 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot, No Problem: Descriptive Continual Relation Extraction
Feb 27, 2025Few-shot Continual Relation Extraction is a crucial challenge for enabling AI systems to identify and adapt to evolving relationships in dynamic real-world domains. Traditional memory-based approaches often overfit to limited samples, failing to reinforce old knowledge, with the scarcity of data in few-shot scenarios further exacerbating these issues by hindering effective data augmentation in the latent space. In this paper, we propose a novel retrieval-based solution, starting with a large language model to generate descriptions for each relation. From these descriptions, we introduce a bi-encoder retrieval training paradigm to enrich both sample and class representation learning. Leveraging these enhanced representations, we design a retrieval-based prediction method where each sample "retrieves" the best fitting relation via a reciprocal rank fusion score that integrates both relation description vectors and class prototypes. Extensive experiments on multiple datasets demonstrate that our method significantly advances the state-of-the-art by maintaining robust performance across sequential tasks, effectively addressing catastrophic forgetting.
CoT2Align: Cross-Chain of Thought Distillation via Optimal Transport Alignment for Language Models with Different Tokenizers
Feb 25, 2025



Large Language Models (LLMs) achieve state-of-the-art performance across various NLP tasks but face deployment challenges due to high computational costs and memory constraints. Knowledge distillation (KD) is a promising solution, transferring knowledge from large teacher models to smaller student models. However, existing KD methods often assume shared vocabularies and tokenizers, limiting their flexibility. While approaches like Universal Logit Distillation (ULD) and Dual-Space Knowledge Distillation (DSKD) address vocabulary mismatches, they overlook the critical \textbf{reasoning-aware distillation} aspect. To bridge this gap, we propose CoT2Align a universal KD framework that integrates Chain-of-Thought (CoT) augmentation and introduces Cross-CoT Alignment to enhance reasoning transfer. Additionally, we extend Optimal Transport beyond token-wise alignment to a sequence-level and layer-wise alignment approach that adapts to varying sequence lengths while preserving contextual integrity. Comprehensive experiments demonstrate that CoT2Align outperforms existing KD methods across different vocabulary settings, improving reasoning capabilities and robustness in domain-specific tasks.
Disaster Tweets Classification using BERT-Based Language Model
Jan 31, 2022
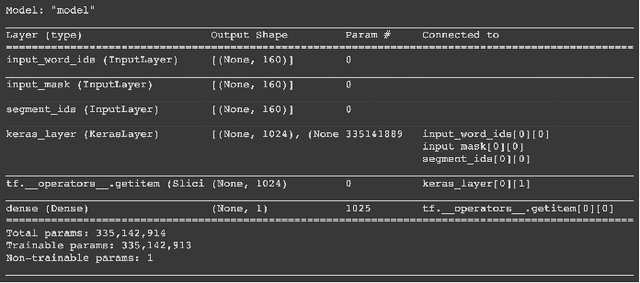
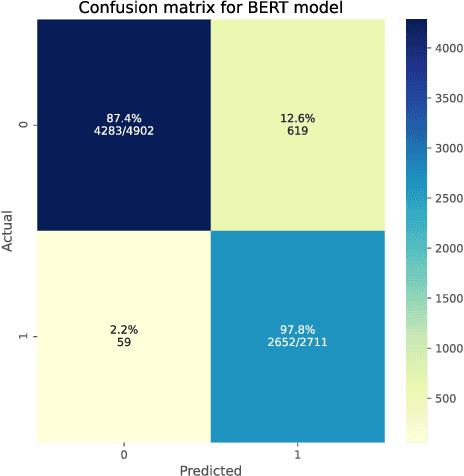
Social networking services have became an important communication channel in time of emergency. The aim of this study is to create a machine learning language model that is able to investigate if a person or area was in danger or not. The ubiquitousness of smartphones enables people to announce an emergency they are observing in real-time. Because of this, more agencies are interested in programmatically monitoring Twitter (i.e. disaster relief organizations and news agencies). Design a language model that is able to understand and acknowledge when a disaster is happening based on the social network posts will become more and more necessary over time.
Automated Transcription for Pre-Modern Japanese Kuzushiji Documents by Random Lines Erasure and Curriculum Learning
May 06, 2020
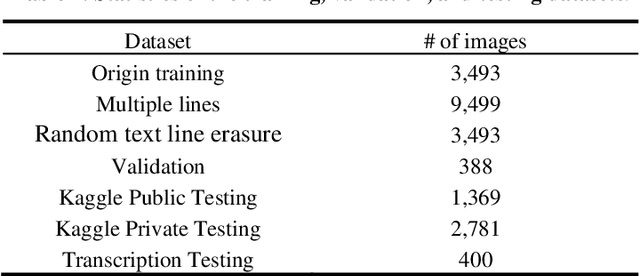
Recognizing the full-page of Japanese historical documents is a challenging problem due to the complex layout/background and difficulty of writing styles, such as cursive and connected characters. Most of the previous methods divided the recognition process into character segmentation and recognition. However, those methods provide only character bounding boxes and classes without text transcription. In this paper, we enlarge our previous humaninspired recognition system from multiple lines to the full-page of Kuzushiji documents. The human-inspired recognition system simulates human eye movement during the reading process. For the lack of training data, we propose a random text line erasure approach that randomly erases text lines and distorts documents. For the convergence problem of the recognition system for fullpage documents, we employ curriculum learning that trains the recognition system step by step from the easy level (several text lines of documents) to the difficult level (full-page documents). We tested the step training approach and random text line erasure approach on the dataset of the Kuzushiji recognition competition on Kaggle. The results of the experiments demonstrate the effectiveness of our proposed approaches. These results are competitive with other participants of the Kuzushiji recognition competition.
Deep Learning Approach for Receipt Recognition
May 30, 2019

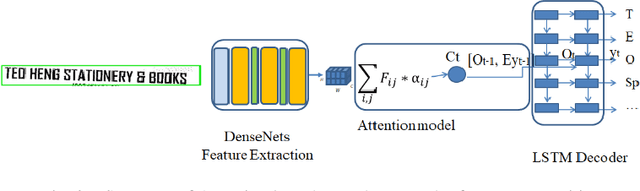

Inspired by the recent successes of deep learning on Computer Vision and Natural Language Processing, we present a deep learning approach for recognizing scanned receipts. The recognition system has two main modules: text detection based on Connectionist Text Proposal Network and text recognition based on Attention-based Encoder-Decoder. We also proposed pre-processing to extract receipt area and OCR verification to ignore handwriting. The experiments on the dataset of the Robust Reading Challenge on Scanned Receipts OCR and Information Extraction 2019 demonstrate that the accuracies were improved by integrating the pre-processing and the OCR verification. Our recognition system achieved 71.9% of the F1 score for detection and recognition task.
End to End Recognition System for Recognizing Offline Unconstrained Vietnamese Handwriting
May 14, 2019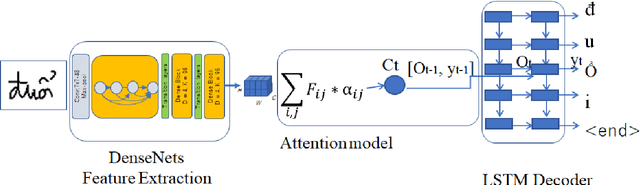
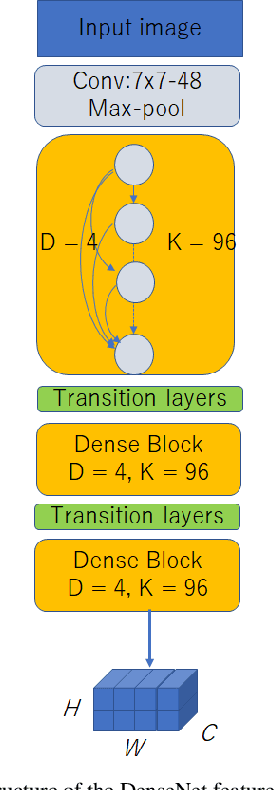
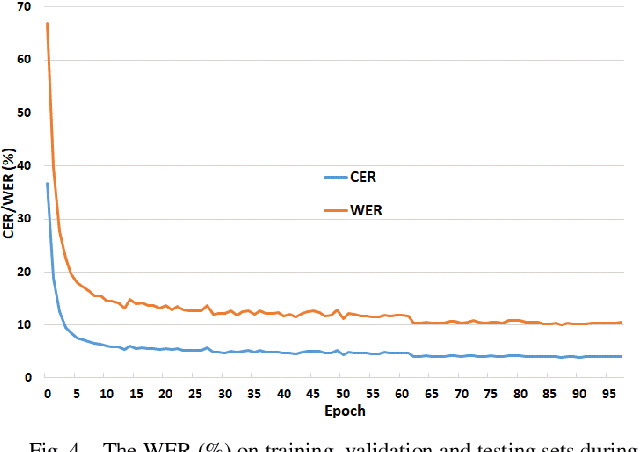

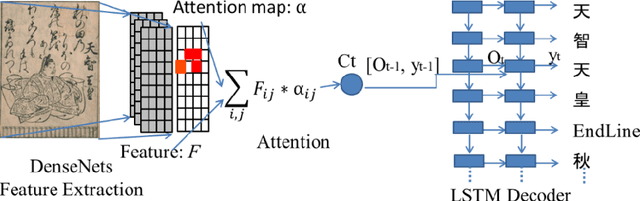
Inspired by recent successes in neural machine translation and image caption generation, we present an attention based encoder decoder model (AED) to recognize Vietnamese Handwritten Text. The model composes of two parts: a DenseNet for extracting invariant features, and a Long Short-Term Memory network (LSTM) with an attention model incorporated for generating output text (LSTM decoder), which are connected from the CNN part to the attention model. The input of the CNN part is a handwritten text image and the target of the LSTM decoder is the corresponding text of the input image. Our model is trained end-to-end to predict the text from a given input image since all the parts are differential components. In the experiment section, we evaluate our proposed AED model on the VNOnDB-Word and VNOnDB-Line datasets to verify its efficiency. The experiential results show that our model achieves 12.30% of word error rate without using any language model. This result is competitive with the handwriting recognition system provided by Google in the Vietnamese Online Handwritten Text Recognition competition.
A human-inspired recognition system for premodern Japanese historical documents
May 14, 2019


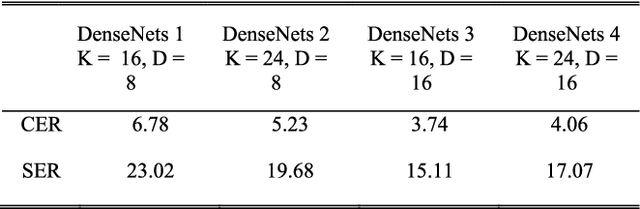
Recognition of historical documents is a challenging problem due to the noised, damaged characters and background. However, in Japanese historical documents, not only contains the mentioned problems, pre-modern Japanese characters were written in cursive and are connected. Therefore, character segmentation based methods do not work well. This leads to the idea of creating a new recognition system. In this paper, we propose a human-inspired document reading system to recognize multiple lines of premodern Japanese historical documents. During the reading, people employ eyes movement to determine the start of a text line. Then, they move the eyes from the current character/word to the next character/word. They can also determine the end of a line or skip a figure to move to the next line. The eyes movement integrates with visual processing to operate the reading process in the brain. We employ attention-based encoder-decoder to implement this recognition system. First, the recognition system detects where to start a text line. Second, the system scans and recognize character by character until the text line is completed. Then, the system continues to detect the start of the next text line. This process is repeated until reading the whole document. We tested our human-inspired recognition system on the pre-modern Japanese historical document provide by the PRMU Kuzushiji competition. The results of the experiments demonstrate the superiority and effectiveness of our proposed system by achieving Sequence Error Rate of 9.87% and 53.81% on level 2 and level 3 of the dataset, respectively. These results outperform to any other systems participated in the PRMU Kuzushiji competition.
Pattern Generation Strategies for Improving Recognition of Handwritten Mathematical Expressions
Jan 21, 2019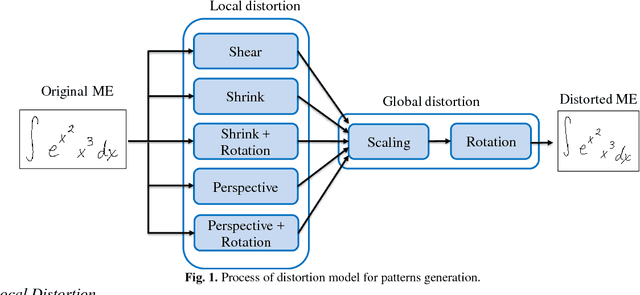
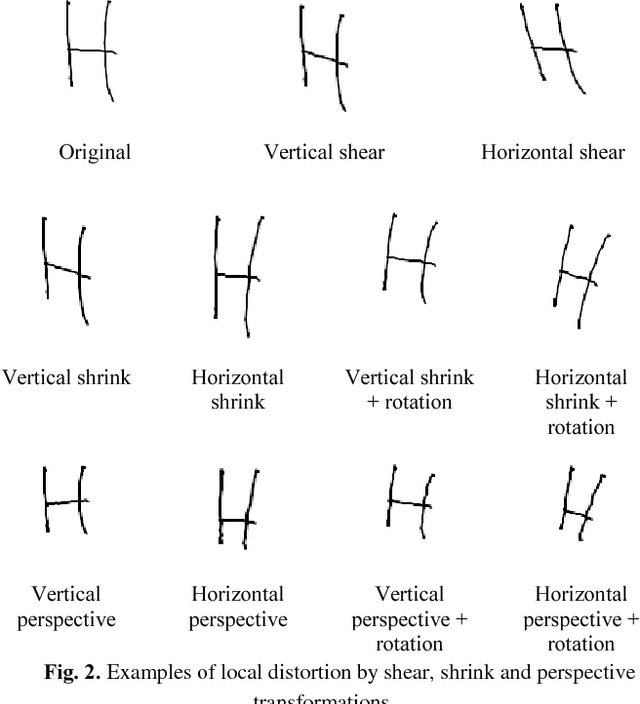

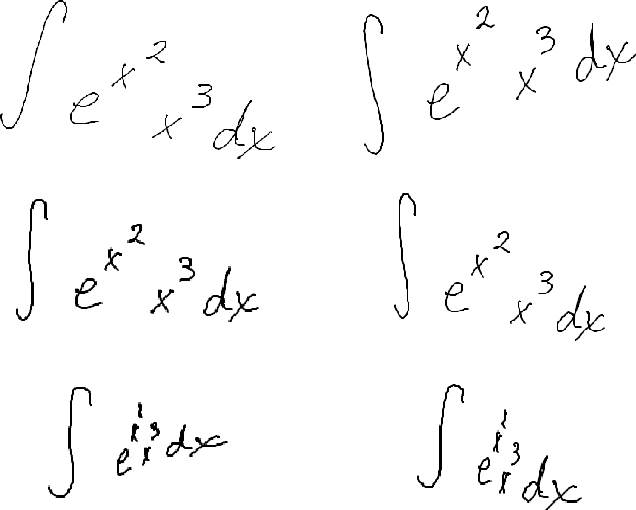
Recognition of Handwritten Mathematical Expressions (HMEs) is a challenging problem because of the ambiguity and complexity of two-dimensional handwriting. Moreover, the lack of large training data is a serious issue, especially for academic recognition systems. In this paper, we propose pattern generation strategies that generate shape and structural variations to improve the performance of recognition systems based on a small training set. For data generation, we employ the public databases: CROHME 2014 and 2016 of online HMEs. The first strategy employs local and global distortions to generate shape variations. The second strategy decomposes an online HME into sub-online HMEs to get more structural variations. The hybrid strategy combines both these strategies to maximize shape and structural variations. The generated online HMEs are converted to images for offline HME recognition. We tested our strategies in an end-to-end recognition system constructed from a recent deep learning model: Convolutional Neural Network and attention-based encoder-decoder. The results of experiments on the CROHME 2014 and 2016 databases demonstrate the superiority and effectiveness of our strategies: our hybrid strategy achieved classification rates of 48.78% and 45.60%, respectively, on these databases. These results are competitive compared to others reported in recent literature. Our generated datasets are openly available for research community and constitute a useful resource for the HME recognition research in future.
Outlier Detection using Generative Models with Theoretical Performance Guarantees
Oct 26, 2018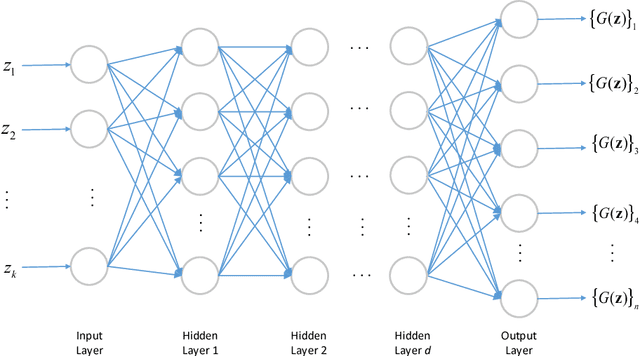

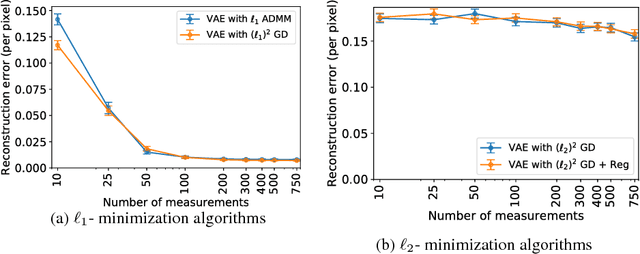
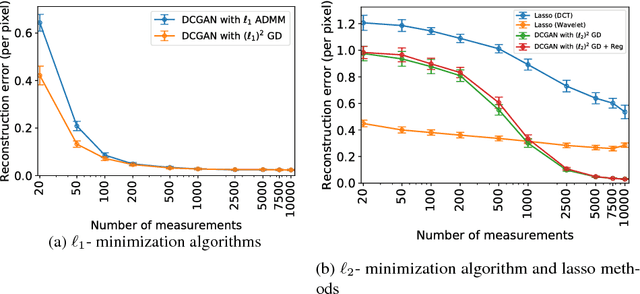
This paper considers the problem of recovering signals from compressed measurements contaminated with sparse outliers, which has arisen in many applications. In this paper, we propose a generative model neural network approach for reconstructing the ground truth signals under sparse outliers. We propose an iterative alternating direction method of multipliers (ADMM) algorithm for solving the outlier detection problem via $\ell_1$ norm minimization, and a gradient descent algorithm for solving the outlier detection problem via squared $\ell_1$ norm minimization. We establish the recovery guarantees for reconstruction of signals using generative models in the presence of outliers, and give an upper bound on the number of outliers allowed for recovery. Our results are applicable to both the linear generator neural network and the nonlinear generator neural network with an arbitrary number of layers. We conduct extensive experiments using variational auto-encoder and deep convolutional generative adversarial networks, and the experimental results show that the signals can be successfully reconstructed under outliers using our approach. Our approach outperforms the traditional Lasso and $\ell_2$ minimization approach.