 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNA-TEQ: An Adaptive Exponential Quantization of Tensors for DNN Inference
Jun 28, 2023Quantization is commonly used in Deep Neural Networks (DNNs) to reduce the storage and computational complexity by decreasing the arithmetical precision of activations and weights, a.k.a. tensors. Efficient hardware architectures employ linear quantization to enable the deployment of recent DNNs onto embedded systems and mobile devices. However, linear uniform quantization cannot usually reduce the numerical precision to less than 8 bits without sacrificing high performance in terms of model accuracy. The performance loss is due to the fact that tensors do not follow uniform distributions. In this paper, we show that a significant amount of tensors fit into an exponential distribution. Then, we propose DNA-TEQ to exponentially quantize DNN tensors with an adaptive scheme that achieves the best trade-off between numerical precision and accuracy loss. The experimental results show that DNA-TEQ provides a much lower quantization bit-width compared to previous proposals, resulting in an average compression ratio of 40% over the linear INT8 baseline, with negligible accuracy loss and without retraining the DNNs. Besides, DNA-TEQ leads the way in performing dot-product operations in the exponential domain, which saves 66% of energy consumption on average for a set of widely used DNNs.
A Survey of Near-Data Processing Architectures for Neural Networks
Dec 23, 2021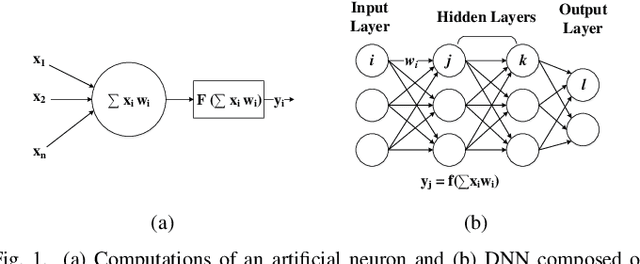
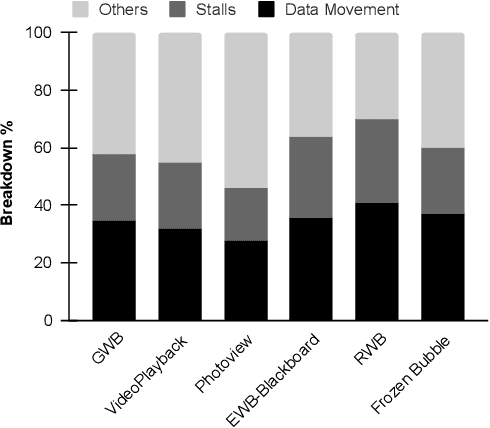
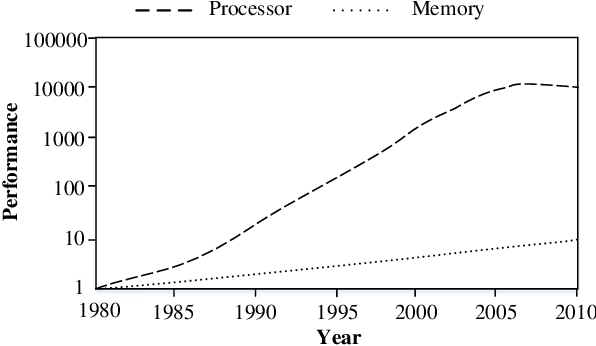
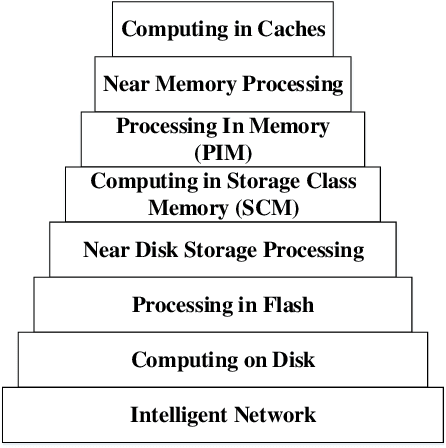
Data-intensive workloads and applications, such as machine learning (ML), are fundamentally limited by traditional computing systems based on the von-Neumann architecture. As data movement operations and energy consumption become key bottlenecks in the design of computing systems, the interest in unconventional approaches such as Near-Data Processing (NDP), machine learning, and especially neural network (NN)-based accelerators has grown significantly. Emerging memory technologies, such as ReRAM and 3D-stacked, are promising for efficiently architecting NDP-based accelerators for NN due to their capabilities to work as both: High-density/low-energy storage and in/near-memory computation/search engine. In this paper, we present a survey of techniques for designing NDP architectures for NN. By classifying the techniques based on the memory technology employed, we underscore their similarities and differences. Finally, we discuss open challenges and future perspectives that need to be explored in order to improve and extend the adoption of NDP architectures for future computing platforms. This paper will be valuable for computer architects, chip designers and researchers in the area of machine learning.
CREW: Computation Reuse and Efficient Weight Storage for Hardware-accelerated MLPs and RNNs
Jul 20, 2021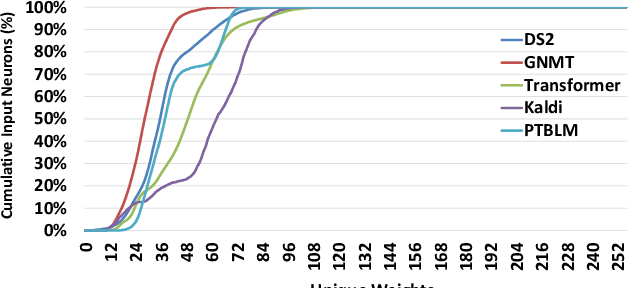
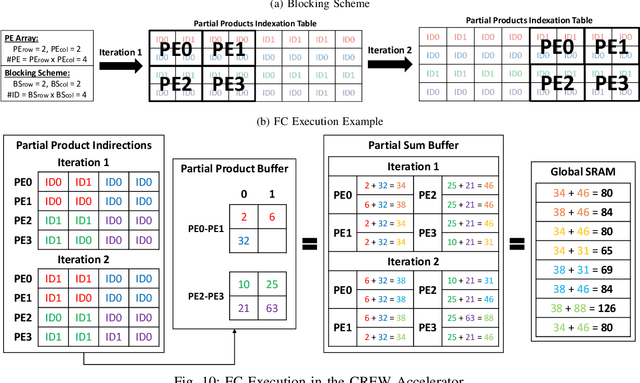
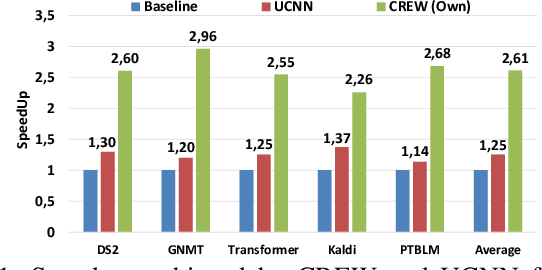
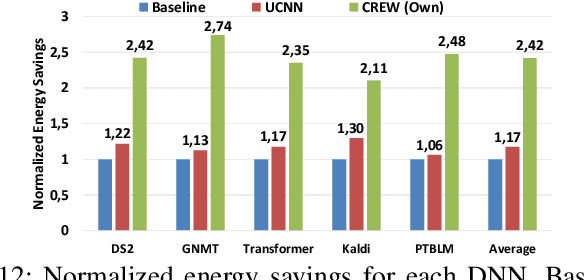
Deep Neural Networks (DNNs) have achieved tremendous success for cognitive applications. The core operation in a DNN is the dot product between quantized inputs and weights. Prior works exploit the weight/input repetition that arises due to quantization to avoid redundant computations in Convolutional Neural Networks (CNNs). However, in this paper we show that their effectiveness is severely limited when applied to Fully-Connected (FC) layers, which are commonly used in state-of-the-art DNNs, as it is the case of modern Recurrent Neural Networks (RNNs) and Transformer models. To improve energy-efficiency of FC computation we present CREW, a hardware accelerator that implements Computation Reuse and an Efficient Weight Storage mechanism to exploit the large number of repeated weights in FC layers. CREW first performs the multiplications of the unique weights by their respective inputs and stores the results in an on-chip buffer. The storage requirements are modest due to the small number of unique weights and the relatively small size of the input compared to convolutional layers. Next, CREW computes each output by fetching and adding its required products. To this end, each weight is replaced offline by an index in the buffer of unique products. Indices are typically smaller than the quantized weights, since the number of unique weights for each input tends to be much lower than the range of quantized weights, which reduces storage and memory bandwidth requirements. Overall, CREW greatly reduces the number of multiplications and provides significant savings in model memory footprint and memory bandwidth usage. We evaluate CREW on a diverse set of modern DNNs. On average, CREW provides 2.61x speedup and 2.42x energy savings over a TPU-like accelerator. Compared to UCNN, a state-of-art computation reuse technique, CREW achieves 2.10x speedup and 2.08x energy savings on average.
(Pen-) Ultimate DNN Pruning
Jun 06, 2019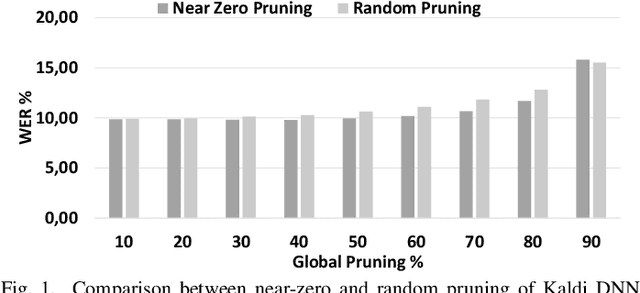
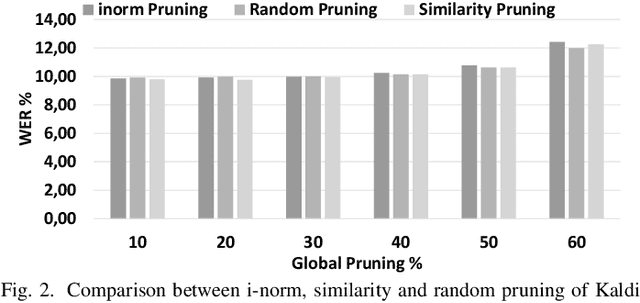
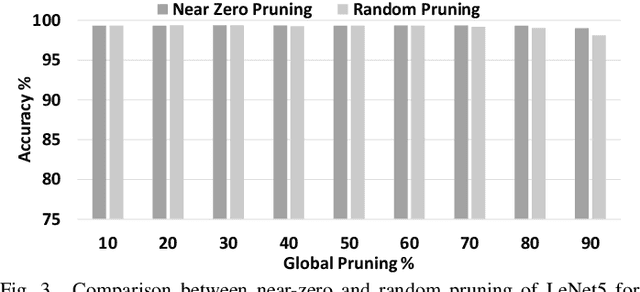
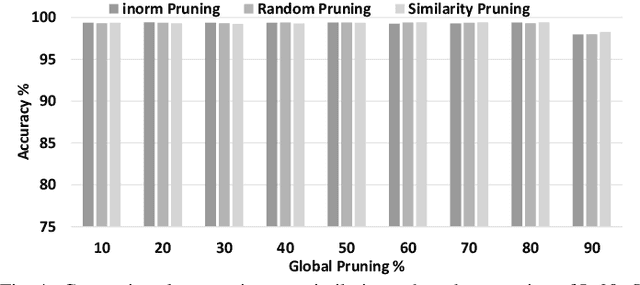
DNN pruning reduces memory footprint and computational work of DNN-based solutions to improve performance and energy-efficiency. An effective pruning scheme should be able to systematically remove connections and/or neurons that are unnecessary or redundant, reducing the DNN size without any loss in accuracy. In this paper we show that prior pruning schemes require an extremely time-consuming iterative process that requires retraining the DNN many times to tune the pruning hyperparameters. We propose a DNN pruning scheme based on Principal Component Analysis and relative importance of each neuron's connection that automatically finds the optimized DNN in one shot without requiring hand-tuning of multiple parameters.