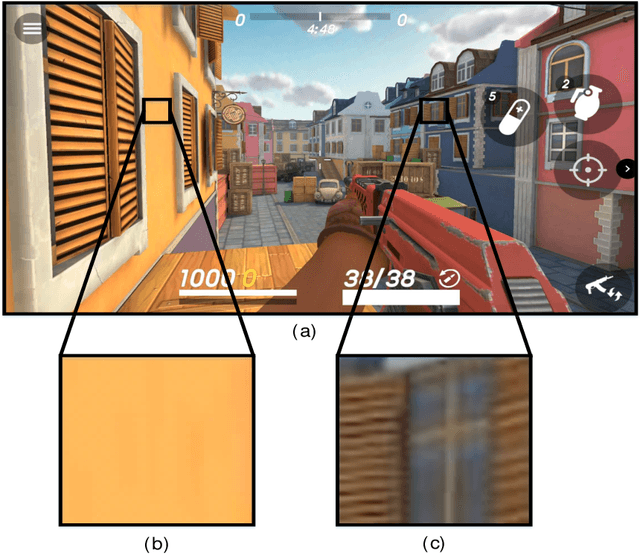
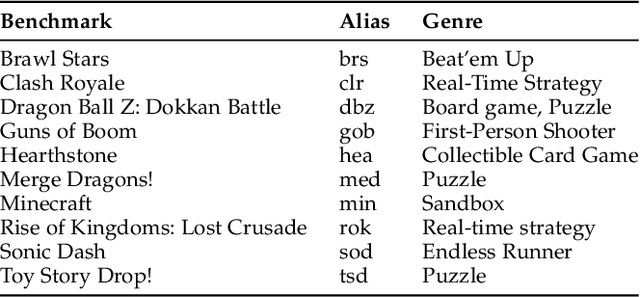
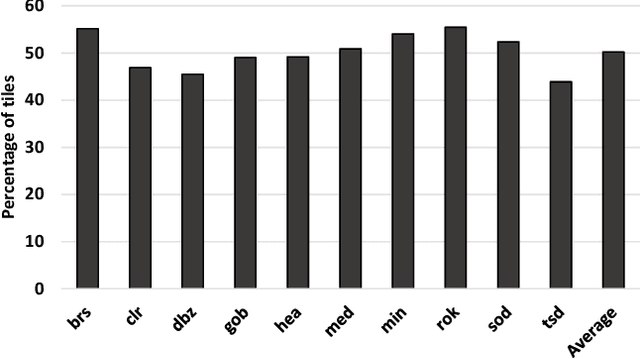
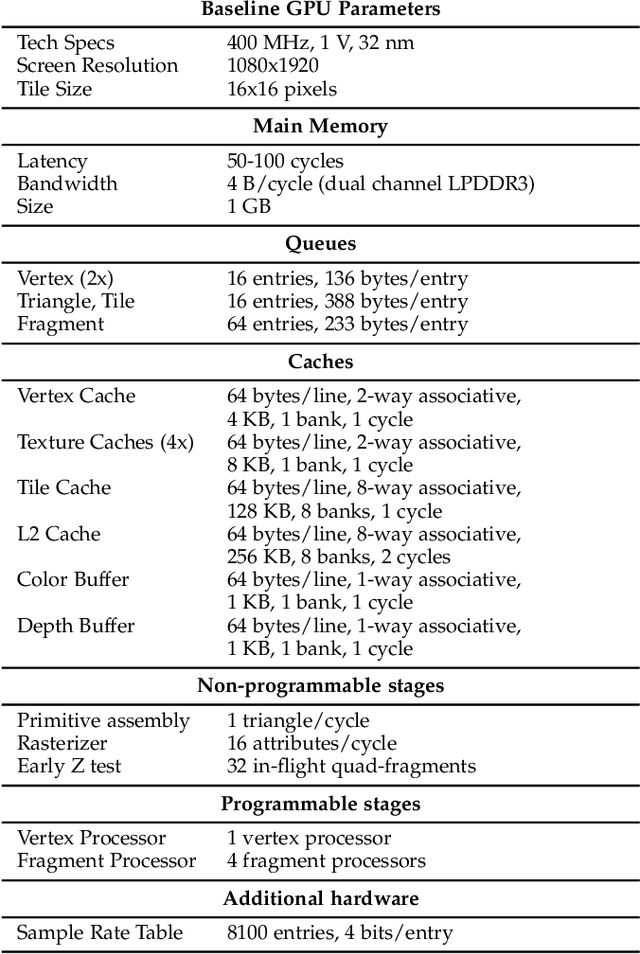
In real-time rendering, a 3D scene is modelled with meshes of triangles that the GPU projects to the screen. They are discretized by sampling each triangle at regular space intervals to generate fragments which are then added texture and lighting effects by a shader program. Realistic scenes require detailed geometric models, complex shaders, high-resolution displays and high screen refreshing rates, which all come at a great compute time and energy cost. This cost is often dominated by the fragment shader, which runs for each sampled fragment. Conventional GPUs sample the triangles once per pixel, however, there are many screen regions containing low variation that produce identical fragments and could be sampled at lower than pixel-rate with no loss in quality. Additionally, as temporal frame coherence makes consecutive frames very similar, such variations are usually maintained from frame to frame. This work proposes Dynamic Sampling Rate (DSR), a novel hardware mechanism to reduce redundancy and improve the energy efficiency in graphics applications. DSR analyzes the spatial frequencies of the scene once it has been rendered. Then, it leverages the temporal coherence in consecutive frames to decide, for each region of the screen, the lowest sampling rate to employ in the next frame that maintains image quality. We evaluate the performance of a state-of-the-art mobile GPU architecture extended with DSR for a wide variety of applications. Experimental results show that DSR is able to remove most of the redundancy inherent in the color computations at fragment granularity, which brings average speedups of 1.68x and energy savings of 40%.
Saving RNN Computations with a Neuron-Level Fuzzy Memoization Scheme
Feb 14, 2022Recurrent Neural Networks (RNNs) are a key technology for applications such as automatic speech recognition or machine translation. Unlike conventional feed-forward DNNs, RNNs remember past information to improve the accuracy of future predictions and, therefore, they are very effective for sequence processing problems. For each application run, recurrent layers are executed many times for processing a potentially large sequence of inputs (words, images, audio frames, etc.). In this paper, we observe that the output of a neuron exhibits small changes in consecutive invocations.~We exploit this property to build a neuron-level fuzzy memoization scheme, which dynamically caches each neuron's output and reuses it whenever it is predicted that the current output will be similar to a previously computed result, avoiding in this way the output computations. The main challenge in this scheme is determining whether the new neuron's output for the current input in the sequence will be similar to a recently computed result. To this end, we extend the recurrent layer with a much simpler Bitwise Neural Network (BNN), and show that the BNN and RNN outputs are highly correlated: if two BNN outputs are very similar, the corresponding outputs in the original RNN layer are likely to exhibit negligible changes. The BNN provides a low-cost and effective mechanism for deciding when fuzzy memoization can be applied with a small impact on accuracy. We evaluate our memoization scheme on top of a state-of-the-art accelerator for RNNs, for a variety of different neural networks from multiple application domains. We show that our technique avoids more than 26.7\% of computations, resulting in 21\% energy savings and 1.4x speedup on average.
Mixture-of-Rookies: Saving DNN Computations by Predicting ReLU Outputs
Feb 10, 2022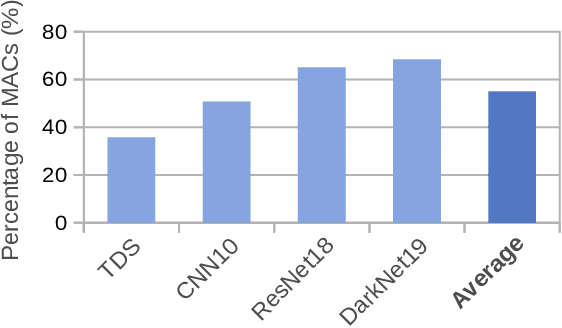
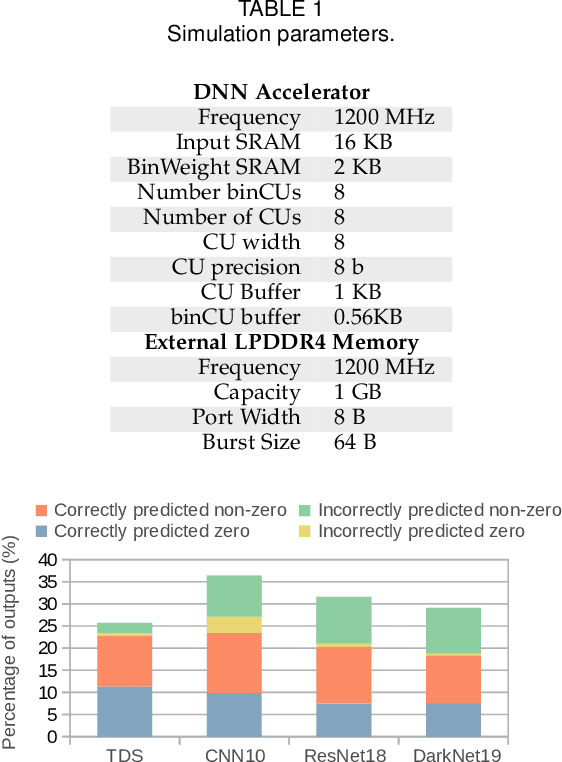
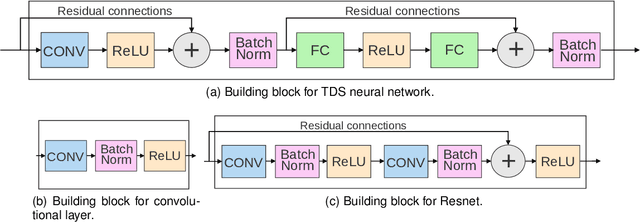
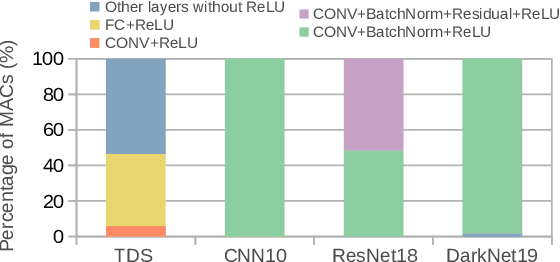
Deep Neural Networks (DNNs) are widely used in many applications domains. However, they require a vast amount of computations and memory accesses to deliver outstanding accuracy. In this paper, we propose a scheme to predict whether the output of each ReLu activated neuron will be a zero or a positive number in order to skip the computation of those neurons that will likely output a zero. Our predictor, named Mixture-of-Rookies, combines two inexpensive components. The first one exploits the high linear correlation between binarized (1-bit) and full-precision (8-bit) dot products, whereas the second component clusters together neurons that tend to output zero at the same time. We propose a novel clustering scheme based on the analysis of angles, as the sign of the dot product of two vectors depends on the cosine of the angle between them. We implement our hybrid zero output predictor on top of a state-of-the-art DNN accelerator. Experimental results show that our scheme introduces a small area overhead of 5.3% while achieving a speedup of 1.2x and reducing energy consumption by 16.5% on average for a set of diverse DNNs.
ASRPU: A Programmable Accelerator for Low-Power Automatic Speech Recognition
Feb 10, 2022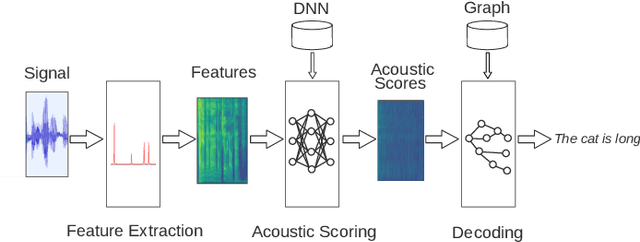

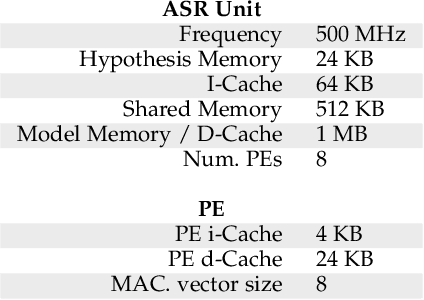
The outstanding accuracy achieved by modern Automatic Speech Recognition (ASR) systems is enabling them to quickly become a mainstream technology. ASR is essential for many applications, such as speech-based assistants, dictation systems and real-time language translation. However, highly accurate ASR systems are computationally expensive, requiring on the order of billions of arithmetic operations to decode each second of audio, which conflicts with a growing interest in deploying ASR on edge devices. On these devices, hardware acceleration is key for achieving acceptable performance. However, ASR is a rich and fast-changing field, and thus, any overly specialized hardware accelerator may quickly become obsolete. In this paper, we tackle those challenges by proposing ASRPU, a programmable accelerator for on-edge ASR. ASRPU contains a pool of general-purpose cores that execute small pieces of parallel code. Each of these programs computes one part of the overall decoder (e.g. a layer in a neural network). The accelerator automates some carefully chosen parts of the decoder to simplify the programming without sacrificing generality. We provide an analysis of a modern ASR system implemented on ASRPU and show that this architecture can achieve real-time decoding with a very low power budget.
A Survey of Near-Data Processing Architectures for Neural Networks
Dec 23, 2021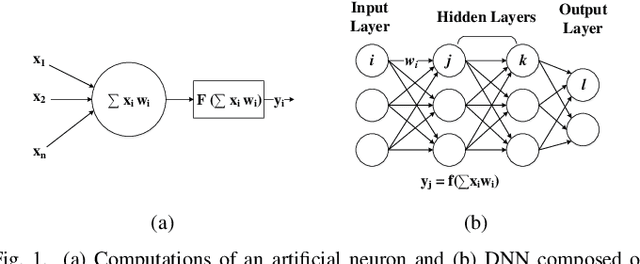
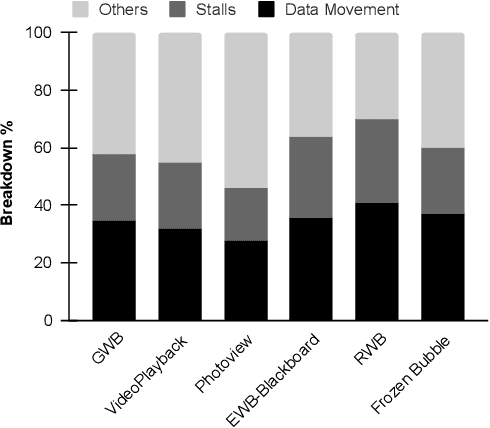
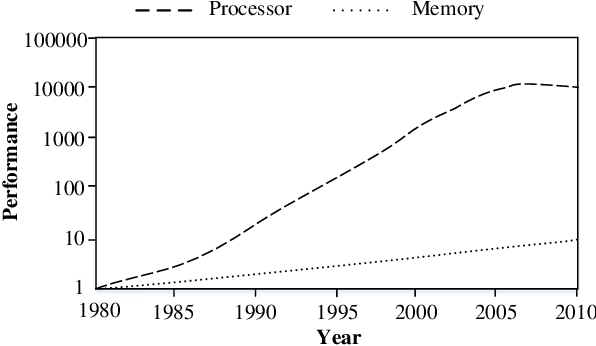
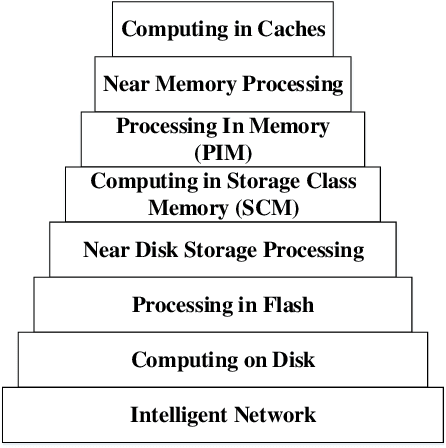
Data-intensive workloads and applications, such as machine learning (ML), are fundamentally limited by traditional computing systems based on the von-Neumann architecture. As data movement operations and energy consumption become key bottlenecks in the design of computing systems, the interest in unconventional approaches such as Near-Data Processing (NDP), machine learning, and especially neural network (NN)-based accelerators has grown significantly. Emerging memory technologies, such as ReRAM and 3D-stacked, are promising for efficiently architecting NDP-based accelerators for NN due to their capabilities to work as both: High-density/low-energy storage and in/near-memory computation/search engine. In this paper, we present a survey of techniques for designing NDP architectures for NN. By classifying the techniques based on the memory technology employed, we underscore their similarities and differences. Finally, we discuss open challenges and future perspectives that need to be explored in order to improve and extend the adoption of NDP architectures for future computing platforms. This paper will be valuable for computer architects, chip designers and researchers in the area of machine learning.
Exploiting Beam Search Confidence for Energy-Efficient Speech Recognition
Jan 22, 2021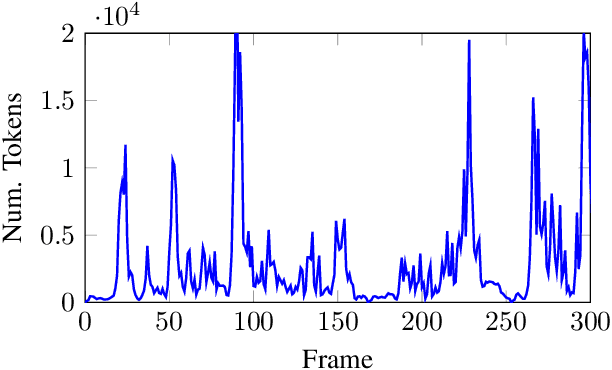
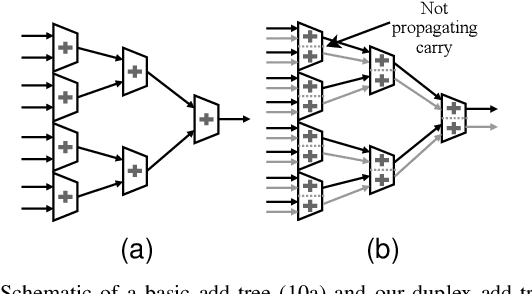
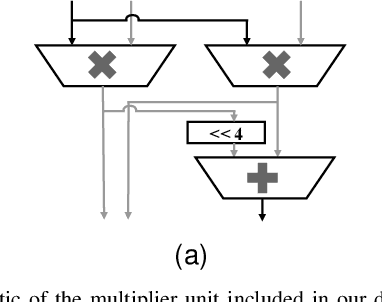
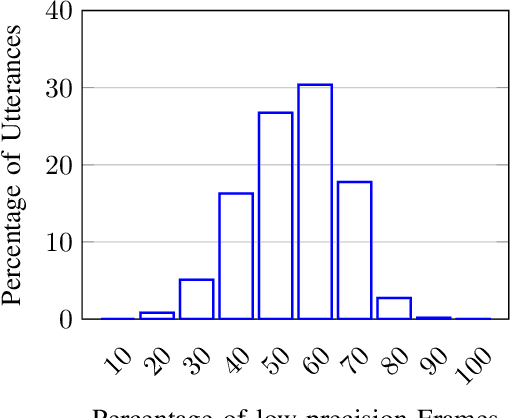
With computers getting more and more powerful and integrated in our daily lives, the focus is increasingly shifting towards more human-friendly interfaces, making Automatic Speech Recognition (ASR) a central player as the ideal means of interaction with machines. Consequently, interest in speech technology has grown in the last few years, with more systems being proposed and higher accuracy levels being achieved, even surpassing \textit{Human Accuracy}. While ASR systems become increasingly powerful, the computational complexity also increases, and the hardware support have to keep pace. In this paper, we propose a technique to improve the energy-efficiency and performance of ASR systems, focusing on low-power hardware for edge devices. We focus on optimizing the DNN-based Acoustic Model evaluation, as we have observed it to be the main bottleneck in state-of-the-art ASR systems, by leveraging run-time information from the Beam Search. By doing so, we reduce energy and execution time of the acoustic model evaluation by 25.6% and 25.9%, respectively, with negligible accuracy loss.