 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIberBench: LLM Evaluation on Iberian Languages
Apr 23, 2025Large Language Models (LLMs) remain difficult to evaluate comprehensively, particularly for languages other than English, where high-quality data is often limited. Existing benchmarks and leaderboards are predominantly English-centric, with only a few addressing other languages. These benchmarks fall short in several key areas: they overlook the diversity of language varieties, prioritize fundamental Natural Language Processing (NLP) capabilities over tasks of industrial relevance, and are static. With these aspects in mind, we present IberBench, a comprehensive and extensible benchmark designed to assess LLM performance on both fundamental and industry-relevant NLP tasks, in languages spoken across the Iberian Peninsula and Ibero-America. IberBench integrates 101 datasets from evaluation campaigns and recent benchmarks, covering 22 task categories such as sentiment and emotion analysis, toxicity detection, and summarization. The benchmark addresses key limitations in current evaluation practices, such as the lack of linguistic diversity and static evaluation setups by enabling continual updates and community-driven model and dataset submissions moderated by a committee of experts. We evaluate 23 LLMs ranging from 100 million to 14 billion parameters and provide empirical insights into their strengths and limitations. Our findings indicate that (i) LLMs perform worse on industry-relevant tasks than in fundamental ones, (ii) performance is on average lower for Galician and Basque, (iii) some tasks show results close to random, and (iv) in other tasks LLMs perform above random but below shared task systems. IberBench offers open-source implementations for the entire evaluation pipeline, including dataset normalization and hosting, incremental evaluation of LLMs, and a publicly accessible leaderboard.
Unsupervised Ranking and Aggregation of Label Descriptions for Zero-Shot Classifiers
Apr 20, 2022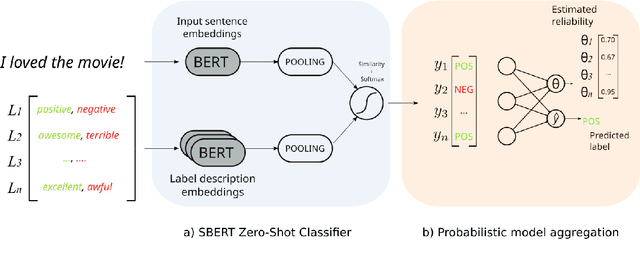
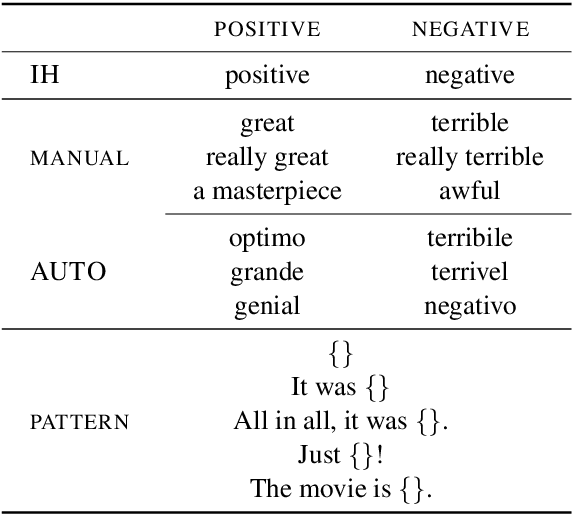
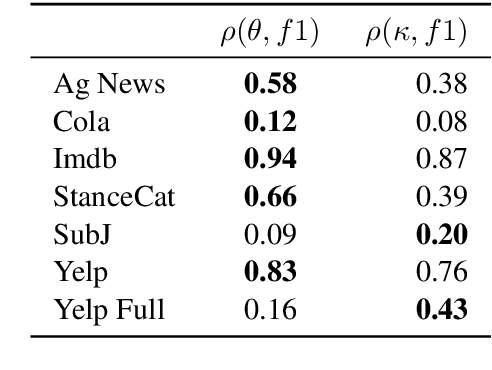
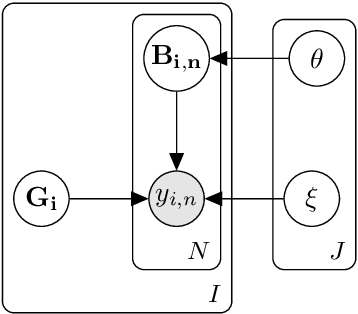
Zero-shot text classifiers based on label descriptions embed an input text and a set of labels into the same space: measures such as cosine similarity can then be used to select the most similar label description to the input text as the predicted label. In a true zero-shot setup, designing good label descriptions is challenging because no development set is available. Inspired by the literature on Learning with Disagreements, we look at how probabilistic models of repeated rating analysis can be used for selecting the best label descriptions in an unsupervised fashion. We evaluate our method on a set of diverse datasets and tasks (sentiment, topic and stance). Furthermore, we show that multiple, noisy label descriptions can be aggregated to boost the performance.
Active Few-Shot Learning with FASL
Apr 20, 2022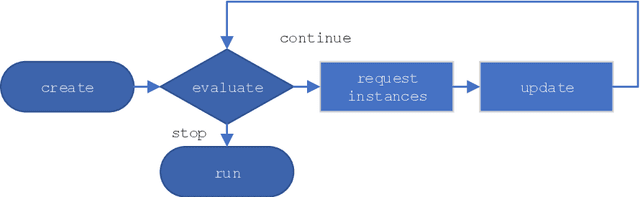
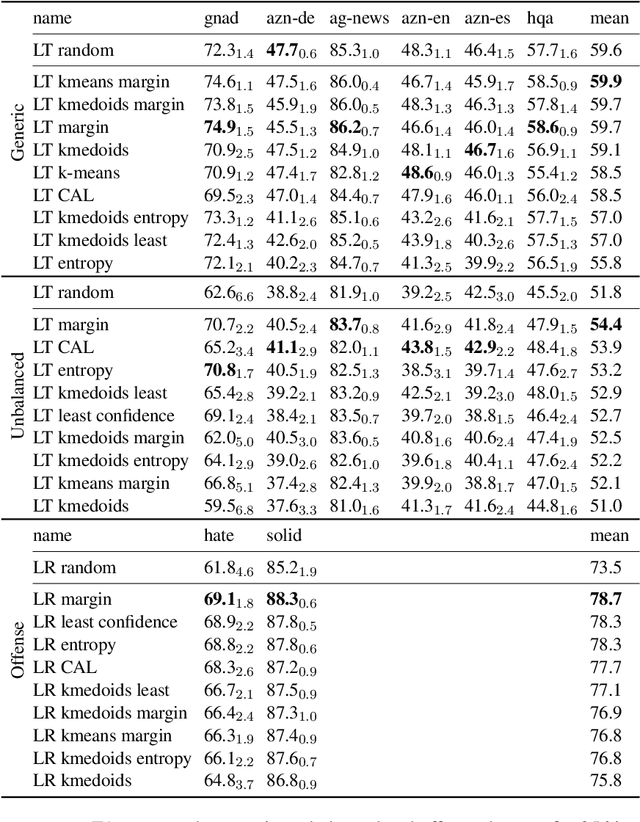
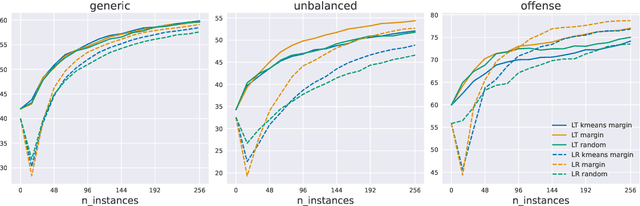
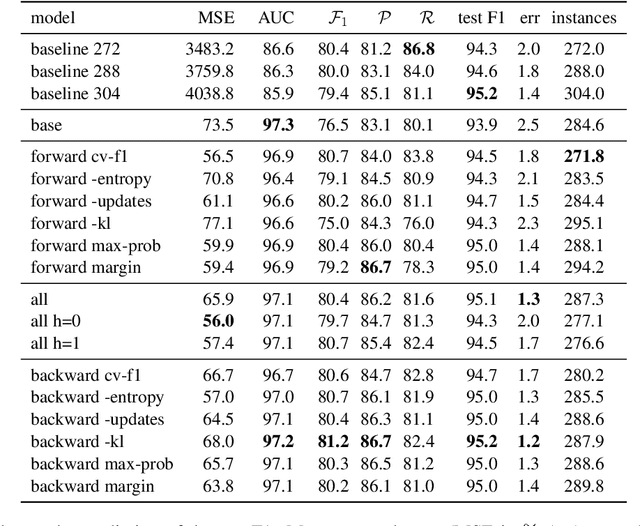
Recent advances in natural language processing (NLP) have led to strong text classification models for many tasks. However, still often thousands of examples are needed to train models with good quality. This makes it challenging to quickly develop and deploy new models for real world problems and business needs. Few-shot learning and active learning are two lines of research, aimed at tackling this problem. In this work, we combine both lines into FASL, a platform that allows training text classification models using an iterative and fast process. We investigate which active learning methods work best in our few-shot setup. Additionally, we develop a model to predict when to stop annotating. This is relevant as in a few-shot setup we do not have access to a large validation set.
You Write Like You Eat: Stylistic variation as a predictor of social stratification
Jul 16, 2019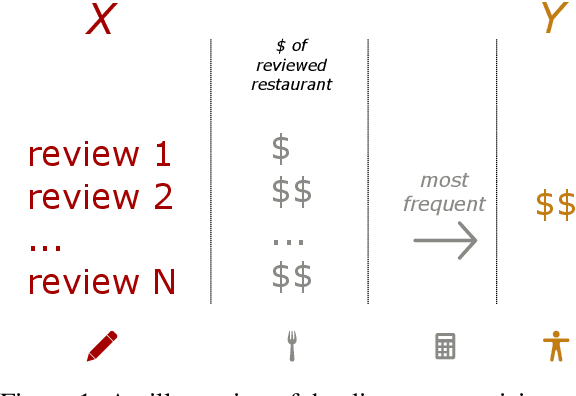

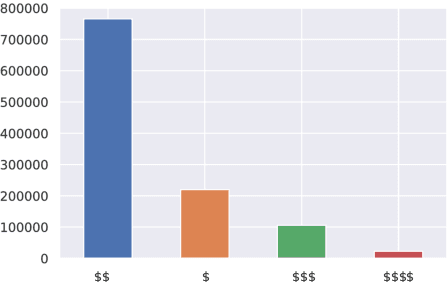
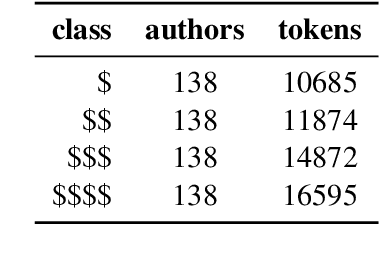
Inspired by Labov's seminal work on stylistic variation as a function of social stratification, we develop and compare neural models that predict a person's presumed socio-economic status, obtained through distant supervision,from their writing style on social media. The focus of our work is on identifying the most important stylistic parameters to predict socio-economic group. In particular, we show the effectiveness of morpho-syntactic features as stylistic predictors of socio-economic group,in contrast to lexical features, which are good predictors of topic.
N-GrAM: New Groningen Author-profiling Model
Jul 12, 2017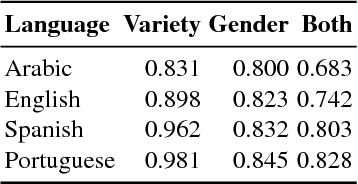


We describe our participation in the PAN 2017 shared task on Author Profiling, identifying authors' gender and language variety for English, Spanish, Arabic and Portuguese. We describe both the final, submitted system, and a series of negative results. Our aim was to create a single model for both gender and language, and for all language varieties. Our best-performing system (on cross-validated results) is a linear support vector machine (SVM) with word unigrams and character 3- to 5-grams as features. A set of additional features, including POS tags, additional datasets, geographic entities, and Twitter handles, hurt, rather than improve, performance. Results from cross-validation indicated high performance overall and results on the test set confirmed them, at 0.86 averaged accuracy, with performance on sub-tasks ranging from 0.68 to 0.98.