 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINTERSPEECH 2009 Emotion Challenge Revisited: Benchmarking 15 Years of Progress in Speech Emotion Recognition
Jun 10, 2024We revisit the INTERSPEECH 2009 Emotion Challenge -- the first ever speech emotion recognition (SER) challenge -- and evaluate a series of deep learning models that are representative of the major advances in SER research in the time since then. We start by training each model using a fixed set of hyperparameters, and further fine-tune the best-performing models of that initial setup with a grid search. Results are always reported on the official test set with a separate validation set only used for early stopping. Most models score below or close to the official baseline, while they marginally outperform the original challenge winners after hyperparameter tuning. Our work illustrates that, despite recent progress, FAU-AIBO remains a very challenging benchmark. An interesting corollary is that newer methods do not consistently outperform older ones, showing that progress towards `solving' SER is not necessarily monotonic.
Sustained Vowels for Pre- vs Post-Treatment COPD Classification
Jun 10, 2024


Chronic obstructive pulmonary disease (COPD) is a serious inflammatory lung disease affecting millions of people around the world. Due to an obstructed airflow from the lungs, it also becomes manifest in patients' vocal behaviour. Of particular importance is the detection of an exacerbation episode, which marks an acute phase and often requires hospitalisation and treatment. Previous work has shown that it is possible to distinguish between a pre- and a post-treatment state using automatic analysis of read speech. In this contribution, we examine whether sustained vowels can provide a complementary lens for telling apart these two states. Using a cohort of 50 patients, we show that the inclusion of sustained vowels can improve performance to up to 79\% unweighted average recall, from a 71\% baseline using read speech. We further identify and interpret the most important acoustic features that characterise the manifestation of COPD in sustained vowels.
The ACM Multimedia 2023 Computational Paralinguistics Challenge: Emotion Share & Requests
May 01, 2023



The ACM Multimedia 2023 Computational Paralinguistics Challenge addresses two different problems for the first time in a research competition under well-defined conditions: In the Emotion Share Sub-Challenge, a regression on speech has to be made; and in the Requests Sub-Challenges, requests and complaints need to be detected. We describe the Sub-Challenges, baseline feature extraction, and classifiers based on the usual ComPaRE features, the auDeep toolkit, and deep feature extraction from pre-trained CNNs using the DeepSpectRum toolkit; in addition, wav2vec2 models are used.
HEAR4Health: A blueprint for making computer audition a staple of modern healthcare
Jan 25, 2023

Recent years have seen a rapid increase in digital medicine research in an attempt to transform traditional healthcare systems to their modern, intelligent, and versatile equivalents that are adequately equipped to tackle contemporary challenges. This has led to a wave of applications that utilise AI technologies; first and foremost in the fields of medical imaging, but also in the use of wearables and other intelligent sensors. In comparison, computer audition can be seen to be lagging behind, at least in terms of commercial interest. Yet, audition has long been a staple assistant for medical practitioners, with the stethoscope being the quintessential sign of doctors around the world. Transforming this traditional technology with the use of AI entails a set of unique challenges. We categorise the advances needed in four key pillars: Hear, corresponding to the cornerstone technologies needed to analyse auditory signals in real-life conditions; Earlier, for the advances needed in computational and data efficiency; Attentively, for accounting to individual differences and handling the longitudinal nature of medical data; and, finally, Responsibly, for ensuring compliance to the ethical standards accorded to the field of medicine.
Computational Charisma -- A Brick by Brick Blueprint for Building Charismatic Artificial Intelligence
Dec 31, 2022


Charisma is considered as one's ability to attract and potentially also influence others. Clearly, there can be considerable interest from an artificial intelligence's (AI) perspective to provide it with such skill. Beyond, a plethora of use cases opens up for computational measurement of human charisma, such as for tutoring humans in the acquisition of charisma, mediating human-to-human conversation, or identifying charismatic individuals in big social data. A number of models exist that base charisma on various dimensions, often following the idea that charisma is given if someone could and would help others. Examples include influence (could help) and affability (would help) in scientific studies or power (could help), presence, and warmth (both would help) as a popular concept. Modelling high levels in these dimensions for humanoid robots or virtual agents, seems accomplishable. Beyond, also automatic measurement appears quite feasible with the recent advances in the related fields of Affective Computing and Social Signal Processing. Here, we, thereforem present a blueprint for building machines that can appear charismatic, but also analyse the charisma of others. To this end, we first provide the psychological perspective including different models of charisma and behavioural cues of it. We then switch to conversational charisma in spoken language as an exemplary modality that is essential for human-human and human-computer conversations. The computational perspective then deals with the recognition and generation of charismatic behaviour by AI. This includes an overview of the state of play in the field and the aforementioned blueprint. We then name exemplary use cases of computational charismatic skills before switching to ethical aspects and concluding this overview and perspective on building charisma-enabled AI.
Proceedings of the ACII Affective Vocal Bursts Workshop and Competition 2022 (A-VB): Understanding a critically understudied modality of emotional expression
Oct 27, 2022This is the Proceedings of the ACII Affective Vocal Bursts Workshop and Competition (A-VB). A-VB was a workshop-based challenge that introduces the problem of understanding emotional expression in vocal bursts -- a wide range of non-verbal vocalizations that includes laughs, grunts, gasps, and much more. With affective states informing both mental and physical wellbeing, the core focus of the A-VB workshop was the broader discussion of current strategies in affective computing for modeling vocal emotional expression. Within this first iteration of the A-VB challenge, the participants were presented with four emotion-focused sub-challenges that utilize the large-scale and `in-the-wild' Hume-VB dataset. The dataset and the four sub-challenges draw attention to new innovations in emotion science as it pertains to vocal expression, addressing low- and high-dimensional theories of emotional expression, cultural variation, and `call types' (laugh, cry, sigh, etc.).
Distinguishing between pre- and post-treatment in the speech of patients with chronic obstructive pulmonary disease
Jul 26, 2022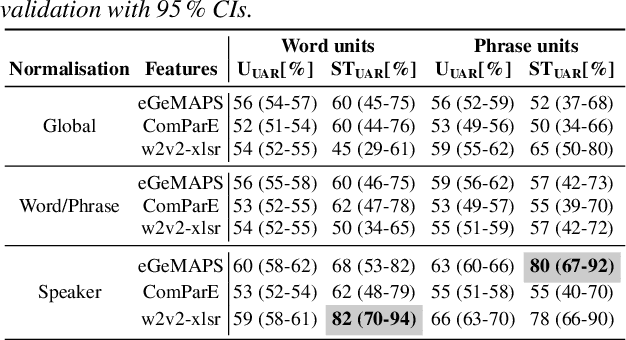
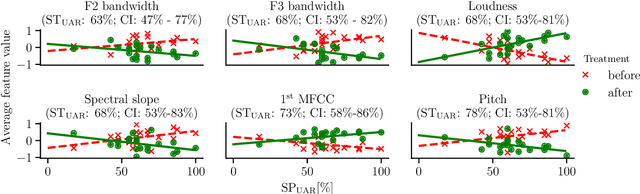
Chronic obstructive pulmonary disease (COPD) causes lung inflammation and airflow blockage leading to a variety of respiratory symptoms; it is also a leading cause of death and affects millions of individuals around the world. Patients often require treatment and hospitalisation, while no cure is currently available. As COPD predominantly affects the respiratory system, speech and non-linguistic vocalisations present a major avenue for measuring the effect of treatment. In this work, we present results on a new COPD dataset of 20 patients, showing that, by employing personalisation through speaker-level feature normalisation, we can distinguish between pre- and post-treatment speech with an unweighted average recall (UAR) of up to 82\,\% in (nested) leave-one-speaker-out cross-validation. We further identify the most important features and link them to pathological voice properties, thus enabling an auditory interpretation of treatment effects. Monitoring tools based on such approaches may help objectivise the clinical status of COPD patients and facilitate personalised treatment plans.
The ACII 2022 Affective Vocal Bursts Workshop & Competition: Understanding a critically understudied modality of emotional expression
Jul 07, 2022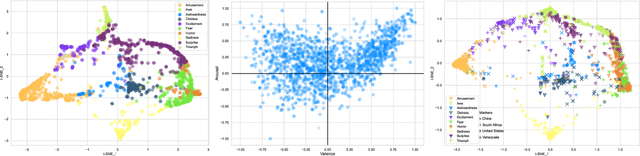
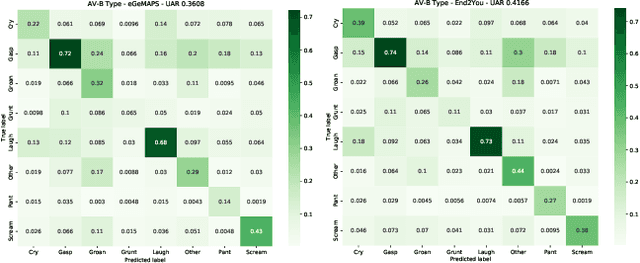
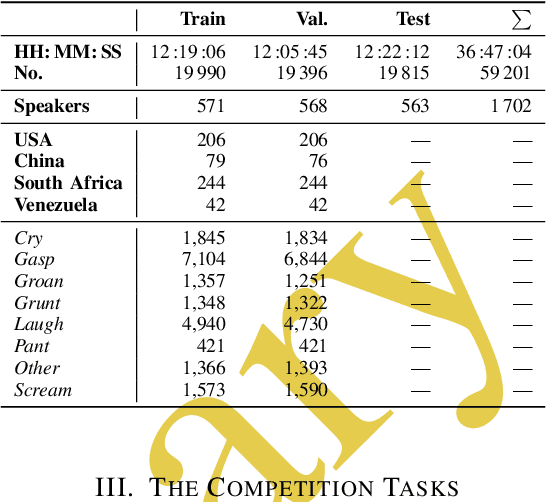
The ACII Affective Vocal Bursts Workshop & Competition is focused on understanding multiple affective dimensions of vocal bursts: laughs, gasps, cries, screams, and many other non-linguistic vocalizations central to the expression of emotion and to human communication more generally. This year's competition comprises four tracks using a large-scale and in-the-wild dataset of 59,299 vocalizations from 1,702 speakers. The first, the A-VB-High task, requires competition participants to perform a multi-label regression on a novel model for emotion, utilizing ten classes of richly annotated emotional expression intensities, including; Awe, Fear, and Surprise. The second, the A-VB-Two task, utilizes the more conventional 2-dimensional model for emotion, arousal, and valence. The third, the A-VB-Culture task, requires participants to explore the cultural aspects of the dataset, training native-country dependent models. Finally, for the fourth task, A-VB-Type, participants should recognize the type of vocal burst (e.g., laughter, cry, grunt) as an 8-class classification. This paper describes the four tracks and baseline systems, which use state-of-the-art machine learning methods. The baseline performance for each track is obtained by utilizing an end-to-end deep learning model and is as follows: for A-VB-High, a mean (over the 10-dimensions) Concordance Correlation Coefficient (CCC) of 0.5687 CCC is obtained; for A-VB-Two, a mean (over the 2-dimensions) CCC of 0.5084 is obtained; for A-VB-Culture, a mean CCC from the four cultures of 0.4401 is obtained; and for A-VB-Type, the baseline Unweighted Average Recall (UAR) from the 8-classes is 0.4172 UAR.
The ACM Multimedia 2022 Computational Paralinguistics Challenge: Vocalisations, Stuttering, Activity, & Mosquitoes
May 13, 2022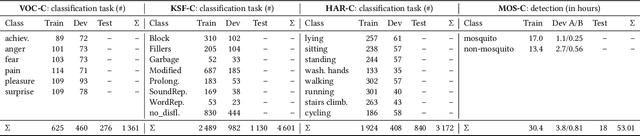
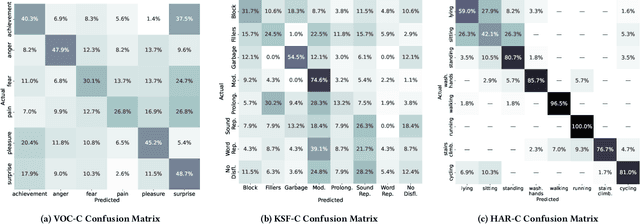

The ACM Multimedia 2022 Computational Paralinguistics Challenge addresses four different problems for the first time in a research competition under well-defined conditions: In the Vocalisations and Stuttering Sub-Challenges, a classification on human non-verbal vocalisations and speech has to be made; the Activity Sub-Challenge aims at beyond-audio human activity recognition from smartwatch sensor data; and in the Mosquitoes Sub-Challenge, mosquitoes need to be detected. We describe the Sub-Challenges, baseline feature extraction, and classifiers based on the usual ComPaRE and BoAW features, the auDeep toolkit, and deep feature extraction from pre-trained CNNs using the DeepSpectRum toolkit; in addition, we add end-to-end sequential modelling, and a log-mel-128-BNN.
A Summary of the ComParE COVID-19 Challenges
Feb 17, 2022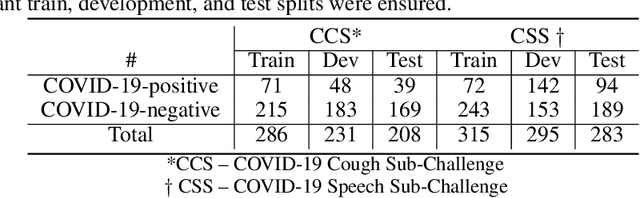
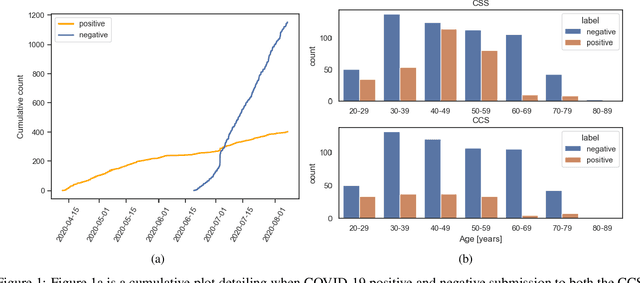
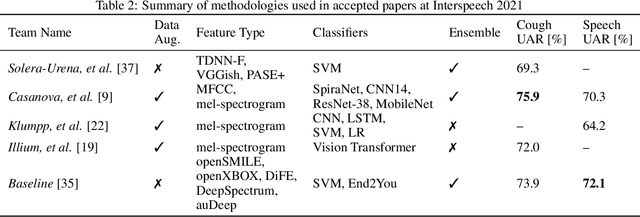
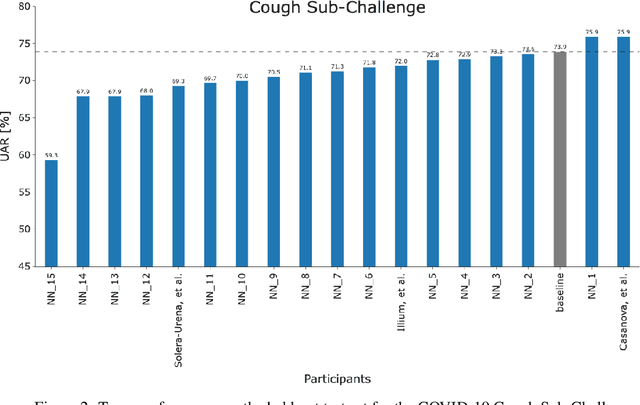
The COVID-19 pandemic has caused massive humanitarian and economic damage. Teams of scientists from a broad range of disciplines have searched for methods to help governments and communities combat the disease. One avenue from the machine learning field which has been explored is the prospect of a digital mass test which can detect COVID-19 from infected individuals' respiratory sounds. We present a summary of the results from the INTERSPEECH 2021 Computational Paralinguistics Challenges: COVID-19 Cough, (CCS) and COVID-19 Speech, (CSS).