 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJEDI: Jointly Embedded Inference of Neural Dynamics
Mar 11, 2026Animal brains flexibly and efficiently achieve many behavioral tasks with a single neural network. A core goal in modern neuroscience is to map the mechanisms of the brain's flexibility onto the dynamics underlying neural populations. However, identifying task-specific dynamical rules from limited, noisy, and high-dimensional experimental neural recordings remains a major challenge, as experimental data often provide only partial access to brain states and dynamical mechanisms. While recurrent neural networks (RNNs) directly constrained neural data have been effective in inferring underlying dynamical mechanisms, they are typically limited to single-task domains and struggle to generalize across behavioral conditions. Here, we introduce JEDI, a hierarchical model that captures neural dynamics across tasks and contexts by learning a shared embedding space over RNN weights. This model recapitulates individual samples of neural dynamics while scaling to arbitrarily large and complex datasets, uncovering shared structure across conditions in a single, unified model. Using simulated RNN datasets, we demonstrate that JEDI accurately learns robust, generalizable, condition-specific embeddings. By reverse-engineering the weights learned by JEDI, we show that it recovers ground truth fixed point structures and unveils key features of the underlying neural dynamics in the eigenspectra. Finally, we apply JEDI to motor cortex recordings during monkey reaching to extract mechanistic insight into the neural dynamics of motor control. Our work shows that joint learning of contextual embeddings and recurrent weights provides scalable and generalizable inference of brain dynamics from recordings alone.
Non-Local Latent Relation Distillation for Self-Adaptive 3D Human Pose Estimation
Apr 06, 2022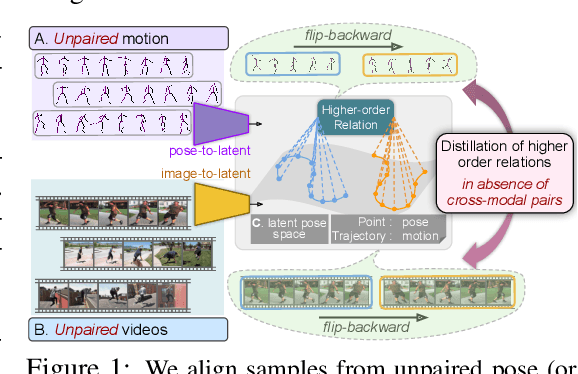
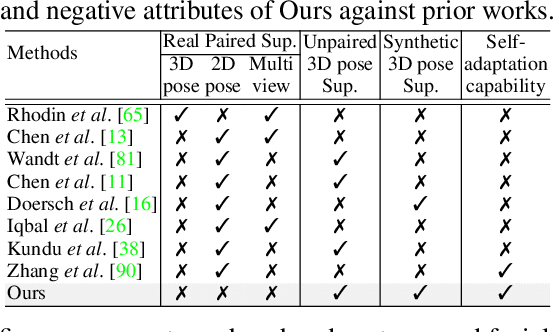
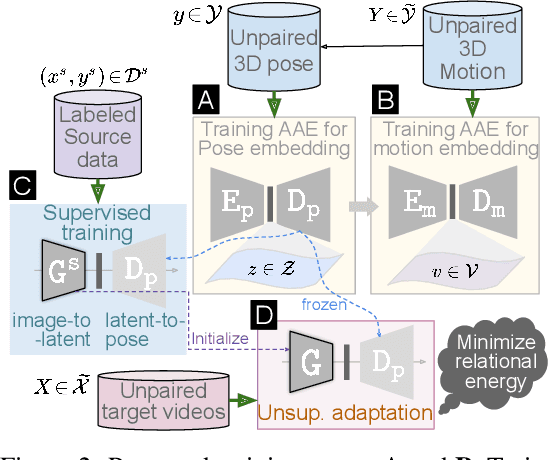
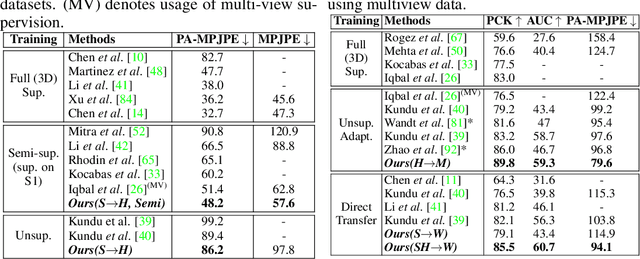
Available 3D human pose estimation approaches leverage different forms of strong (2D/3D pose) or weak (multi-view or depth) paired supervision. Barring synthetic or in-studio domains, acquiring such supervision for each new target environment is highly inconvenient. To this end, we cast 3D pose learning as a self-supervised adaptation problem that aims to transfer the task knowledge from a labeled source domain to a completely unpaired target. We propose to infer image-to-pose via two explicit mappings viz. image-to-latent and latent-to-pose where the latter is a pre-learned decoder obtained from a prior-enforcing generative adversarial auto-encoder. Next, we introduce relation distillation as a means to align the unpaired cross-modal samples i.e. the unpaired target videos and unpaired 3D pose sequences. To this end, we propose a new set of non-local relations in order to characterize long-range latent pose interactions unlike general contrastive relations where positive couplings are limited to a local neighborhood structure. Further, we provide an objective way to quantify non-localness in order to select the most effective relation set. We evaluate different self-adaptation settings and demonstrate state-of-the-art 3D human pose estimation performance on standard benchmarks.