 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogicLearner: A Tool for the Guided Practice of Propositional Logic Proofs
Mar 25, 2025



The study of propositional logic -- fundamental to the theory of computing -- is a cornerstone of the undergraduate computer science curriculum. Learning to solve logical proofs requires repeated guided practice, but undergraduate students often lack access to on-demand tutoring in a judgment-free environment. In this work, we highlight the need for guided practice tools in undergraduate mathematics education and outline the desiderata of an effective practice tool. We accordingly develop LogicLearner, a web application for guided logic proof practice. LogicLearner consists of an interface to attempt logic proofs step-by-step and an automated proof solver to generate solutions on the fly, allowing users to request guidance as needed. We pilot LogicLearner as a practice tool in two semesters of an undergraduate discrete mathematics course and receive strongly positive feedback for usability and pedagogical value in student surveys. To the best of our knowledge, LogicLearner is the only learning tool that provides an end-to-end practice environment for logic proofs with immediate, judgment-free feedback.
Handling Uncertainty in Health Data using Generative Algorithms
Mar 05, 2025



Understanding and managing uncertainty is crucial in machine learning, especially in high-stakes domains like healthcare, where class imbalance can impact predictions. This paper introduces RIGA, a novel pipeline that mitigates class imbalance using generative AI. By converting tabular healthcare data into images, RIGA leverages models like cGAN, VQVAE, and VQGAN to generate balanced samples, improving classification performance. These representations are processed by CNNs and later transformed back into tabular format for seamless integration. This approach enhances traditional classifiers like XGBoost, improves Bayesian structure learning, and strengthens ML model robustness by generating realistic synthetic data for underrepresented classes.
Hierarchical Multi-Armed Bandits for the Concurrent Intelligent Tutoring of Concepts and Problems of Varying Difficulty Levels
Aug 10, 2024


Remote education has proliferated in the twenty-first century, yielding rise to intelligent tutoring systems. In particular, research has found multi-armed bandit (MAB) intelligent tutors to have notable abilities in traversing the exploration-exploitation trade-off landscape for student problem recommendations. Prior literature, however, contains a significant lack of open-sourced MAB intelligent tutors, which impedes potential applications of these educational MAB recommendation systems. In this paper, we combine recent literature on MAB intelligent tutoring techniques into an open-sourced and simply deployable hierarchical MAB algorithm, capable of progressing students concurrently through concepts and problems, determining ideal recommended problem difficulties, and assessing latent memory decay. We evaluate our algorithm using simulated groups of 500 students, utilizing Bayesian Knowledge Tracing to estimate students' content mastery. Results suggest that our algorithm, when turned difficulty-agnostic, significantly boosts student success, and that the further addition of problem-difficulty adaptation notably improves this metric.
M-DEW: Extending Dynamic Ensemble Weighting to Handle Missing Values
Apr 30, 2024



Missing value imputation is a crucial preprocessing step for many machine learning problems. However, it is often considered as a separate subtask from downstream applications such as classification, regression, or clustering, and thus is not optimized together with them. We hypothesize that treating the imputation model and downstream task model together and optimizing over full pipelines will yield better results than treating them separately. Our work describes a novel AutoML technique for making downstream predictions with missing data that automatically handles preprocessing, model weighting, and selection during inference time, with minimal compute overhead. Specifically we develop M-DEW, a Dynamic missingness-aware Ensemble Weighting (DEW) approach, that constructs a set of two-stage imputation-prediction pipelines, trains each component separately, and dynamically calculates a set of pipeline weights for each sample during inference time. We thus extend previous work on dynamic ensemble weighting to handle missing data at the level of full imputation-prediction pipelines, improving performance and calibration on downstream machine learning tasks over standard model averaging techniques. M-DEW is shown to outperform the state-of-the-art in that it produces statistically significant reductions in model perplexity in 17 out of 18 experiments, while improving average precision in 13 out of 18 experiments.
Teenagers and Artificial Intelligence: Bootcamp Experience and Lessons Learned
Dec 05, 2023



Artificial intelligence (AI) stands out as a game-changer in today's technology landscape. However, the integration of AI education in classroom curricula currently lags behind, leaving teenagers inadequately prepared for an imminent AI-driven future. In this pilot study, we designed a three-day bootcamp offered in the summer of 2023 to a cohort of 60 high school students. The curriculum was delivered in person through animated video content, easy-to-follow slides, interactive playgrounds, and quizzes. These were packaged in the early version of an online learning platform we are developing. Results from the post-bootcamp survey conveyed a 91.4% overall satisfaction. Despite the short bootcamp duration, 88.5% and 71.4% of teenagers responded that they had an improved understanding of AI concepts and programming, respectively. Overall, we found that employing diverse modalities effectively engaged students, and building foundational modules proved beneficial for introducing more complex topics. Furthermore, using Google Colab notebooks for coding assignments proved challenging to most students. Students' activity on the platform and their answers to quizzes showed proficient engagement and a grasp of the material. Our results strongly highlight the need for compelling and accessible AI education methods for the next generation and the potential for informal learning to fill the gap of providing early AI education to teenagers.
Counterfactual Explanations for Support Vector Machine Models
Dec 14, 2022



We tackle the problem of computing counterfactual explanations -- minimal changes to the features that flip an undesirable model prediction. We propose a solution to this question for linear Support Vector Machine (SVMs) models. Moreover, we introduce a way to account for weighted actions that allow for more changes in certain features than others. In particular, we show how to find counterfactual explanations with the purpose of increasing model interpretability. These explanations are valid, change only actionable features, are close to the data distribution, sparse, and take into account correlations between features. We cast this as a mixed integer programming optimization problem. Additionally, we introduce two novel scale-invariant cost functions for assessing the quality of counterfactual explanations and use them to evaluate the quality of our approach with a real medical dataset. Finally, we build a support vector machine model to predict whether law students will pass the Bar exam using protected features, and used our algorithms to uncover the inherent biases of the SVM.
A Weighted Solution to SVM Actionability and Interpretability
Dec 06, 2020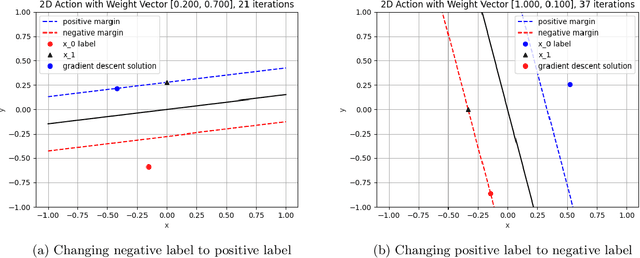
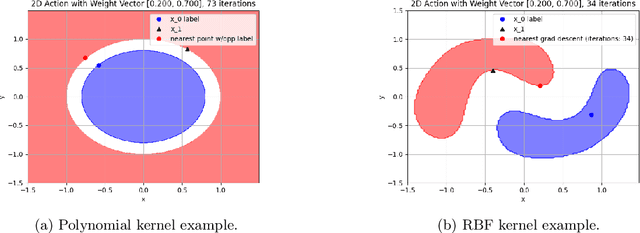

Research in machine learning has successfully developed algorithms to build accurate classification models. However, in many real-world applications, such as healthcare, customer satisfaction, and environment protection, we want to be able to use the models to decide what actions to take. We investigate the concept of actionability in the context of Support Vector Machines. Actionability is as important as interpretability or explainability of machine learning models, an ongoing and important research topic. Actionability is the task that gives us ways to act upon machine learning models and their predictions. This paper finds a solution to the question of actionability on both linear and non-linear SVM models. Additionally, we introduce a way to account for weighted actions that allow for more change in certain features than others. We propose a gradient descent solution on the linear, RBF, and polynomial kernels, and we test the effectiveness of our models on both synthetic and real datasets. We are also able to explore the model's interpretability through the lens of actionability.
Using Kernel Methods and Model Selection for Prediction of Preterm Birth
Sep 05, 2016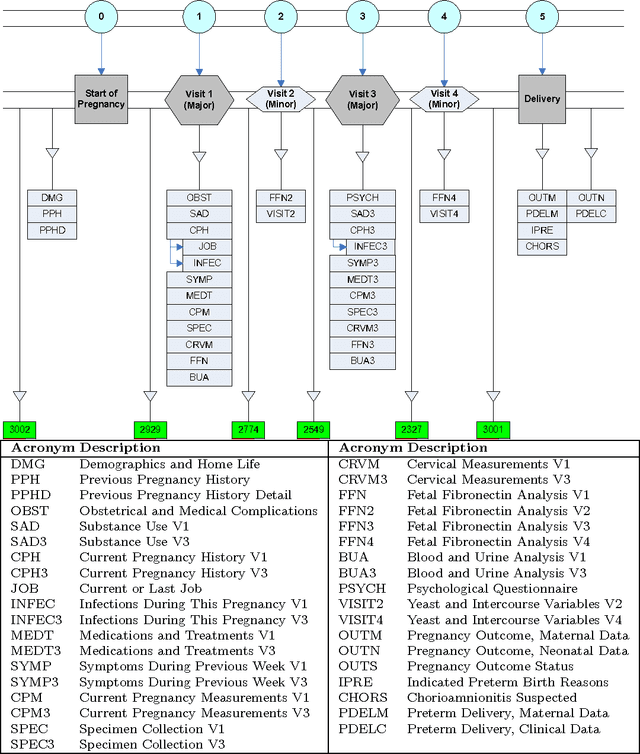
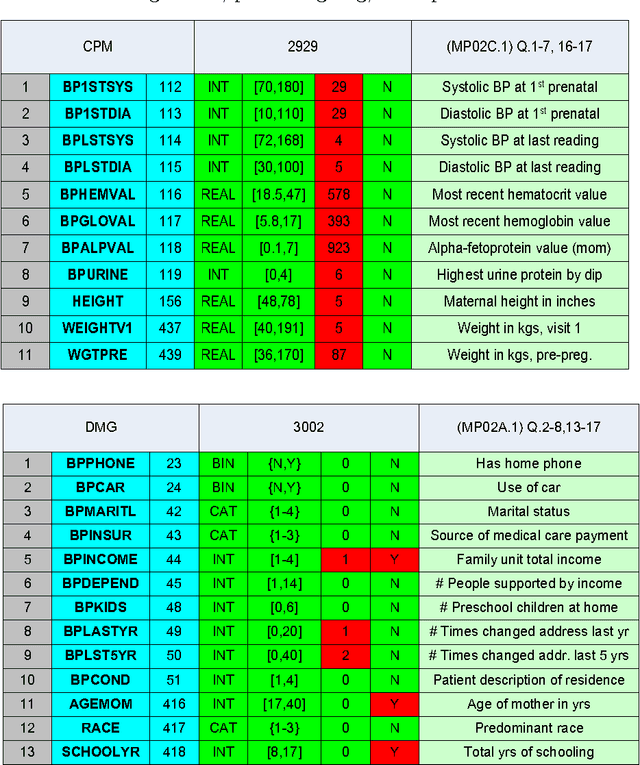

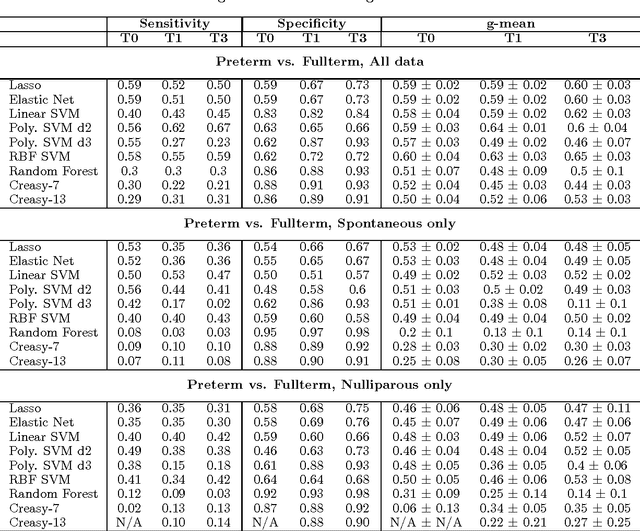
We describe an application of machine learning to the problem of predicting preterm birth. We conduct a secondary analysis on a clinical trial dataset collected by the National In- stitute of Child Health and Human Development (NICHD) while focusing our attention on predicting different classes of preterm birth. We compare three approaches for deriving predictive models: a support vector machine (SVM) approach with linear and non-linear kernels, logistic regression with different model selection along with a model based on decision rules prescribed by physician experts for prediction of preterm birth. Our approach highlights the pre-processing methods applied to handle the inherent dynamics, noise and gaps in the data and describe techniques used to handle skewed class distributions. Empirical experiments demonstrate significant improvement in predicting preterm birth compared to past work.