 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFingerprint Spoof Detection: Temporal Analysis of Image Sequence
Dec 17, 2019

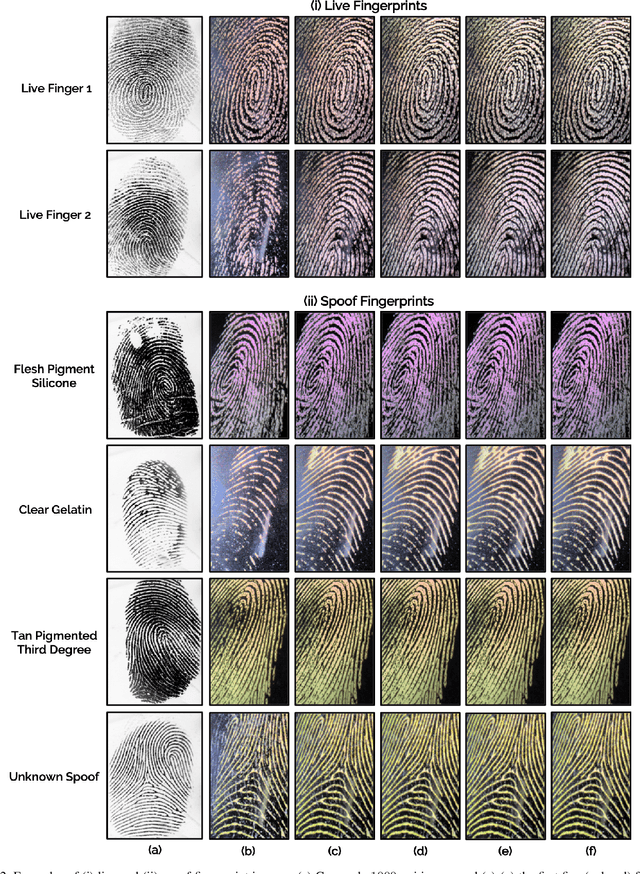
We utilize the dynamics involved in the imaging of a fingerprint on a touch-based fingerprint reader, such as perspiration, changes in skin color (blanching), and skin distortion, to differentiate real fingers from spoof (fake) fingers. Specifically, we utilize a deep learning-based architecture (CNN-LSTM) trained end-to-end using sequences of minutiae-centered local patches extracted from ten color frames captured on a COTS fingerprint reader. A time-distributed CNN (MobileNet-v1) extracts spatial features from each local patch, while a bi-directional LSTM layer learns the temporal relationship between the patches in the sequence. Experimental results on a database of 26,650 live frames from 685 subjects (1,333 unique fingers), and 32,910 spoof frames of 7 spoof materials (with 14 variants) shows the superiority of the proposed approach in both known-material and cross-material (generalization) scenarios. For instance, the proposed approach improves the state-of-the-art cross-material performance from TDR of 81.65% to 86.20% @ FDR = 0.2%.
Fingerprint Synthesis: Search with 100 Million Prints
Dec 16, 2019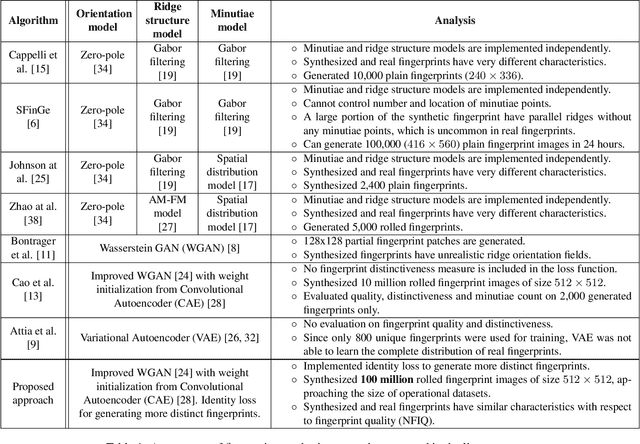

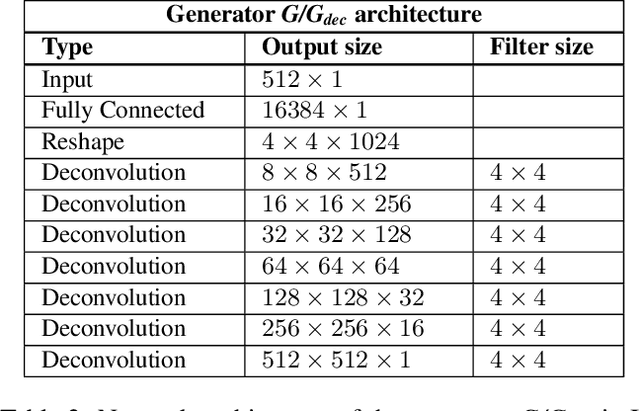
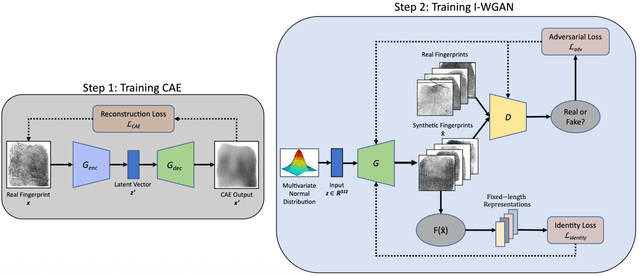
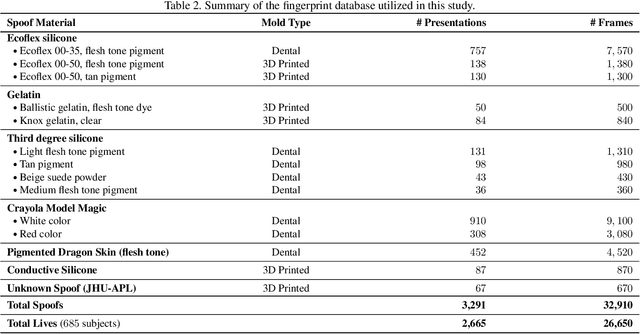
Evaluation of large-scale fingerprint search algorithms has been limited due to lack of publicly available datasets. A solution to this problem is to synthesize a dataset of fingerprints with characteristics similar to those of real fingerprints. We propose a Generative Adversarial Network (GAN) to synthesize a fingerprint dataset consisting of 100 million fingerprint images. In comparison to published methods, our approach incorporates an identity loss which guides the generator to synthesize a diverse set of fingerprints corresponding to more distinct identities. To demonstrate that the characteristics of our synthesized fingerprints are similar to those of real fingerprints, we show that (i) the NFIQ quality value distribution of the synthetic fingerprints follows the corresponding distribution of real fingerprints and (ii) the synthetic fingerprints are more distinct than existing synthetic fingerprints (and more closely align with the distinctiveness of real fingerprints). We use our synthesis algorithm to generate 100 million fingerprint images in 17.5 hours on 100 Tesla K80 GPUs when executed in parallel. Finally, we report for the first time in open literature, search accuracy (DeepPrint rank-1 accuracy of 91.4%) against a gallery of 100 million fingerprint images (using 2,000 NIST SD4 rolled prints as the queries).
Universal Material Translator: Towards Spoof Fingerprint Generalization
Dec 08, 2019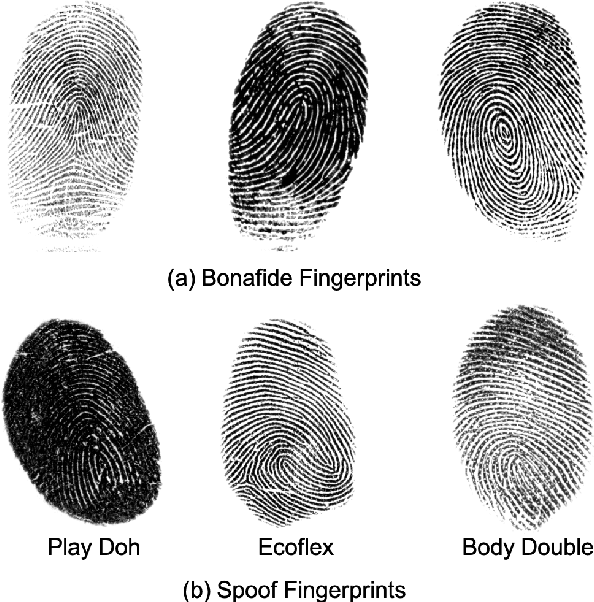
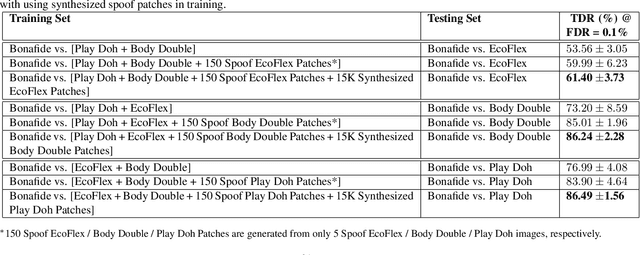
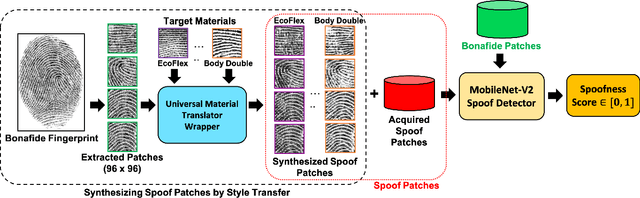
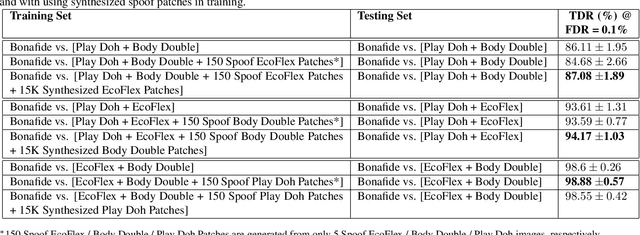
Spoof detectors are classifiers that are trained to distinguish spoof fingerprints from bonafide ones. However, state of the art spoof detectors do not generalize well on unseen spoof materials. This study proposes a style transfer based augmentation wrapper that can be used on any existing spoof detector and can dynamically improve the robustness of the spoof detection system on spoof materials for which we have very low data. Our method is an approach for synthesizing new spoof images from a few spoof examples that transfers the style or material properties of the spoof examples to the content of bonafide fingerprints to generate a larger number of examples to train the classifier on. We demonstrate the effectiveness of our approach on materials in the publicly available LivDet 2015 dataset and show that the proposed approach leads to robustness to fingerprint spoofs of the target material.
* 8 pages, 6 figures, conference
Fingerprint Spoof Generalization
Dec 05, 2019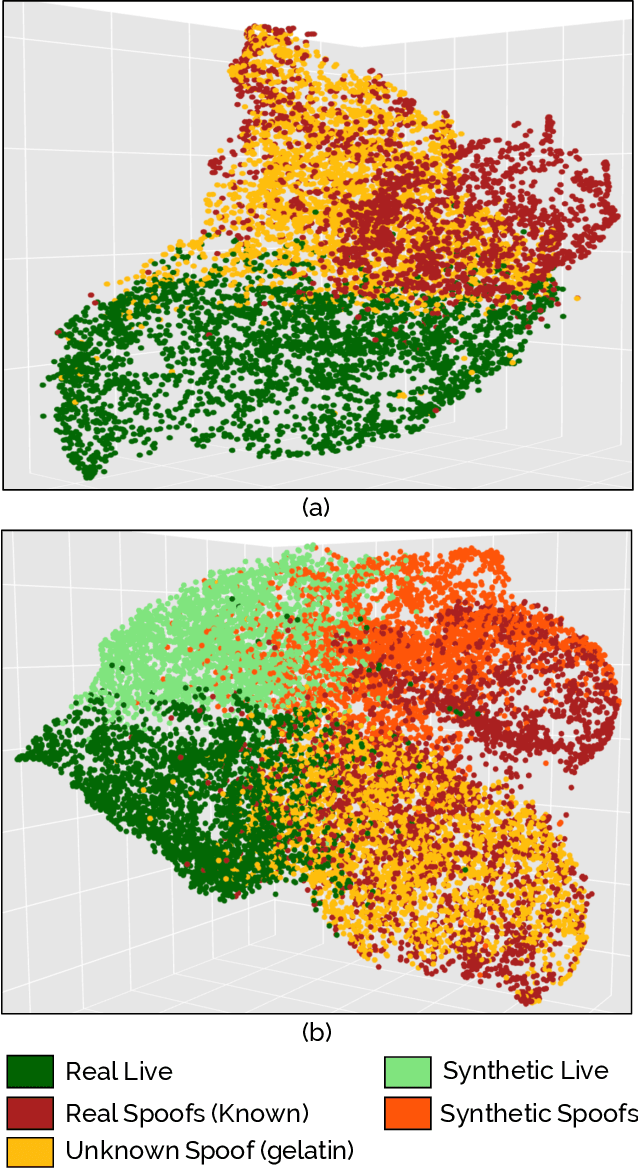


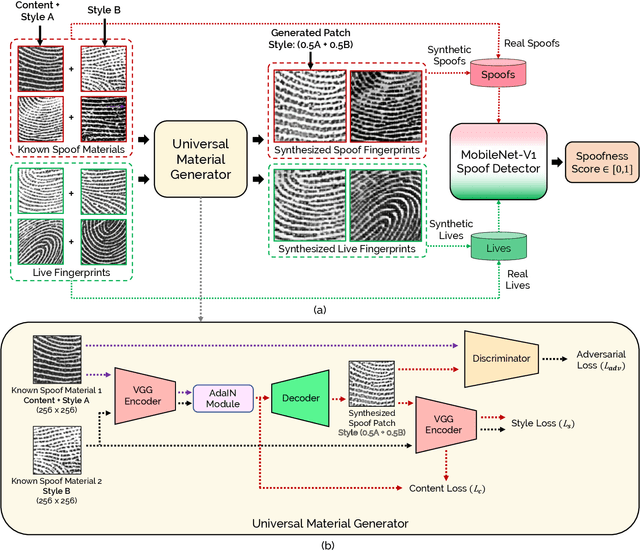
We present a style-transfer based wrapper, called Universal Material Generator (UMG), to improve the generalization performance of any fingerprint spoof detector against spoofs made from materials not seen during training. Specifically, we transfer the style (texture) characteristics between fingerprint images of known materials with the goal of synthesizing fingerprint images corresponding to unknown materials, that may occupy the space between the known materials in the deep feature space. Synthetic live fingerprint images are also added to the training dataset to force the CNN to learn generative-noise invariant features which discriminate between lives and spoofs. The proposed approach is shown to improve the generalization performance of a state-of-the-art spoof detector, namely Fingerprint Spoof Buster, from TDR of 75.24% to 91.78% @ FDR = 0.2%. These results are based on a large-scale dataset of 5,743 live and 4,912 spoof images fabricated using 12 different materials. Additionally, the UMG wrapper is shown to improve the average cross-sensor spoof detection performance from 67.60% to 80.63% when tested on the LivDet 2017 dataset. Training the UMG wrapper requires only 100 live fingerprint images from the target sensor, alleviating the time and resources required to generate large-scale live and spoof datasets for a new sensor. We also fabricate physical spoof artifacts using a mixture of known spoof materials to explore the role of cross-material style transfer in improving generalization performance.
Finding Missing Children: Aging Deep Face Features
Nov 19, 2019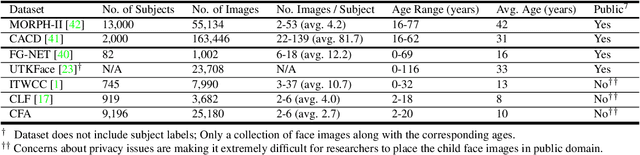



Given a gallery of face images of missing children, state-of-the-art face recognition systems fall short in identifying a child (probe) recovered at a later age. We propose an age-progression module that can age-progress deep face features output by any commodity face matcher. For time lapses larger than 10 years (the missing child is found after 10 or more years), the proposed age-progression module improves the closed-set identification accuracy of FaceNet from 40% to 49.56% and CosFace from 56.88% to 61.25% on a child celebrity dataset, namely ITWCC. The proposed method also outperforms state-of-the-art approaches with a rank-1 identification rate from 94.91% to 95.91% on a public aging dataset, FG-NET, and from 99.50% to 99.58% on CACD-VS. These results suggest that aging face features enhances the ability to identify young children who are possible victims of child trafficking or abduction.
DebFace: De-biasing Face Recognition
Nov 19, 2019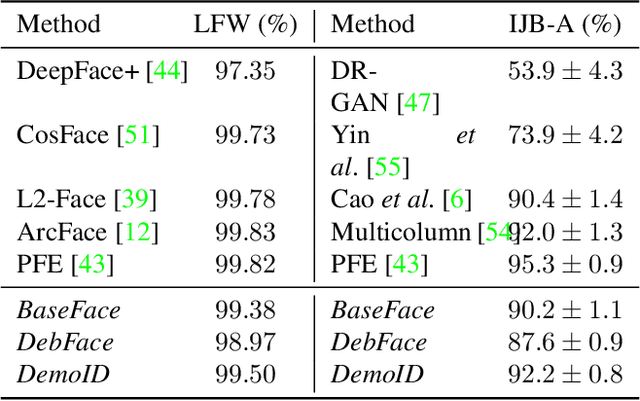
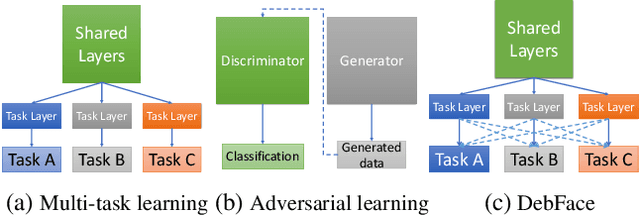
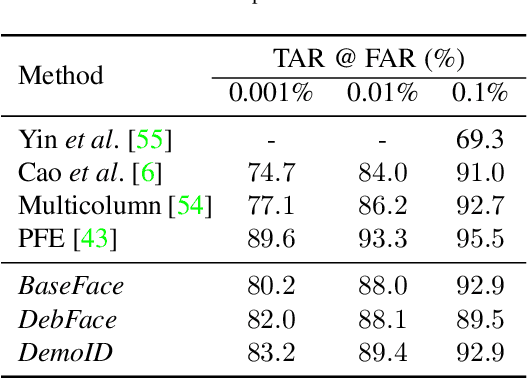
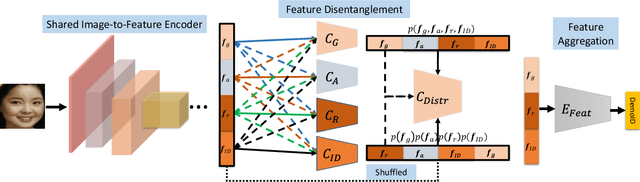
We address the problem of bias in automated face recognition algorithms, where errors are consistently lower on certain cohorts belonging to specific demographic groups. We present a novel de-biasing adversarial network that learns to extract disentangled feature representations for both unbiased face recognition and demographics estimation. The proposed network consists of one identity classifier and three demographic classifiers (for gender, age, and race) that are trained to distinguish identity and demographic attributes, respectively. Adversarial learning is adopted to minimize correlation among feature factors so as to abate bias influence from other factors. We also design a new scheme to combine demographics with identity features to strengthen robustness of face representation in different demographic groups. The experimental results show that our approach is able to reduce bias in face recognition as well as demographics estimation while achieving state-of-the-art performance.
Adversarial Attacks and Defenses in Images, Graphs and Text: A Review
Oct 09, 2019

Deep neural networks (DNN) have achieved unprecedented success in numerous machine learning tasks in various domains. However, the existence of adversarial examples has raised concerns about applying deep learning to safety-critical applications. As a result, we have witnessed increasing interests in studying attack and defense mechanisms for DNN models on different data types, such as images, graphs and text. Thus, it is necessary to provide a systematic and comprehensive overview of the main threats of attacks and the success of corresponding countermeasures. In this survey, we review the state of the art algorithms for generating adversarial examples and the countermeasures against adversarial examples, for the three popular data types, i.e., images, graphs and text.
White-Box Evaluation of Fingerprint Matchers
Sep 23, 2019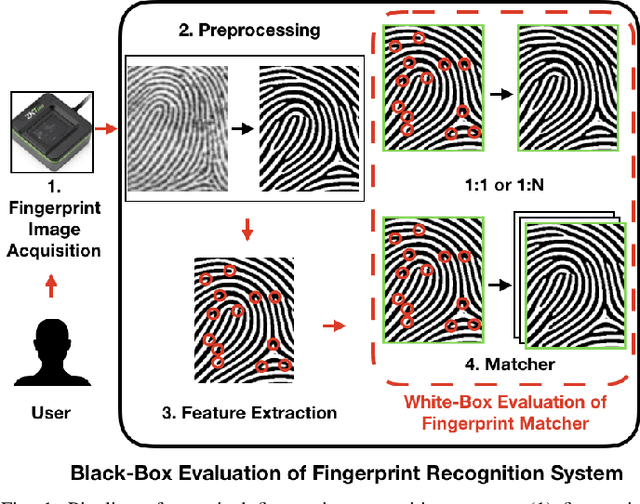
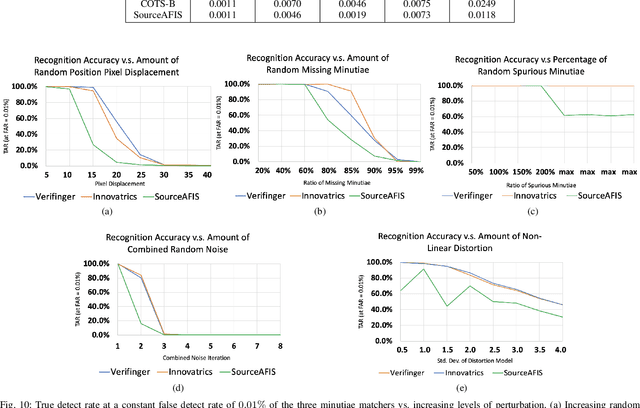


Prevailing evaluations of fingerprint recognition systems have been performed as end-to-end black-box tests of fingerprint identification or verification accuracy. However, performance of the end-to-end system is subject to errors arising in any of the constituent modules, including: fingerprint reader, preprocessing, feature extraction, and matching. While a few studies have conducted white-box testing of the fingerprint reader and feature extraction modules of fingerprint recognition systems, little work has been devoted towards white-box evaluations of the fingerprint matching sub-module. We report results of a controlled, white-box evaluation of one open-source and two commercial-off-the-shelf (COTS) state-of-the-art minutiae-based matchers in terms of their robustness against controlled perturbations (random noise, and non-linear distortions) introduced into the input minutiae feature sets. Experiments were conducted on 10,000 synthetically generated fingerprints. Our white-box evaluations show performance comparisons between different minutiae-based matchers in the presence of various perturbations and non-linear distortion, which were not previously shown with black-box tests. Furthermore, our white-box evaluations reveal that the performance of fingerprint minutiae matchers are more susceptible to non-linear distortion and missing minutiae than spurious minutiae and small positional displacements of the minutiae locations. The measurement uncertainty in fingerprint matching is also developed.
Learning a Fixed-Length Fingerprint Representation
Sep 21, 2019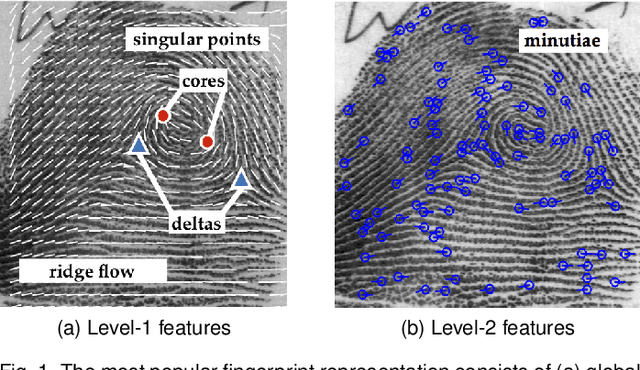


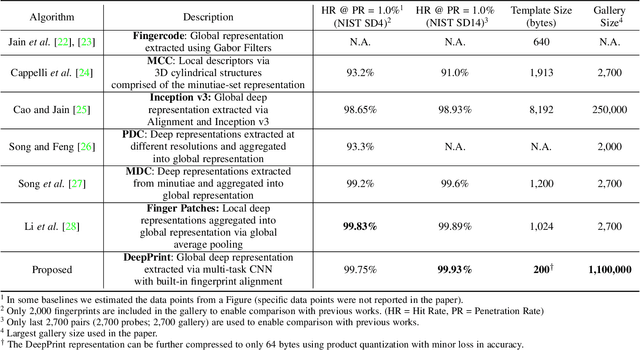
We present DeepPrint, a deep network, which learns to extract fixed-length fingerprint representations of only 200 bytes. DeepPrint incorporates fingerprint domain knowledge, including alignment and minutiae detection, into the deep network architecture to maximize the discriminative power of its representation. The compact, DeepPrint representation has several advantages over the prevailing variable length minutiae representation which (i) requires computationally expensive graph matching techniques, (ii) is difficult to secure using strong encryption schemes (e.g. homomorphic encryption), and (iii) has low discriminative power in poor quality fingerprints where minutiae extraction is unreliable. We benchmark DeepPrint against two top performing COTS SDKs (Verifinger and Innovatrics) from the NIST and FVC evaluations. Coupled with a re-ranking scheme, the DeepPrint rank-1 search accuracy on the NIST SD4 dataset against a gallery of 1.1 million fingerprints is comparable to the top COTS matcher, but it is significantly faster (DeepPrint: 98.80% in 0.3 seconds vs. COTS A: 98.85% in 27 seconds). To the best of our knowledge, the DeepPrint representation is the most compact and discriminative fixed-length fingerprint representation reported in the academic literature.
AdvFaces: Adversarial Face Synthesis
Aug 14, 2019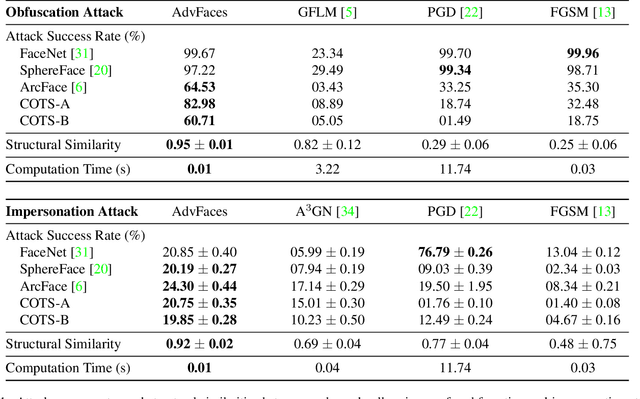

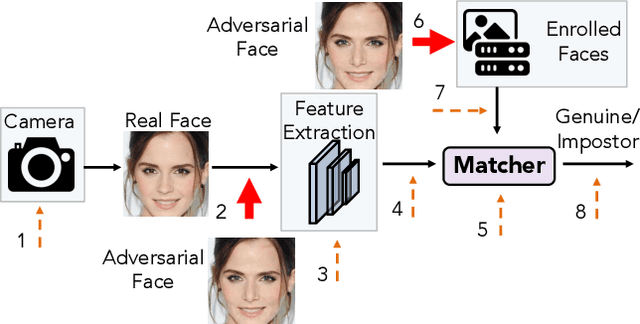
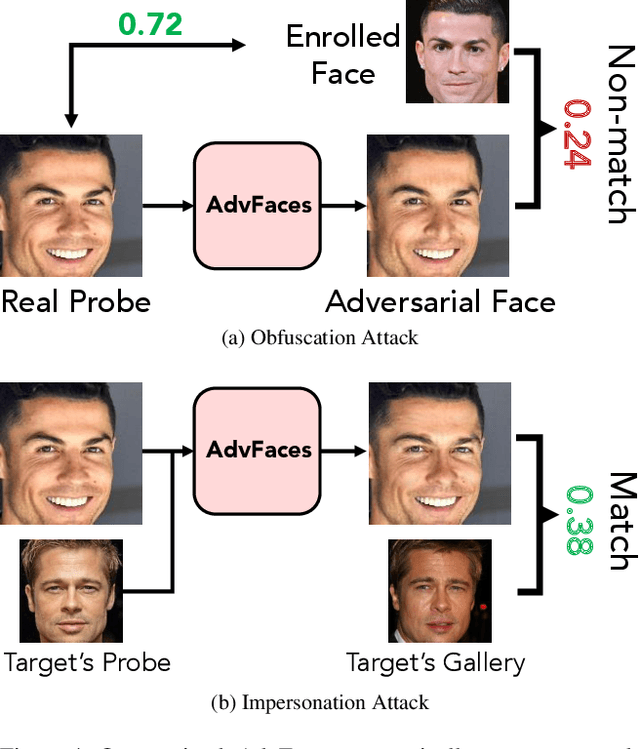
Face recognition systems have been shown to be vulnerable to adversarial examples resulting from adding small perturbations to probe images. Such adversarial images can lead state-of-the-art face recognition systems to falsely reject a genuine subject (obfuscation attack) or falsely match to an impostor (impersonation attack). Current approaches to crafting adversarial face images lack perceptual quality and take an unreasonable amount of time to generate them. We propose, AdvFaces, an automated adversarial face synthesis method that learns to generate minimal perturbations in the salient facial regions via Generative Adversarial Networks. Once AdvFaces is trained, it can automatically generate imperceptible perturbations that can evade state-of-the-art face matchers with attack success rates as high as 97.22% and 24.30% for obfuscation and impersonation attacks, respectively.