 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMO-CTranS: A unified multi-organ segmentation model learning from multiple heterogeneously labelled datasets
Mar 28, 2025


Multi-organ segmentation holds paramount significance in many clinical tasks. In practice, compared to large fully annotated datasets, multiple small datasets are often more accessible and organs are not labelled consistently. Normally, an individual model is trained for each of these datasets, which is not an effective way of using data for model learning. It remains challenging to train a single model that can robustly learn from several partially labelled datasets due to label conflict and data imbalance problems. We propose MO-CTranS: a single model that can overcome such problems. MO-CTranS contains a CNN-based encoder and a Transformer-based decoder, which are connected in a multi-resolution manner. Task-specific tokens are introduced in the decoder to help differentiate label discrepancies. Our method was evaluated and compared to several baseline models and state-of-the-art (SOTA) solutions on abdominal MRI datasets that were acquired in different views (i.e. axial and coronal) and annotated for different organs (i.e. liver, kidney, spleen). Our method achieved better performance (most were statistically significant) than the compared methods. Github link: https://github.com/naisops/MO-CTranS.
Ethics of Generating Synthetic MRI Vocal Tract Views from the Face
Jul 11, 2024
Forming oral models capable of understanding the complete dynamics of the oral cavity is vital across research areas such as speech correction, designing foods for the aging population, and dentistry. Magnetic resonance imaging (MRI) technologies, capable of capturing oral data essential for creating such detailed representations, offer a powerful tool for illustrating articulatory dynamics. However, its real-time application is hindered by expense and expertise requirements. Ever advancing generative AI approaches present themselves as a way to address this barrier by leveraging multi-modal approaches for generating pseudo-MRI views. Nonetheless, this immediately sparks ethical concerns regarding the utilisation of a technology with the capability to produce MRIs from facial observations. This paper explores the ethical implications of external-to-internal correlation modeling (E2ICM). E2ICM utilises facial movements to infer internal configurations and provides a cost-effective supporting technology for MRI. In this preliminary work, we employ Pix2PixGAN to generate pseudo-MRI views from external articulatory data, demonstrating the feasibility of this approach. Ethical considerations concerning privacy, consent, and potential misuse, which are fundamental to our examination of this innovative methodology, are discussed as a result of this experimentation.
Uncovering the Metaverse within Everyday Environments: a Coarse-to-Fine Approach
Apr 11, 2024



The recent release of the Apple Vision Pro has reignited interest in the metaverse, showcasing the intensified efforts of technology giants in developing platforms and devices to facilitate its growth. As the metaverse continues to proliferate, it is foreseeable that everyday environments will become increasingly saturated with its presence. Consequently, uncovering links to these metaverse items will be a crucial first step to interacting with this new augmented world. In this paper, we address the problem of establishing connections with virtual worlds within everyday environments, especially those that are not readily discernible through direct visual inspection. We introduce a vision-based approach leveraging Artcode visual markers to uncover hidden metaverse links embedded in our ambient surroundings. This approach progressively localises the access points to the metaverse, transitioning from coarse to fine localisation, thus facilitating an exploratory interaction process. Detailed experiments are conducted to study the performance of the proposed approach, demonstrating its effectiveness in Artcode localisation and enabling new interaction opportunities.
ConvTransSeg: A Multi-resolution Convolution-Transformer Network for Medical Image Segmentation
Oct 13, 2022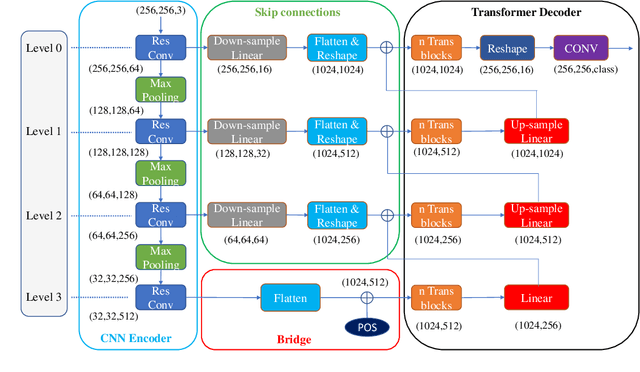
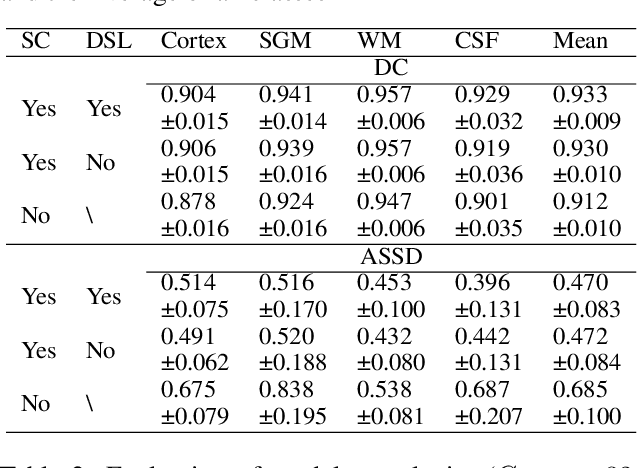
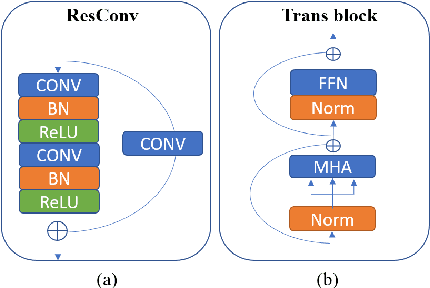
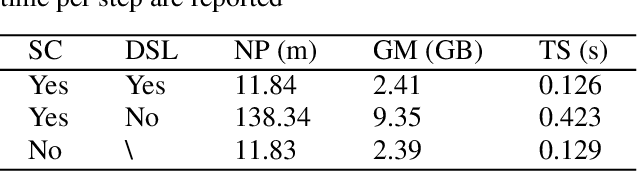
Convolutional neural networks (CNNs) achieved the state-of-the-art performance in medical image segmentation due to their ability to extract highly complex feature representations. However, it is argued in recent studies that traditional CNNs lack the intelligence to capture long-term dependencies of different image regions. Following the success of applying Transformer models on natural language processing tasks, the medical image segmentation field has also witnessed growing interest in utilizing Transformers, due to their ability to capture long-range contextual information. However, unlike CNNs, Transformers lack the ability to learn local feature representations. Thus, to fully utilize the advantages of both CNNs and Transformers, we propose a hybrid encoder-decoder segmentation model (ConvTransSeg). It consists of a multi-layer CNN as the encoder for feature learning and the corresponding multi-level Transformer as the decoder for segmentation prediction. The encoder and decoder are interconnected in a multi-resolution manner. We compared our method with many other state-of-the-art hybrid CNN and Transformer segmentation models on binary and multiple class image segmentation tasks using several public medical image datasets, including skin lesion, polyp, cell and brain tissue. The experimental results show that our method achieves overall the best performance in terms of Dice coefficient and average symmetric surface distance measures with low model complexity and memory consumption. In contrast to most Transformer-based methods that we compared, our method does not require the use of pre-trained models to achieve similar or better performance. The code is freely available for research purposes on Github: (the link will be added upon acceptance).
Addressing Multiple Salient Object Detection via Dual-Space Long-Range Dependencies
Nov 04, 2021
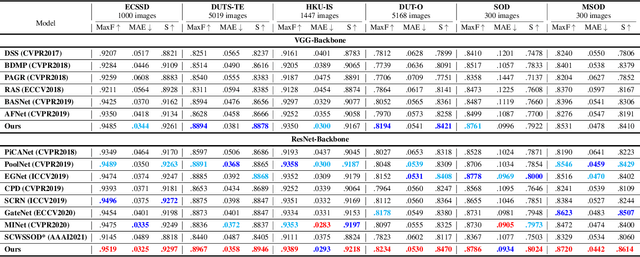
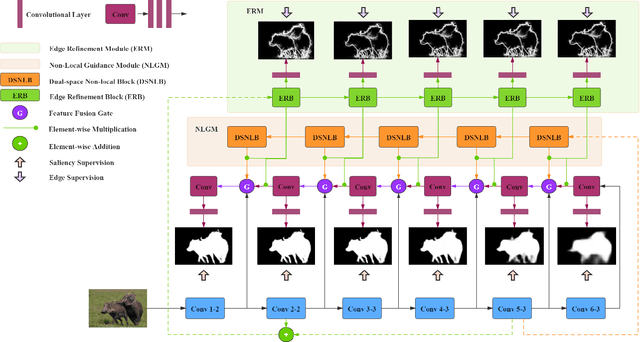
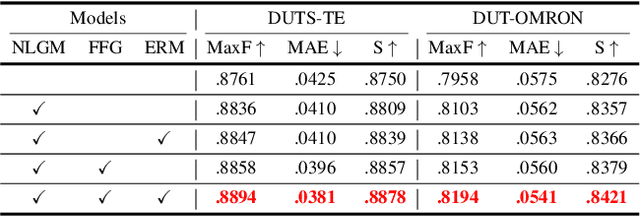
Salient object detection plays an important role in many downstream tasks. However, complex real-world scenes with varying scales and numbers of salient objects still pose a challenge. In this paper, we directly address the problem of detecting multiple salient objects across complex scenes. We propose a network architecture incorporating non-local feature information in both the spatial and channel spaces, capturing the long-range dependencies between separate objects. Traditional bottom-up and non-local features are combined with edge features within a feature fusion gate that progressively refines the salient object prediction in the decoder. We show that our approach accurately locates multiple salient regions even in complex scenarios. To demonstrate the efficacy of our approach to the multiple salient objects problem, we curate a new dataset containing only multiple salient objects. Our experiments demonstrate the proposed method presents state-of-the-art results on five widely used datasets without any pre-processing and post-processing. We obtain a further performance improvement against competing techniques on our multi-objects dataset. The dataset and source code are avaliable at: https://github.com/EricDengbowen/DSLRDNet.
Hierarchical Piecewise-Constant Super-regions
May 19, 2016



Recent applications in computer vision have come to heavily rely on superpixel over-segmentation as a pre-processing step for higher level vision tasks, such as object recognition, image labelling or image segmentation. Here we present a new superpixel algorithm called Hierarchical Piecewise-Constant Super-regions (HPCS), which not only obtains superpixels comparable to the state-of-the-art, but can also be applied hierarchically to form what we call n-th order super-regions. In essence, a Markov Random Field (MRF)-based anisotropic denoising formulation over the quantized feature space is adopted to form piecewise-constant image regions, which are then combined with a graph-based split & merge post-processing step to form superpixels. The graph and quantized feature based formulation of the problem allows us to generalize it hierarchically to preserve boundary adherence with fewer superpixels. Experimental results show that, despite the simplicity of our framework, it is able to provide high quality superpixels, and to hierarchically apply them to form layers of over-segmentation, each with a decreasing number of superpixels, while maintaining the same desired properties (such as adherence to strong image edges). The algorithm is also memory efficient and has a low computational cost.