 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaGradSelect: An adaptive gradient-guided layer selection method for efficient fine-tuning of SLMs
Dec 12, 2025Large Language Models (LLMs) can perform many NLP tasks well, but fully fine-tuning them is expensive and requires a lot of memory. Parameter-Efficient Fine-Tuning (PEFT) methods such as LoRA reduce this cost by adding small low-rank updates to frozen model weights. However, these methods restrict the training to a limited subspace, which can sometimes reduce performance. For Small Language Models (SLMs), where efficiency gains matter even more, we introduce AdaGradSelect, an adaptive method that selects which transformer blocks to update based on gradients. Early observations showed that updating only the transformer blocks with the highest gradient norms can achieve performance close to full fine-tuning. Building on this insight, AdaGradSelect adaptively chooses which blocks to train. It uses a combination of Dirichlet-based sampling, which depends on how frequently blocks were updated in the past, and an epsilon-greedy exploration strategy. This lets the method explore different blocks in early training and gradually focus on the most important ones in later epochs. Experiments show that AdaGradSelect trains about 12 percent faster and uses 35 percent less GPU memory while delivering performance very close to full fine-tuning. On the GSM8K dataset, it outperforms LoRA (rank 256) by about 3 percent on average across models such as Qwen2.5-0.5B, LLaMA3.2-1B, and Phi4-mini-3.8B. It also achieves similar accuracy on the MATH dataset. Overall, AdaGradSelect provides a more effective and resource-efficient alternative to traditional fine-tuning methods.
MM-Telco: Benchmarks and Multimodal Large Language Models for Telecom Applications
Nov 17, 2025Large Language Models (LLMs) have emerged as powerful tools for automating complex reasoning and decision-making tasks. In telecommunications, they hold the potential to transform network optimization, automate troubleshooting, enhance customer support, and ensure regulatory compliance. However, their deployment in telecom is hindered by domain-specific challenges that demand specialized adaptation. To overcome these challenges and to accelerate the adaptation of LLMs for telecom, we propose MM-Telco, a comprehensive suite of multimodal benchmarks and models tailored for the telecom domain. The benchmark introduces various tasks (both text based and image based) that address various practical real-life use cases such as network operations, network management, improving documentation quality, and retrieval of relevant text and images. Further, we perform baseline experiments with various LLMs and VLMs. The models fine-tuned on our dataset exhibit a significant boost in performance. Our experiments also help analyze the weak areas in the working of current state-of-art multimodal LLMs, thus guiding towards further development and research.
The application of predictive analytics to identify at-risk students in health professions education
Aug 05, 2021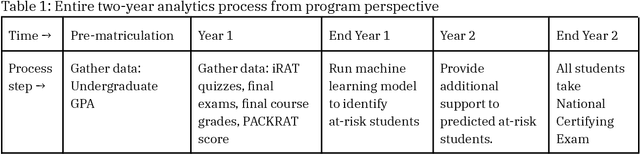
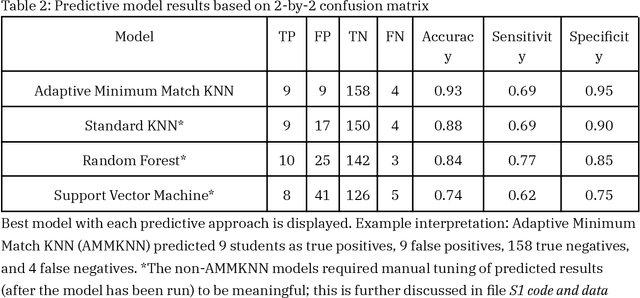
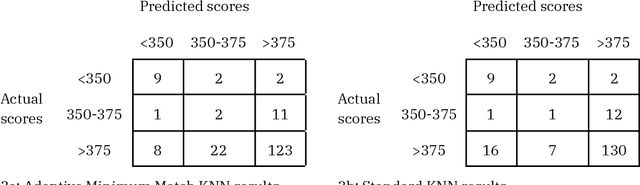
Introduction: When a learner fails to reach a milestone, educators often wonder if there had been any warning signs that could have allowed them to intervene sooner. Machine learning is used to predict which students are at risk of failing a national certifying exam. Predictions are made well in advance of the exam, such that educators can meaningfully intervene before students take the exam. Methods: Using already-collected, first-year student assessment data from four cohorts in a Master of Physician Assistant Studies program, the authors implement an "adaptive minimum match" version of the k-nearest neighbors algorithm (AMMKNN), using changing numbers of neighbors to predict each student's future exam scores on the Physician Assistant National Certifying Examination (PANCE). Leave-one-out cross validation (LOOCV) was used to evaluate the practical capabilities of this model, before making predictions for new students. Results: The best predictive model has an accuracy of 93%, sensitivity of 69%, and specificity of 94%. It generates a predicted PANCE score for each student, one year before they are scheduled to take the exam. Students can then be prospectively categorized into groups that need extra support, optional extra support, or no extra support. The educator then has one year to provide the appropriate customized support to each type of student. Conclusions: Predictive analytics can help health professions educators allocate scarce time and resources across their students. Interprofessional educators can use the included methods and code to generate predicted test outcomes for students. The authors recommend that educators using this or similar predictive methods act responsibly and transparently.