 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeN-GrAM: New Groningen Author-profiling Model
Paper and Code
Jul 12, 2017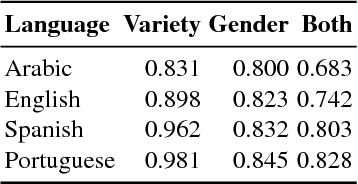


We describe our participation in the PAN 2017 shared task on Author Profiling, identifying authors' gender and language variety for English, Spanish, Arabic and Portuguese. We describe both the final, submitted system, and a series of negative results. Our aim was to create a single model for both gender and language, and for all language varieties. Our best-performing system (on cross-validated results) is a linear support vector machine (SVM) with word unigrams and character 3- to 5-grams as features. A set of additional features, including POS tags, additional datasets, geographic entities, and Twitter handles, hurt, rather than improve, performance. Results from cross-validation indicated high performance overall and results on the test set confirmed them, at 0.86 averaged accuracy, with performance on sub-tasks ranging from 0.68 to 0.98.