 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Kernel Compression on BNNs
Dec 01, 2022



Binary Neural Networks (BNNs) are showing tremendous success on realistic image classification tasks. Notably, their accuracy is similar to the state-of-the-art accuracy obtained by full-precision models tailored to edge devices. In this regard, BNNs are very amenable to edge devices since they employ 1-bit to store the inputs and weights, and thus, their storage requirements are low. Also, BNNs computations are mainly done using xnor and pop-counts operations which are implemented very efficiently using simple hardware structures. Nonetheless, supporting BNNs efficiently on mobile CPUs is far from trivial since their benefits are hindered by frequent memory accesses to load weights and inputs. In BNNs, a weight or an input is stored using one bit, and aiming to increase storage and computation efficiency, several of them are packed together as a sequence of bits. In this work, we observe that the number of unique sequences representing a set of weights is typically low. Also, we have seen that during the evaluation of a BNN layer, a small group of unique sequences is employed more frequently than others. Accordingly, we propose exploiting this observation by using Huffman Encoding to encode the bit sequences and then using an indirection table to decode them during the BNN evaluation. Also, we propose a clustering scheme to identify the most common sequences of bits and replace the less common ones with some similar common sequences. Hence, we decrease the storage requirements and memory accesses since common sequences are encoded with fewer bits. We extend a mobile CPU by adding a small hardware structure that can efficiently cache and decode the compressed sequence of bits. We evaluate our scheme using the ReAacNet model with the Imagenet dataset. Our experimental results show that our technique can reduce memory requirement by 1.32x and improve performance by 1.35x.
E-BATCH: Energy-Efficient and High-Throughput RNN Batching
Sep 22, 2020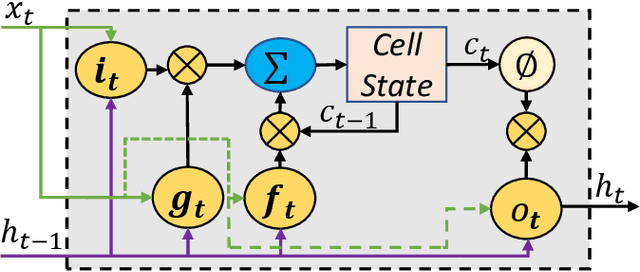
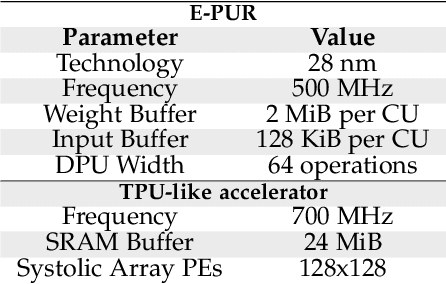
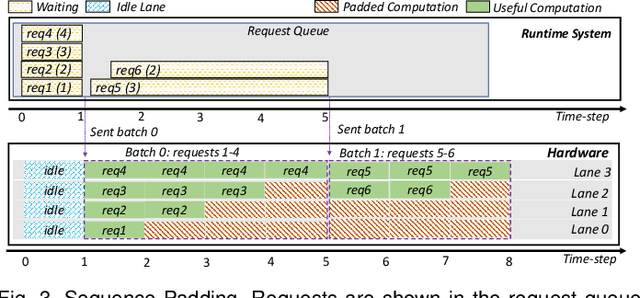
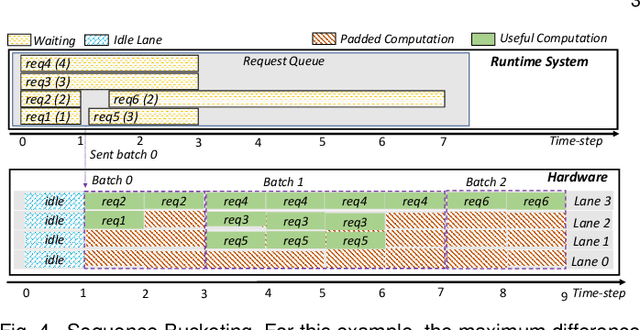
Recurrent Neural Network (RNN) inference exhibits low hardware utilization due to the strict data dependencies across time-steps. Batching multiple requests can increase throughput. However, RNN batching requires a large amount of padding since the batched input sequences may largely differ in length. Schemes that dynamically update the batch every few time-steps avoid padding. However, they require executing different RNN layers in a short timespan, decreasing energy efficiency. Hence, we propose E-BATCH, a low-latency and energy-efficient batching scheme tailored to RNN accelerators. It consists of a runtime system and effective hardware support. The runtime concatenates multiple sequences to create large batches, resulting in substantial energy savings. Furthermore, the accelerator notifies it when the evaluation of a sequence is done, so that a new sequence can be immediately added to a batch, thus largely reducing the amount of padding. E-BATCH dynamically controls the number of time-steps evaluated per batch to achieve the best trade-off between latency and energy efficiency for the given hardware platform. We evaluate E-BATCH on top of E-PUR and TPU. In E-PUR, E-BATCH improves throughput by 1.8x and energy-efficiency by 3.6x, whereas in TPU, it improves throughput by 2.1x and energy-efficiency by 1.6x, over the state-of-the-art.