 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Place Recognition Under Appearance Change for Autonomous Driving
Aug 01, 2019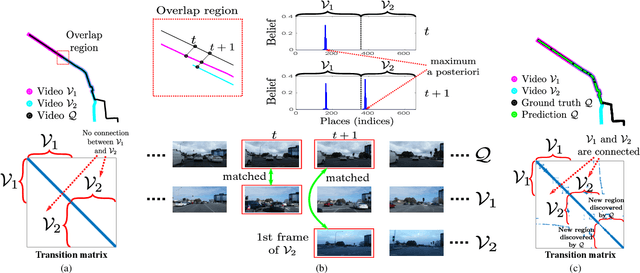
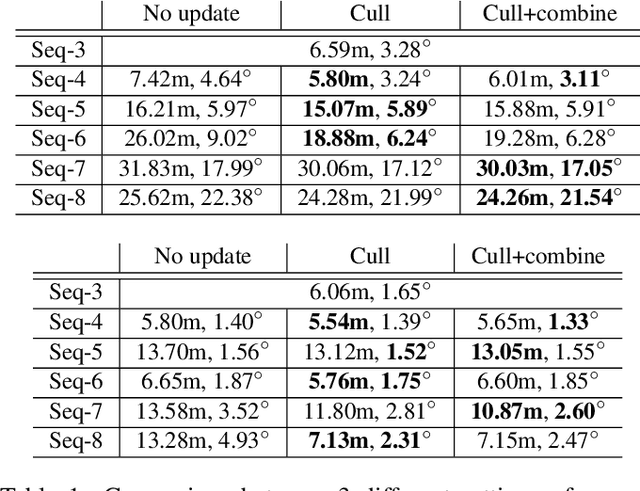
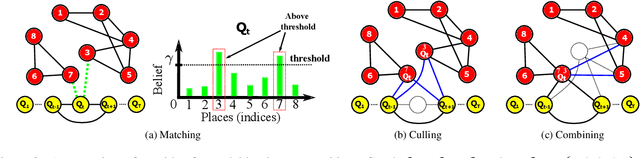
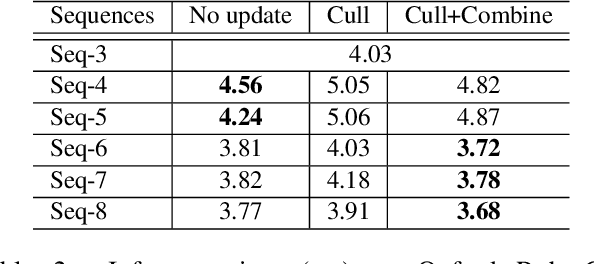
A major challenge in place recognition for autonomous driving is to be robust against appearance changes due to short-term (e.g., weather, lighting) and long-term (seasons, vegetation growth, etc.) environmental variations. A promising solution is to continuously accumulate images to maintain an adequate sample of the conditions and incorporate new changes into the place recognition decision. However, this demands a place recognition technique that is scalable on an ever growing dataset. To this end, we propose a novel place recognition technique that can be efficiently retrained and compressed, such that the recognition of new queries can exploit all available data (including recent changes) without suffering from visible growth in computational cost. Underpinning our method is a novel temporal image matching technique based on Hidden Markov Models. Our experiments show that, compared to state-of-the-art techniques, our method has much greater potential for large-scale place recognition for autonomous driving.
Practical Visual Localization for Autonomous Driving: Why Not Filter?
Nov 20, 2018
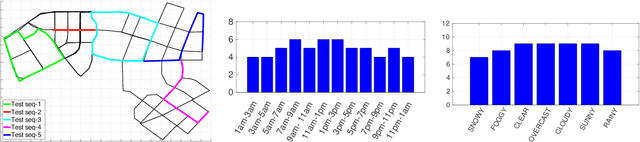

A major focus of current research on place recognition is visual localization for autonomous driving. However, while many visual localization algorithms for autonomous driving have achieved impressive results, it seems not all previous works have been set in a realistic setting for the problem, namely using training and testing videos that were collected in a distributed manner from multiple vehicles, all traversing through a road network in an urban area under different environmental conditions (weather, lighting, etc.). More importantly, in this setting, we show that exploiting temporal continuity in the testing sequence significantly improves visual localization - qualitatively and quantitatively. Although intuitive, this idea has not been fully explored in recent works. Our main contribution is a novel particle filtering technique that works in conjunction with a visual localization method to achieve accurate city-scale localization that is robust against environmental variations. We provide convincing results on synthetic and real datasets.
G2D: from GTA to Data
Jun 16, 2018
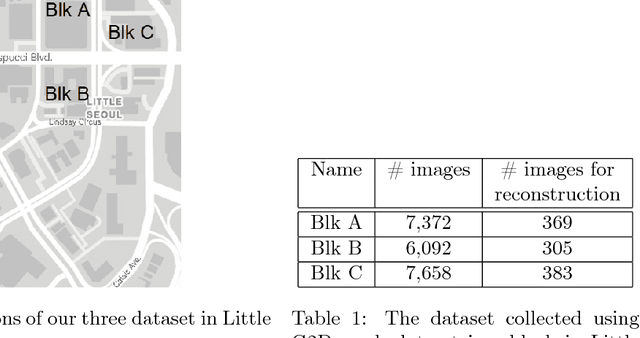
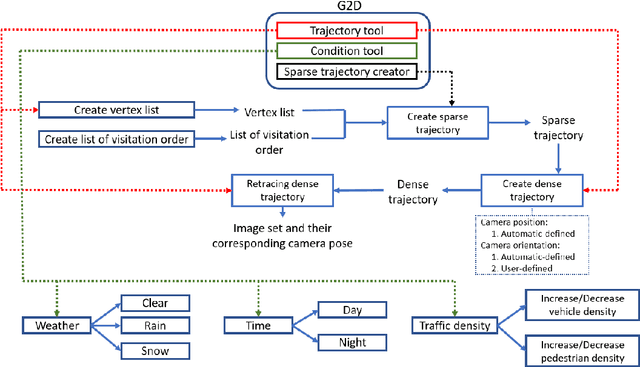
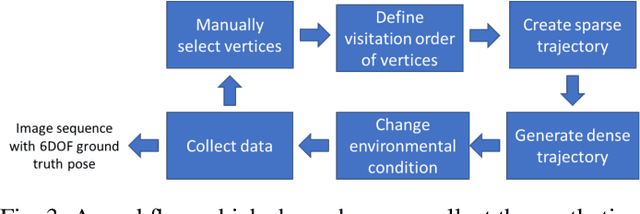
This document describes G2D, a software that enables capturing videos from Grand Theft Auto V (GTA V), a popular role playing game set in an expansive virtual city. The target users of our software are computer vision researchers who wish to collect hyper-realistic computer-generated imagery of a city from the street level, under controlled 6DOF camera poses and varying environmental conditions (weather, season, time of day, traffic density, etc.). G2D accesses/calls the native functions of the game; hence users can directly interact with G2D while playing the game. Specifically, G2D enables users to manipulate conditions of the virtual environment on the fly, while the gameplay camera is set to automatically retrace a predetermined 6DOF camera pose trajectory within the game coordinate system. Concurrently, automatic screen capture is executed while the virtual environment is being explored. G2D and its source code are publicly available at https://goo.gl/SS7fS6 In addition, we demonstrate an application of G2D to generate a large-scale dataset with groundtruth camera poses for testing structure-from-motion (SfM) algorithms. The dataset and generated 3D point clouds are also made available at https://goo.gl/DNzxHx
On-device Scalable Image-based Localization
Feb 10, 2018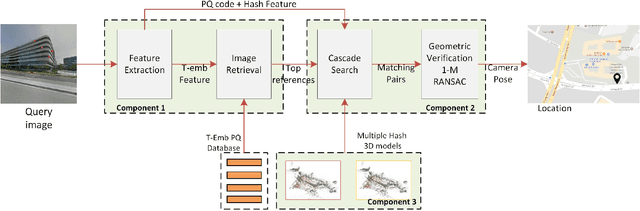

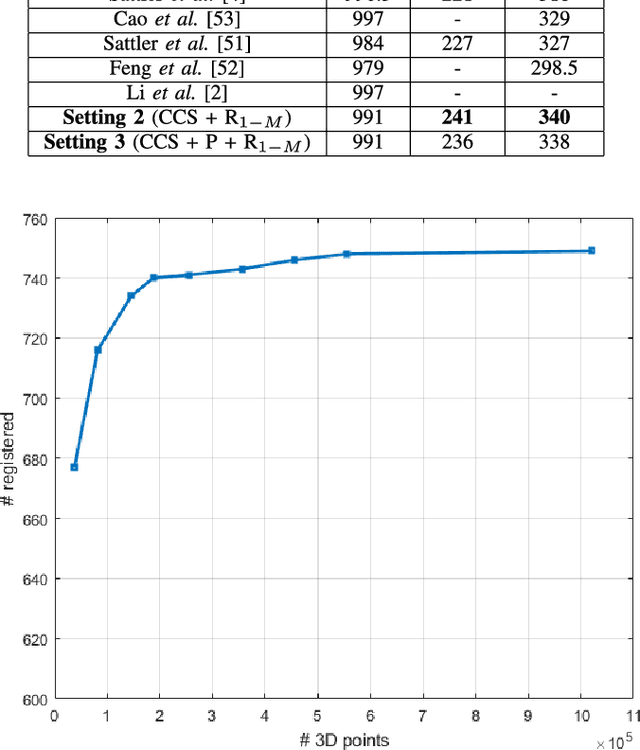

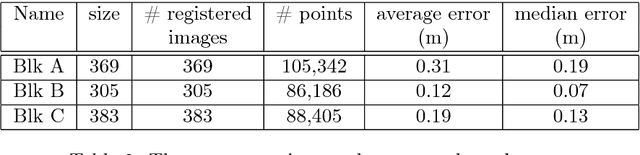
We present the scalable design of an entire on-device system for large-scale urban localization. The proposed design integrates compact image retrieval and 2D-3D correspondence search to estimate the camera pose in a city region of extensive coverage. Our design is GPS agnostic and does not require the network connection. The system explores the use of an abundant dataset: Google Street View (GSV). In order to overcome the resource constraints of mobile devices, we carefully optimize the system design at every stage: we use state-of-the-art image retrieval to quickly locate candidate regions and limit candidate 3D points; we propose a new hashing-based approach for fast computation of 2D-3D correspondences and new one-many RANSAC for accurate pose estimation. The experiments are conducted on benchmark datasets for 2D-3D correspondence search and on a database of over 227K Google Street View (GSV) images for the overall system. Results show that our 2D-3D correspondence search achieves state-of-the-art performance on some benchmark datasets and our system can accurately and quickly localize mobile images; the median error is less than 4 meters and the processing time is averagely less than 10s on a typical mobile device.
Binary Hashing with Semidefinite Relaxation and Augmented Lagrangian
Jul 19, 2016
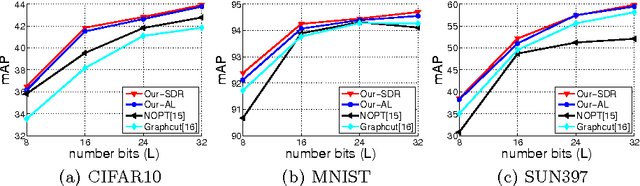
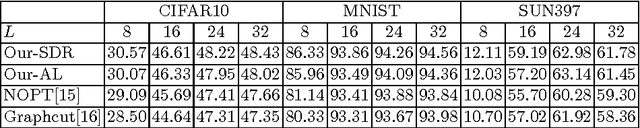
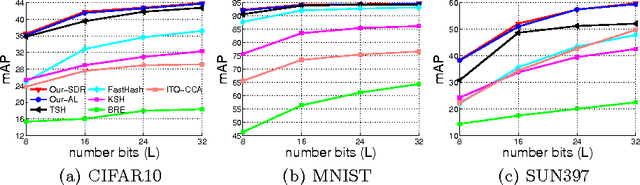
This paper proposes two approaches for inferencing binary codes in two-step (supervised, unsupervised) hashing. We first introduce an unified formulation for both supervised and unsupervised hashing. Then, we cast the learning of one bit as a Binary Quadratic Problem (BQP). We propose two approaches to solve BQP. In the first approach, we relax BQP as a semidefinite programming problem which its global optimum can be achieved. We theoretically prove that the objective value of the binary solution achieved by this approach is well bounded. In the second approach, we propose an augmented Lagrangian based approach to solve BQP directly without relaxing the binary constraint. Experimental results on three benchmark datasets show that our proposed methods compare favorably with the state of the art.
Learning to Hash with Binary Deep Neural Network
Jul 18, 2016
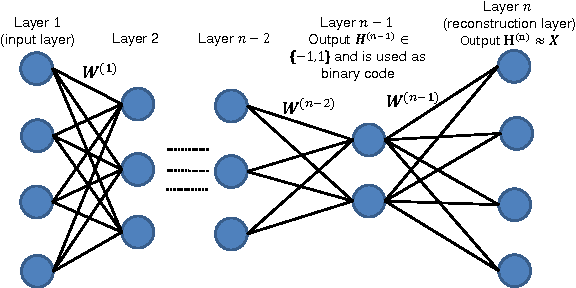
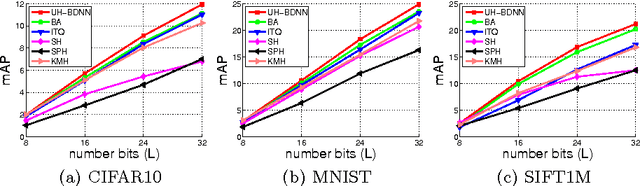
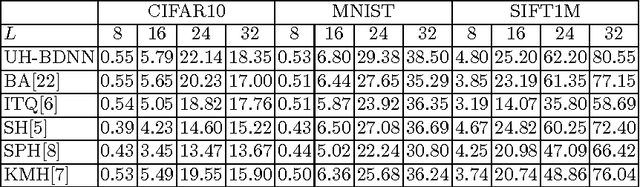
This work proposes deep network models and learning algorithms for unsupervised and supervised binary hashing. Our novel network design constrains one hidden layer to directly output the binary codes. This addresses a challenging issue in some previous works: optimizing non-smooth objective functions due to binarization. Moreover, we incorporate independence and balance properties in the direct and strict forms in the learning. Furthermore, we include similarity preserving property in our objective function. Our resulting optimization with these binary, independence, and balance constraints is difficult to solve. We propose to attack it with alternating optimization and careful relaxation. Experimental results on three benchmark datasets show that our proposed methods compare favorably with the state of the art.