 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwinOR: Photorealistic Digital Twins of Dynamic Operating Rooms for Embodied AI Research
Nov 10, 2025Developing embodied AI for intelligent surgical systems requires safe, controllable environments for continual learning and evaluation. However, safety regulations and operational constraints in operating rooms (ORs) limit embodied agents from freely perceiving and interacting in realistic settings. Digital twins provide high-fidelity, risk-free environments for exploration and training. How we may create photorealistic and dynamic digital representations of ORs that capture relevant spatial, visual, and behavioral complexity remains unclear. We introduce TwinOR, a framework for constructing photorealistic, dynamic digital twins of ORs for embodied AI research. The system reconstructs static geometry from pre-scan videos and continuously models human and equipment motion through multi-view perception of OR activities. The static and dynamic components are fused into an immersive 3D environment that supports controllable simulation and embodied exploration. The proposed framework reconstructs complete OR geometry with centimeter level accuracy while preserving dynamic interaction across surgical workflows, enabling realistic renderings and a virtual playground for embodied AI systems. In our experiments, TwinOR simulates stereo and monocular sensor streams for geometry understanding and visual localization tasks. Models such as FoundationStereo and ORB-SLAM3 on TwinOR-synthesized data achieve performance within their reported accuracy on real indoor datasets, demonstrating that TwinOR provides sensor-level realism sufficient for perception and localization challenges. By establishing a real-to-sim pipeline for constructing dynamic, photorealistic digital twins of OR environments, TwinOR enables the safe, scalable, and data-efficient development and benchmarking of embodied AI, ultimately accelerating the deployment of embodied AI from sim-to-real.
Did you just see that? Arbitrary view synthesis for egocentric replay of operating room workflows from ambient sensors
Oct 06, 2025Observing surgical practice has historically relied on fixed vantage points or recollections, leaving the egocentric visual perspectives that guide clinical decisions undocumented. Fixed-camera video can capture surgical workflows at the room-scale, but cannot reconstruct what each team member actually saw. Thus, these videos only provide limited insights into how decisions that affect surgical safety, training, and workflow optimization are made. Here we introduce EgoSurg, the first framework to reconstruct the dynamic, egocentric replays for any operating room (OR) staff directly from wall-mounted fixed-camera video, and thus, without intervention to clinical workflow. EgoSurg couples geometry-driven neural rendering with diffusion-based view enhancement, enabling high-visual fidelity synthesis of arbitrary and egocentric viewpoints at any moment. In evaluation across multi-site surgical cases and controlled studies, EgoSurg reconstructs person-specific visual fields and arbitrary viewpoints with high visual quality and fidelity. By transforming existing OR camera infrastructure into a navigable dynamic 3D record, EgoSurg establishes a new foundation for immersive surgical data science, enabling surgical practice to be visualized, experienced, and analyzed from every angle.
XCI-Sketch: Extraction of Color Information from Images for Generation of Colored Outlines and Sketches
Aug 26, 2021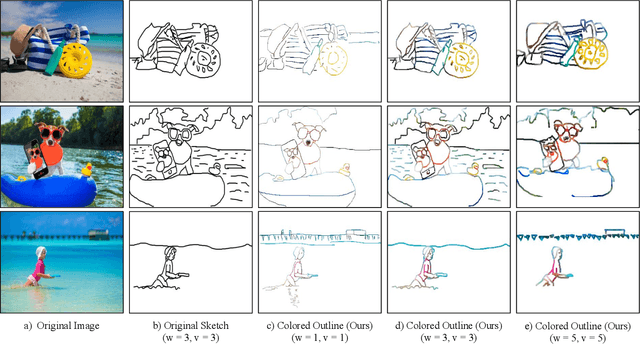
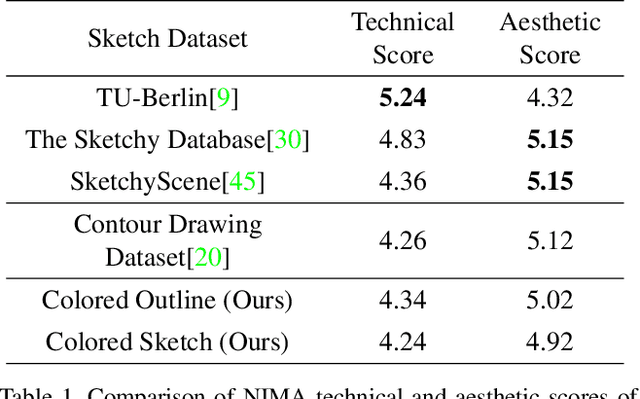
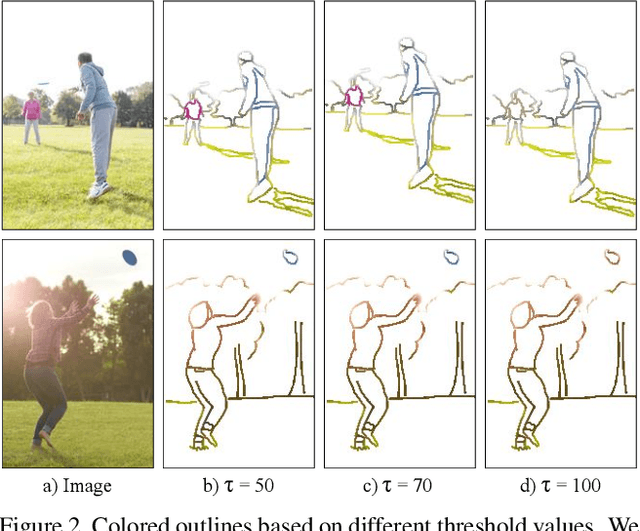
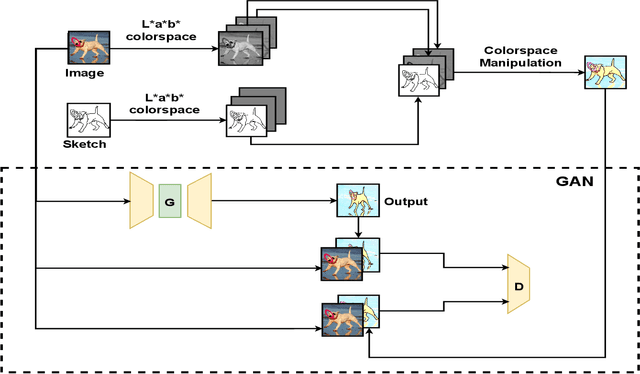
Sketches are a medium to convey a visual scene from an individual's creative perspective. The addition of color substantially enhances the overall expressivity of a sketch. This paper proposes two methods to mimic human-drawn colored sketches by utilizing the Contour Drawing Dataset. Our first approach renders colored outline sketches by applying image processing techniques aided by k-means color clustering. The second method uses a generative adversarial network to develop a model that can generate colored sketches from previously unobserved images. We assess the results obtained through quantitative and qualitative evaluations.
Semi-Supervised Classification and Segmentation on High Resolution Aerial Images
May 16, 2021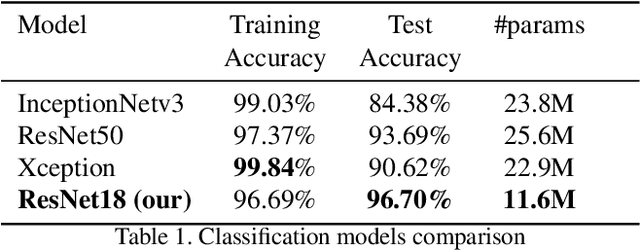
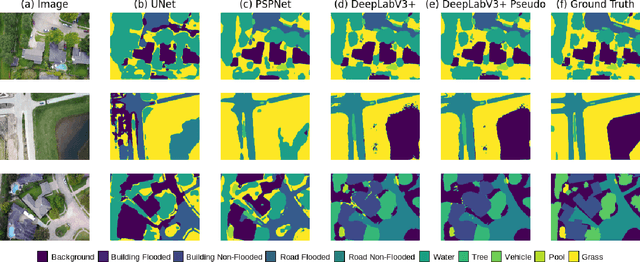

FloodNet is a high-resolution image dataset acquired by a small UAV platform, DJI Mavic Pro quadcopters, after Hurricane Harvey. The dataset presents a unique challenge of advancing the damage assessment process for post-disaster scenarios using unlabeled and limited labeled dataset. We propose a solution to address their classification and semantic segmentation challenge. We approach this problem by generating pseudo labels for both classification and segmentation during training and slowly incrementing the amount by which the pseudo label loss affects the final loss. Using this semi-supervised method of training helped us improve our baseline supervised loss by a huge margin for classification, allowing the model to generalize and perform better on the validation and test splits of the dataset. In this paper, we compare and contrast the various methods and models for image classification and semantic segmentation on the FloodNet dataset.
IS-CAM: Integrated Score-CAM for axiomatic-based explanations
Oct 06, 2020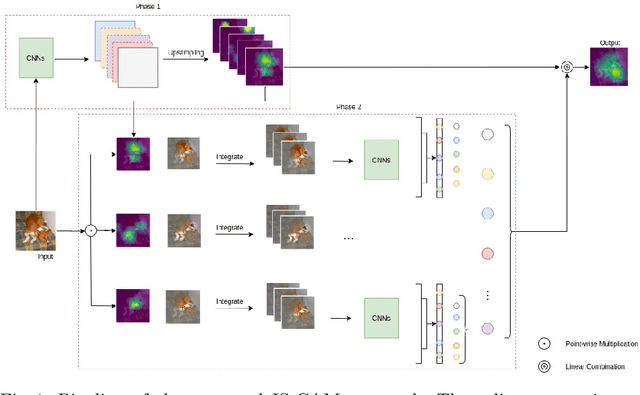
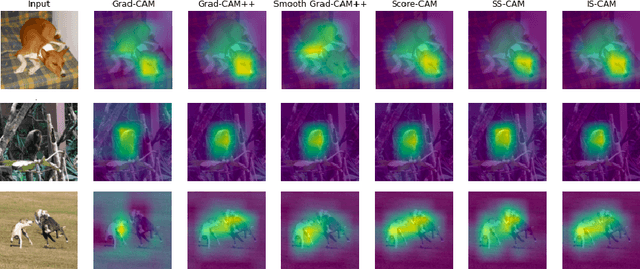
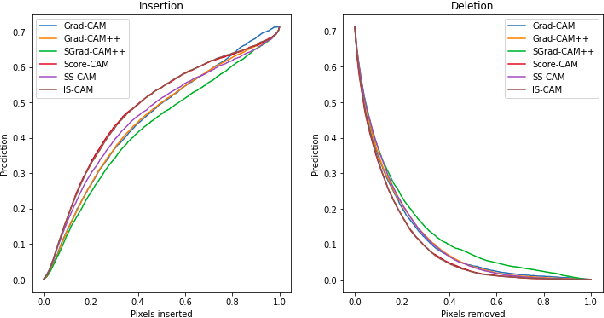
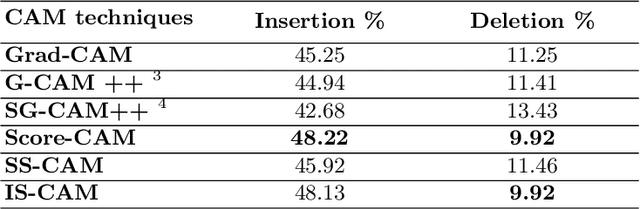
Convolutional Neural Networks have been known as black-box models as humans cannot interpret their inner functionalities. With an attempt to make CNNs more interpretable and trustworthy, we propose IS-CAM (Integrated Score-CAM), where we introduce the integration operation within the Score-CAM pipeline to achieve visually sharper attribution maps quantitatively. Our method is evaluated on 2000 randomly selected images from the ILSVRC 2012 Validation dataset, which proves the versatility of IS-CAM to account for different models and methods.