 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture-of-Rookies: Saving DNN Computations by Predicting ReLU Outputs
Feb 10, 2022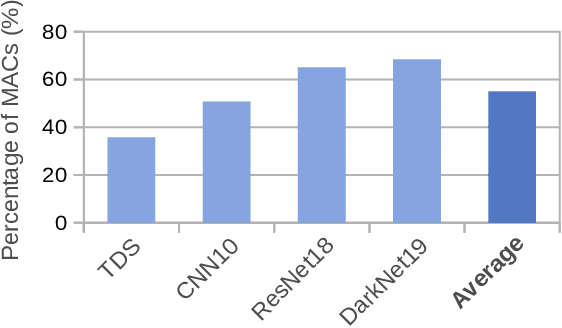
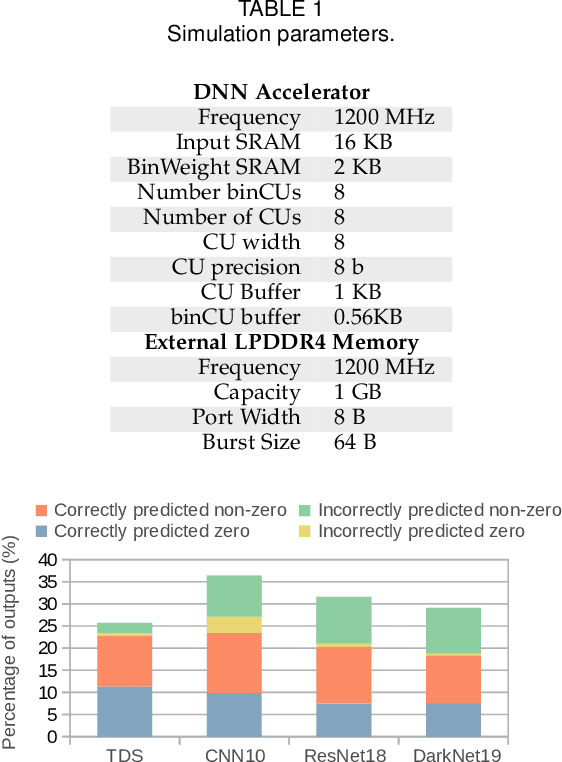
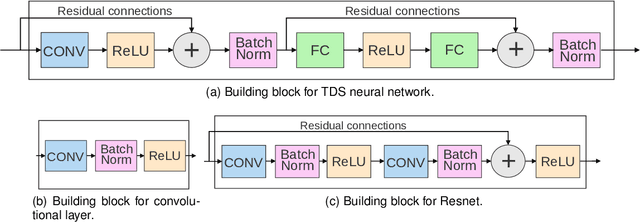
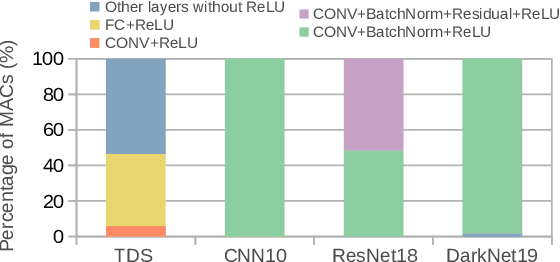
Deep Neural Networks (DNNs) are widely used in many applications domains. However, they require a vast amount of computations and memory accesses to deliver outstanding accuracy. In this paper, we propose a scheme to predict whether the output of each ReLu activated neuron will be a zero or a positive number in order to skip the computation of those neurons that will likely output a zero. Our predictor, named Mixture-of-Rookies, combines two inexpensive components. The first one exploits the high linear correlation between binarized (1-bit) and full-precision (8-bit) dot products, whereas the second component clusters together neurons that tend to output zero at the same time. We propose a novel clustering scheme based on the analysis of angles, as the sign of the dot product of two vectors depends on the cosine of the angle between them. We implement our hybrid zero output predictor on top of a state-of-the-art DNN accelerator. Experimental results show that our scheme introduces a small area overhead of 5.3% while achieving a speedup of 1.2x and reducing energy consumption by 16.5% on average for a set of diverse DNNs.
ASRPU: A Programmable Accelerator for Low-Power Automatic Speech Recognition
Feb 10, 2022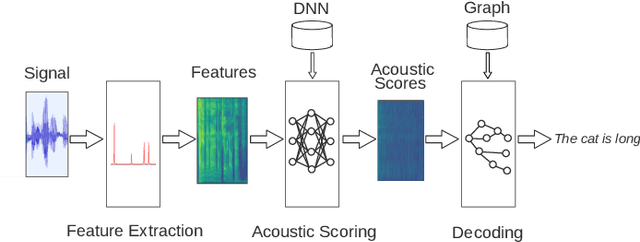

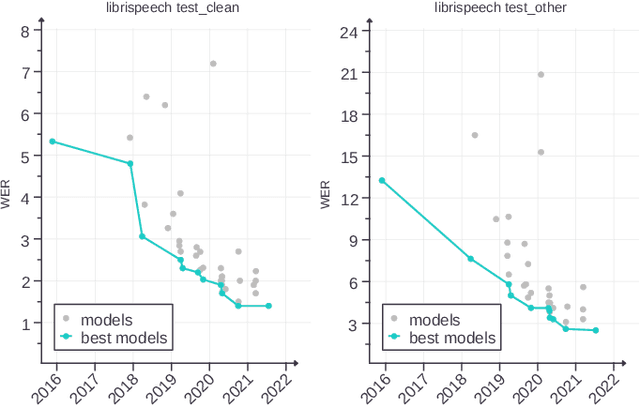
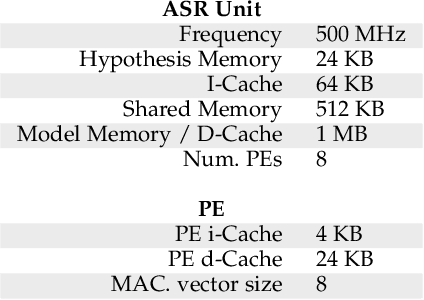
The outstanding accuracy achieved by modern Automatic Speech Recognition (ASR) systems is enabling them to quickly become a mainstream technology. ASR is essential for many applications, such as speech-based assistants, dictation systems and real-time language translation. However, highly accurate ASR systems are computationally expensive, requiring on the order of billions of arithmetic operations to decode each second of audio, which conflicts with a growing interest in deploying ASR on edge devices. On these devices, hardware acceleration is key for achieving acceptable performance. However, ASR is a rich and fast-changing field, and thus, any overly specialized hardware accelerator may quickly become obsolete. In this paper, we tackle those challenges by proposing ASRPU, a programmable accelerator for on-edge ASR. ASRPU contains a pool of general-purpose cores that execute small pieces of parallel code. Each of these programs computes one part of the overall decoder (e.g. a layer in a neural network). The accelerator automates some carefully chosen parts of the decoder to simplify the programming without sacrificing generality. We provide an analysis of a modern ASR system implemented on ASRPU and show that this architecture can achieve real-time decoding with a very low power budget.
Exploiting Beam Search Confidence for Energy-Efficient Speech Recognition
Jan 22, 2021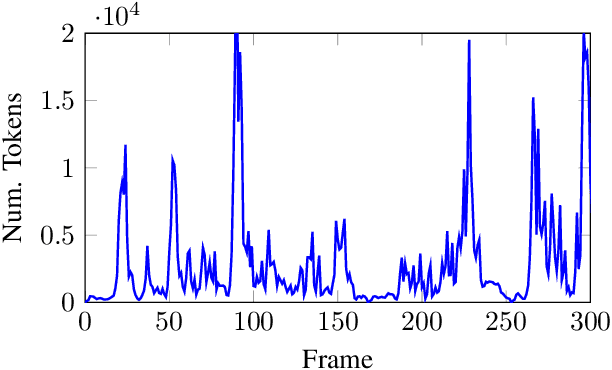
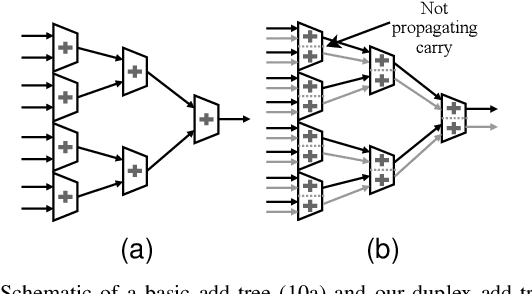
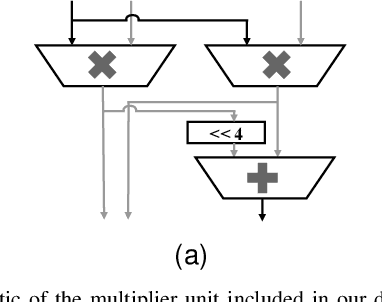
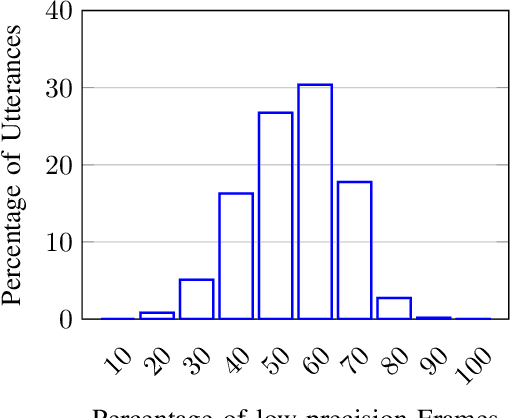
With computers getting more and more powerful and integrated in our daily lives, the focus is increasingly shifting towards more human-friendly interfaces, making Automatic Speech Recognition (ASR) a central player as the ideal means of interaction with machines. Consequently, interest in speech technology has grown in the last few years, with more systems being proposed and higher accuracy levels being achieved, even surpassing \textit{Human Accuracy}. While ASR systems become increasingly powerful, the computational complexity also increases, and the hardware support have to keep pace. In this paper, we propose a technique to improve the energy-efficiency and performance of ASR systems, focusing on low-power hardware for edge devices. We focus on optimizing the DNN-based Acoustic Model evaluation, as we have observed it to be the main bottleneck in state-of-the-art ASR systems, by leveraging run-time information from the Beam Search. By doing so, we reduce energy and execution time of the acoustic model evaluation by 25.6% and 25.9%, respectively, with negligible accuracy loss.