 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble-based, large-eddy reconstruction of wind turbine inflow in a near-stationary atmospheric boundary layer through generative artificial intelligence
Oct 17, 2024
To validate the second-by-second dynamics of turbines in field experiments, it is necessary to accurately reconstruct the winds going into the turbine. Current time-resolved inflow reconstruction techniques estimate wind behavior in unobserved regions using relatively simple spectral-based models of the atmosphere. Here, we develop a technique for time-resolved inflow reconstruction that is rooted in a large-eddy simulation model of the atmosphere. Our "large-eddy reconstruction" technique blends observations and atmospheric model information through a diffusion model machine learning algorithm, allowing us to generate probabilistic ensembles of reconstructions for a single 10-min observational period. Our generated inflows can be used directly by aeroelastic codes or as inflow boundary conditions in a large-eddy simulation. We verify the second-by-second reconstruction capability of our technique in three synthetic field campaigns, finding positive Pearson correlation coefficient values (0.20>r>0.85) between ground-truth and reconstructed streamwise velocity, as well as smaller positive correlation coefficient values for unobserved fields (spanwise velocity, vertical velocity, and temperature). We validate our technique in three real-world case studies by driving large-eddy simulations with reconstructed inflows and comparing to independent inflow measurements. The reconstructions are visually similar to measurements, follow desired power spectra properties, and track second-by-second behavior (0.25 > r > 0.75).
Generating Initial Conditions for Ensemble Data Assimilation of Large-Eddy Simulations with Latent Diffusion Models
Mar 01, 2023



In order to accurately reconstruct the time history of the atmospheric state, ensemble-based data assimilation algorithms need to be initialized appropriately. At present, there is no standard approach to initializing large-eddy simulation codes for microscale data assimilation. Here, given synthetic observations, we generate ensembles of plausible initial conditions using a latent diffusion model. We modify the original, two-dimensional latent diffusion model code to work on three-dimensional turbulent fields. The algorithm produces realistic and diverse samples that successfully run when inserted into a large-eddy simulation code. The samples have physically plausible turbulent structures on large and moderate spatial scales in the context of our simulations. The generated ensembles show a lower spread in the vicinity of observations while having higher variability further from the observations, matching expected behavior. Ensembles demonstrate near-zero bias relative to ground truth in the vicinity of observations, but rank histogram analysis suggests that ensembles have too little member-to-member variability when compared to an ideal ensemble. Given the success of the latent diffusion model, the generated ensembles will be tested in their ability to recreate a time history of the atmosphere when coupled to an ensemble-based data assimilation algorithm in upcoming work. We find that diffusion models show promise and potential for other applications within the geosciences.
Using Kernel Methods and Model Selection for Prediction of Preterm Birth
Sep 05, 2016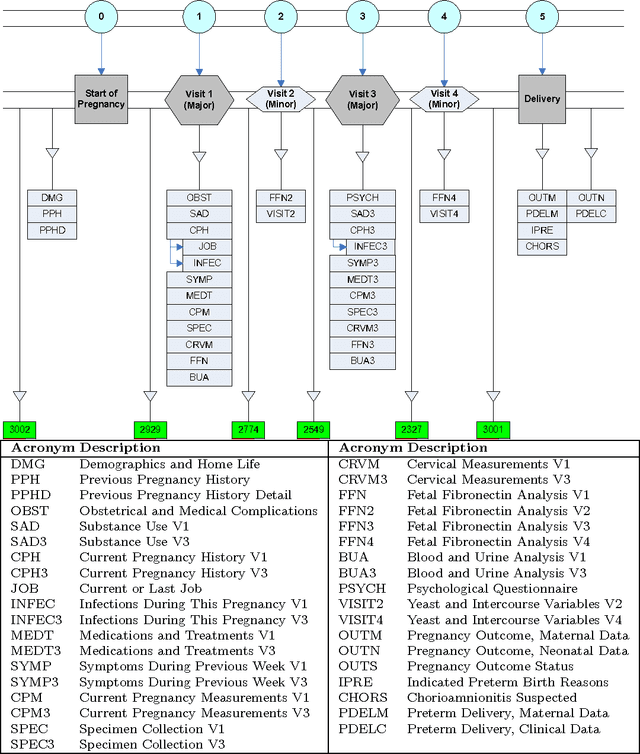
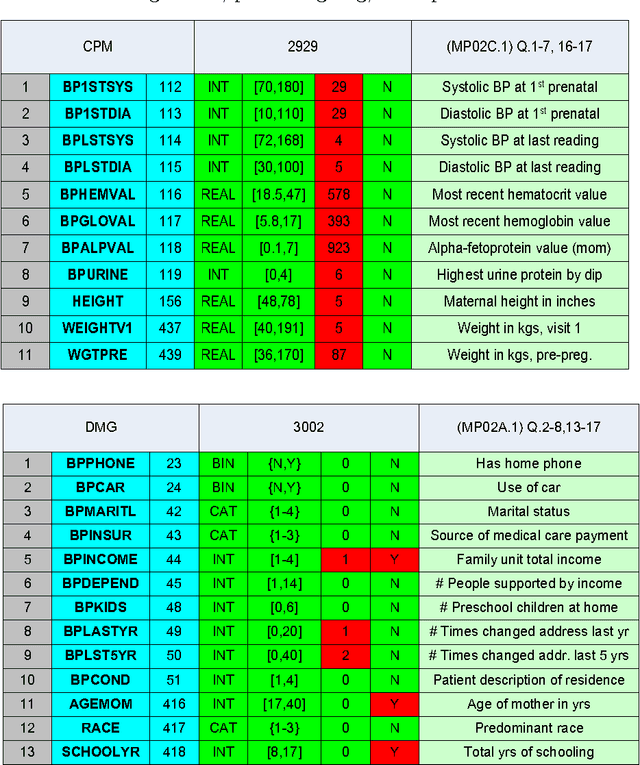

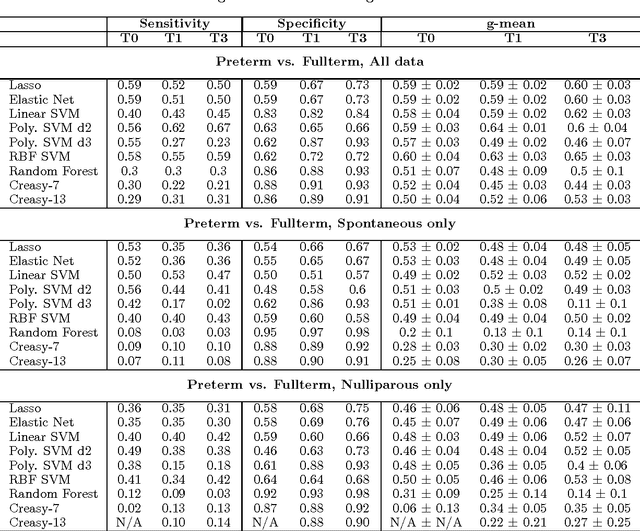
We describe an application of machine learning to the problem of predicting preterm birth. We conduct a secondary analysis on a clinical trial dataset collected by the National In- stitute of Child Health and Human Development (NICHD) while focusing our attention on predicting different classes of preterm birth. We compare three approaches for deriving predictive models: a support vector machine (SVM) approach with linear and non-linear kernels, logistic regression with different model selection along with a model based on decision rules prescribed by physician experts for prediction of preterm birth. Our approach highlights the pre-processing methods applied to handle the inherent dynamics, noise and gaps in the data and describe techniques used to handle skewed class distributions. Empirical experiments demonstrate significant improvement in predicting preterm birth compared to past work.