 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Sampling and Labeling Bias for Learning in Large-Output Spaces
May 12, 2021
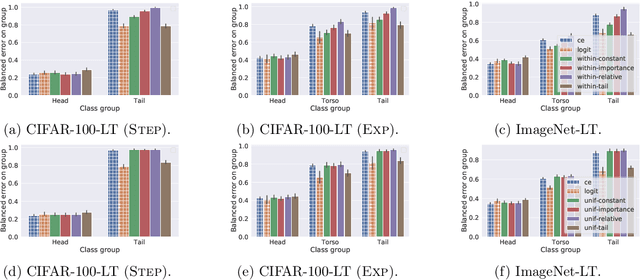

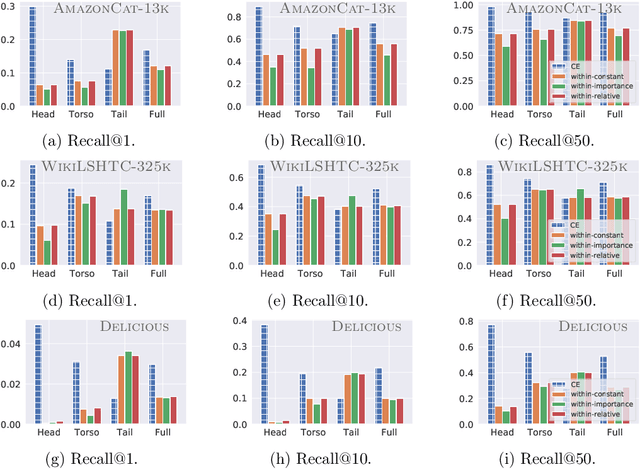
Negative sampling schemes enable efficient training given a large number of classes, by offering a means to approximate a computationally expensive loss function that takes all labels into account. In this paper, we present a new connection between these schemes and loss modification techniques for countering label imbalance. We show that different negative sampling schemes implicitly trade-off performance on dominant versus rare labels. Further, we provide a unified means to explicitly tackle both sampling bias, arising from working with a subset of all labels, and labeling bias, which is inherent to the data due to label imbalance. We empirically verify our findings on long-tail classification and retrieval benchmarks.
Distilling Double Descent
Feb 13, 2021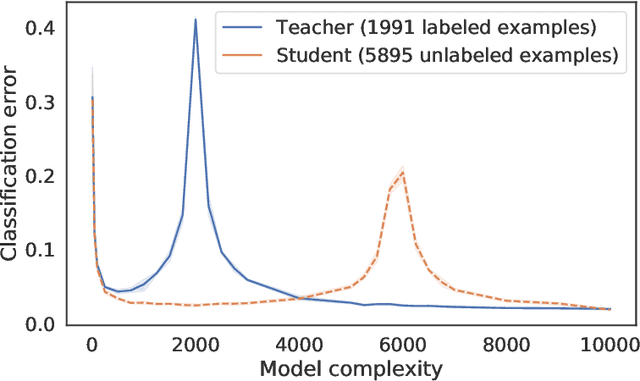
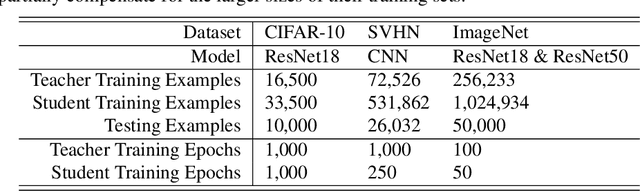
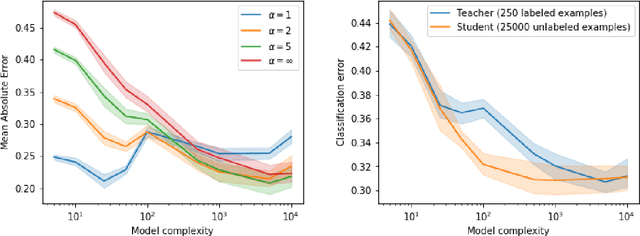
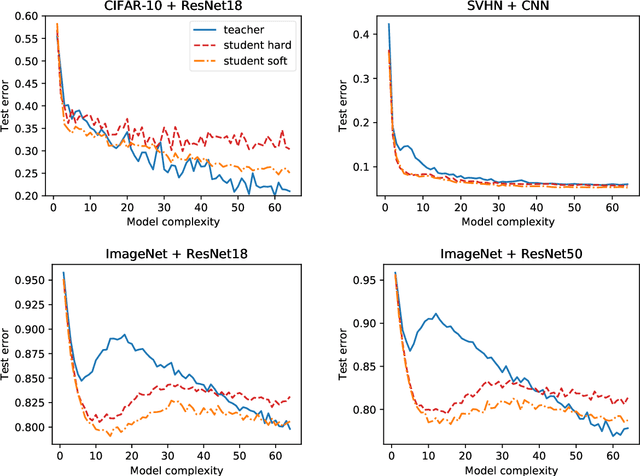
Distillation is the technique of training a "student" model based on examples that are labeled by a separate "teacher" model, which itself is trained on a labeled dataset. The most common explanations for why distillation "works" are predicated on the assumption that student is provided with \emph{soft} labels, \eg probabilities or confidences, from the teacher model. In this work, we show, that, even when the teacher model is highly overparameterized, and provides \emph{hard} labels, using a very large held-out unlabeled dataset to train the student model can result in a model that outperforms more "traditional" approaches. Our explanation for this phenomenon is based on recent work on "double descent". It has been observed that, once a model's complexity roughly exceeds the amount required to memorize the training data, increasing the complexity \emph{further} can, counterintuitively, result in \emph{better} generalization. Researchers have identified several settings in which it takes place, while others have made various attempts to explain it (thus far, with only partial success). In contrast, we avoid these questions, and instead seek to \emph{exploit} this phenomenon by demonstrating that a highly-overparameterized teacher can avoid overfitting via double descent, while a student trained on a larger independent dataset labeled by this teacher will avoid overfitting due to the size of its training set.
On the Reproducibility of Neural Network Predictions
Feb 05, 2021

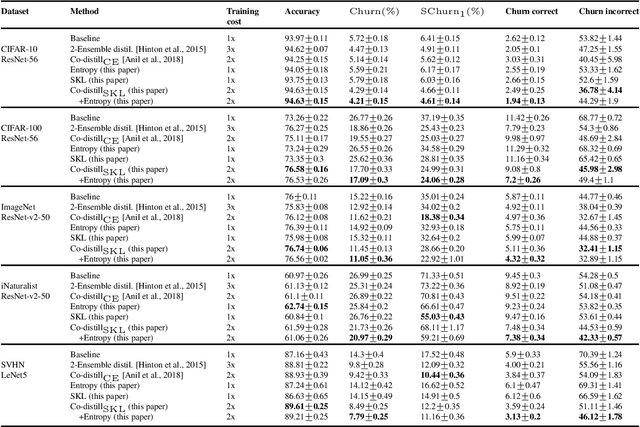
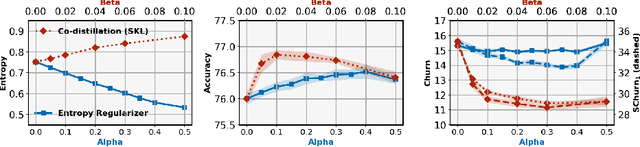
Standard training techniques for neural networks involve multiple sources of randomness, e.g., initialization, mini-batch ordering and in some cases data augmentation. Given that neural networks are heavily over-parameterized in practice, such randomness can cause {\em churn} -- for the same input, disagreements between predictions of the two models independently trained by the same algorithm, contributing to the `reproducibility challenges' in modern machine learning. In this paper, we study this problem of churn, identify factors that cause it, and propose two simple means of mitigating it. We first demonstrate that churn is indeed an issue, even for standard image classification tasks (CIFAR and ImageNet), and study the role of the different sources of training randomness that cause churn. By analyzing the relationship between churn and prediction confidences, we pursue an approach with two components for churn reduction. First, we propose using \emph{minimum entropy regularizers} to increase prediction confidences. Second, \changes{we present a novel variant of co-distillation approach~\citep{anil2018large} to increase model agreement and reduce churn}. We present empirical results showing the effectiveness of both techniques in reducing churn while improving the accuracy of the underlying model.
Modifying Memories in Transformer Models
Dec 01, 2020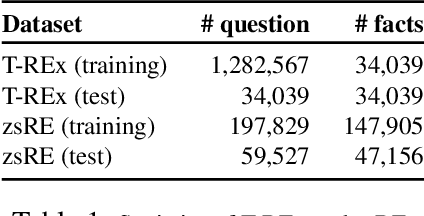

Large Transformer models have achieved impressive performance in many natural language tasks. In particular, Transformer based language models have been shown to have great capabilities in encoding factual knowledge in their vast amount of parameters. While the tasks of improving the memorization and generalization of Transformers have been widely studied, it is not well known how to make transformers forget specific old facts and memorize new ones. In this paper, we propose a new task of \emph{explicitly modifying specific factual knowledge in Transformer models while ensuring the model performance does not degrade on the unmodified facts}. This task is useful in many scenarios, such as updating stale knowledge, protecting privacy, and eliminating unintended biases stored in the models. We benchmarked several approaches that provide natural baseline performances on this task. This leads to the discovery of key components of a Transformer model that are especially effective for knowledge modifications. The work also provides insights into the role that different training phases (such as pretraining and fine-tuning) play towards memorization and knowledge modification.
Adversarial robustness via robust low rank representations
Aug 01, 2020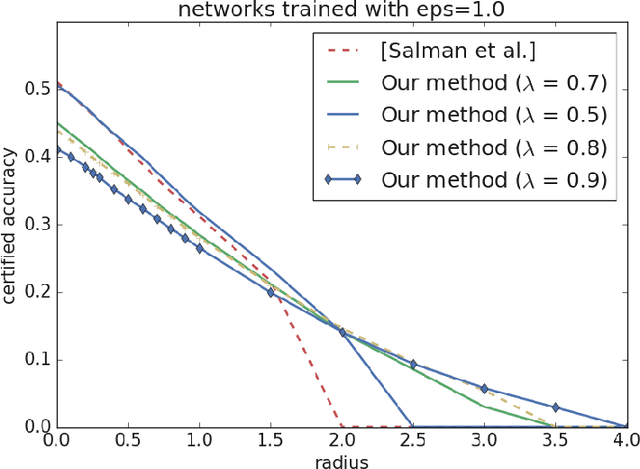

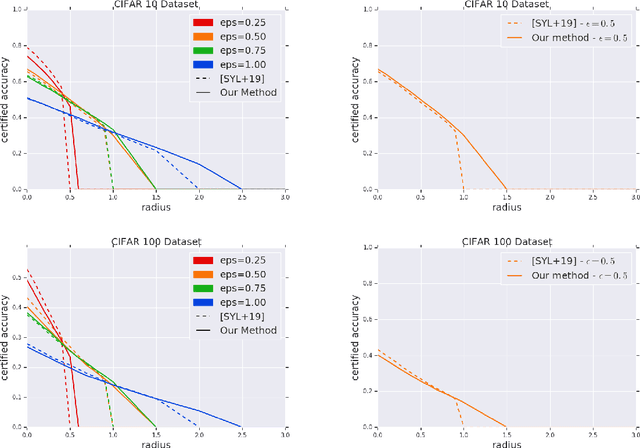
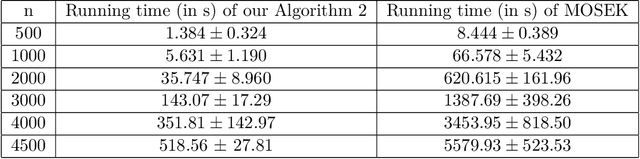
Adversarial robustness measures the susceptibility of a classifier to imperceptible perturbations made to the inputs at test time. In this work we highlight the benefits of natural low rank representations that often exist for real data such as images, for training neural networks with certified robustness guarantees. Our first contribution is for certified robustness to perturbations measured in $\ell_2$ norm. We exploit low rank data representations to provide improved guarantees over state-of-the-art randomized smoothing-based approaches on standard benchmark datasets such as CIFAR-10 and CIFAR-100. Our second contribution is for the more challenging setting of certified robustness to perturbations measured in $\ell_\infty$ norm. We demonstrate empirically that natural low rank representations have inherent robustness properties, that can be leveraged to provide significantly better guarantees for certified robustness to $\ell_\infty$ perturbations in those representations. Our certificate of $\ell_\infty$ robustness relies on a natural quantity involving the $\infty \to 2$ matrix operator norm associated with the representation, to translate robustness guarantees from $\ell_2$ to $\ell_\infty$ perturbations. A key technical ingredient for our certification guarantees is a fast algorithm with provable guarantees based on the multiplicative weights update method to provide upper bounds on the above matrix norm. Our algorithmic guarantees improve upon the state of the art for this problem, and may be of independent interest.
Long-tail learning via logit adjustment
Jul 14, 2020
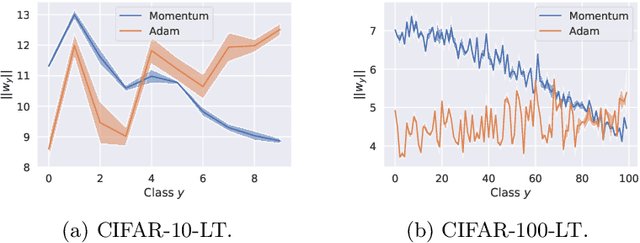
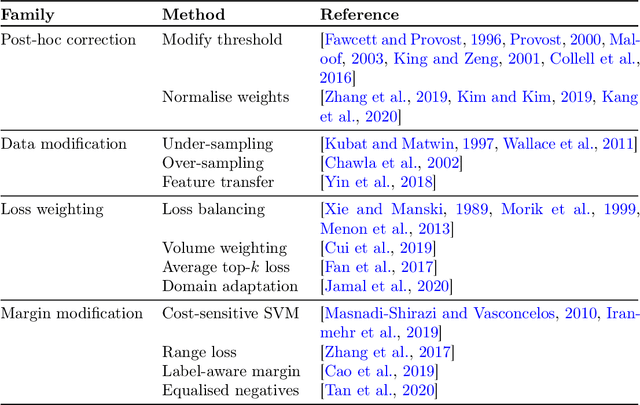
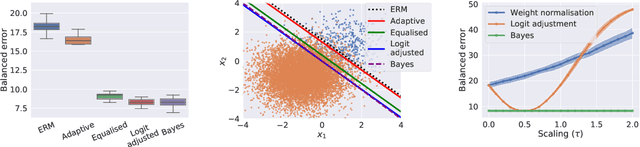
Real-world classification problems typically exhibit an imbalanced or long-tailed label distribution, wherein many labels are associated with only a few samples. This poses a challenge for generalisation on such labels, and also makes na\"ive learning biased towards dominant labels. In this paper, we present two simple modifications of standard softmax cross-entropy training to cope with these challenges. Our techniques revisit the classic idea of logit adjustment based on the label frequencies, either applied post-hoc to a trained model, or enforced in the loss during training. Such adjustment encourages a large relative margin between logits of rare versus dominant labels. These techniques unify and generalise several recent proposals in the literature, while possessing firmer statistical grounding and empirical performance.
$O(n)$ Connections are Expressive Enough: Universal Approximability of Sparse Transformers
Jun 08, 2020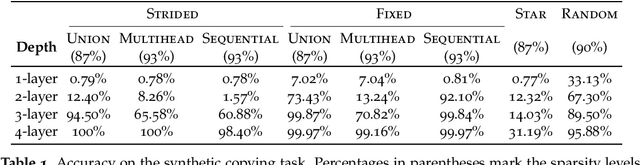
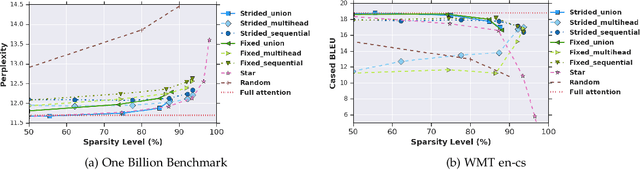
Transformer networks use pairwise attention to compute contextual embeddings of inputs, and have redefined the state of the art in many NLP tasks. However, these models suffer from quadratic computational cost in the input sequence length $n$ to compute attention in each layer. This has prompted recent research into faster attention models, with a predominant approach involving sparsifying the connections in the attention layers. While empirically promising for long sequences, fundamental questions remain unanswered: Can sparse transformers approximate any arbitrary sequence-to-sequence function, similar to their dense counterparts? How does the sparsity pattern and the sparsity level affect their performance? In this paper, we address these questions and provide a unifying framework that captures existing sparse attention models. Our analysis proposes sufficient conditions under which we prove that a sparse attention model can universally approximate any sequence-to-sequence function. Surprisingly, our results show the existence of models with only $O(n)$ connections per attention layer that can approximate the same function class as the dense model with $n^2$ connections. Lastly, we present experiments comparing different patterns/levels of sparsity on standard NLP tasks.
Why distillation helps: a statistical perspective
May 21, 2020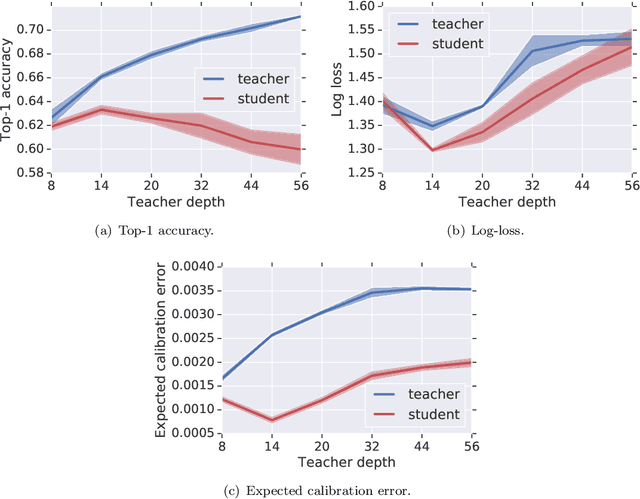
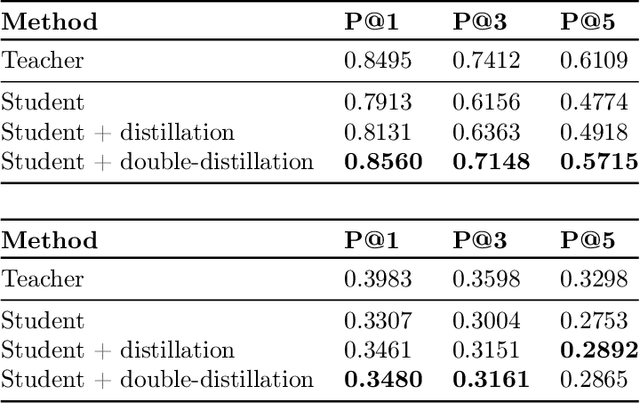
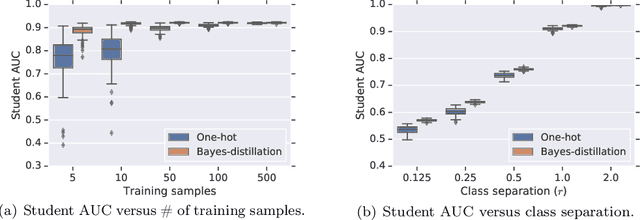
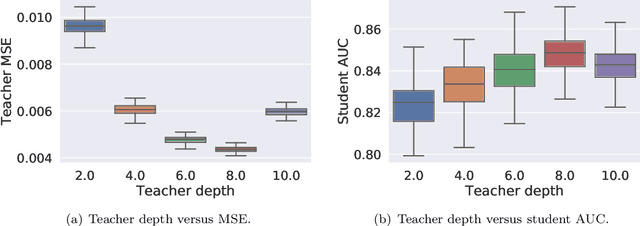
Knowledge distillation is a technique for improving the performance of a simple "student" model by replacing its one-hot training labels with a distribution over labels obtained from a complex "teacher" model. While this simple approach has proven widely effective, a basic question remains unresolved: why does distillation help? In this paper, we present a statistical perspective on distillation which addresses this question, and provides a novel connection to extreme multiclass retrieval techniques. Our core observation is that the teacher seeks to estimate the underlying (Bayes) class-probability function. Building on this, we establish a fundamental bias-variance tradeoff in the student's objective: this quantifies how approximate knowledge of these class-probabilities can significantly aid learning. Finally, we show how distillation complements existing negative mining techniques for extreme multiclass retrieval, and propose a unified objective which combines these ideas.
Doubly-stochastic mining for heterogeneous retrieval
Apr 23, 2020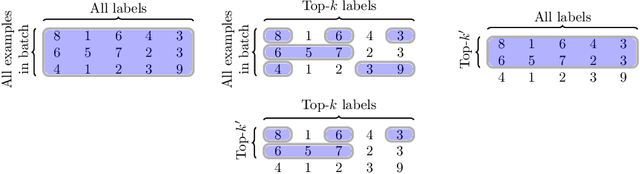


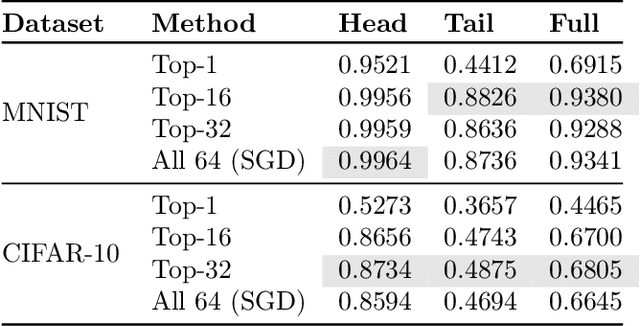
Modern retrieval problems are characterised by training sets with potentially billions of labels, and heterogeneous data distributions across subpopulations (e.g., users of a retrieval system may be from different countries), each of which poses a challenge. The first challenge concerns scalability: with a large number of labels, standard losses are difficult to optimise even on a single example. The second challenge concerns uniformity: one ideally wants good performance on each subpopulation. While several solutions have been proposed to address the first challenge, the second challenge has received relatively less attention. In this paper, we propose doubly-stochastic mining (S2M ), a stochastic optimization technique that addresses both challenges. In each iteration of S2M, we compute a per-example loss based on a subset of hardest labels, and then compute the minibatch loss based on the hardest examples. We show theoretically and empirically that by focusing on the hardest examples, S2M ensures that all data subpopulations are modelled well.
Federated Learning with Only Positive Labels
Apr 21, 2020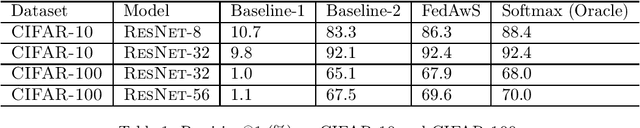

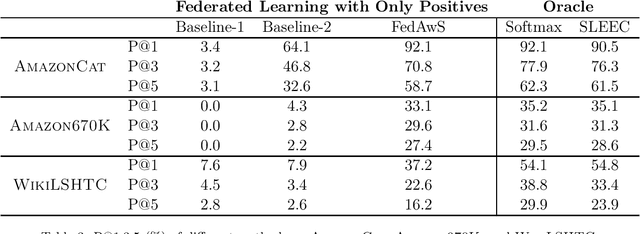

We consider learning a multi-class classification model in the federated setting, where each user has access to the positive data associated with only a single class. As a result, during each federated learning round, the users need to locally update the classifier without having access to the features and the model parameters for the negative classes. Thus, naively employing conventional decentralized learning such as the distributed SGD or Federated Averaging may lead to trivial or extremely poor classifiers. In particular, for the embedding based classifiers, all the class embeddings might collapse to a single point. To address this problem, we propose a generic framework for training with only positive labels, namely Federated Averaging with Spreadout (FedAwS), where the server imposes a geometric regularizer after each round to encourage classes to be spreadout in the embedding space. We show, both theoretically and empirically, that FedAwS can almost match the performance of conventional learning where users have access to negative labels. We further extend the proposed method to the settings with large output spaces.