 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Framework to Quantify Cultural Intelligence of AI
Mar 01, 2026As generative AI technologies are increasingly being launched across the globe, assessing their competence to operate in different cultural contexts is exigently becoming a priority. While recent years have seen numerous and much-needed efforts on cultural benchmarking, these efforts have largely focused on specific aspects of culture and evaluation. While these efforts contribute to our understanding of cultural competence, a unified and systematic evaluation approach is needed for us as a field to comprehensively assess diverse cultural dimensions at scale. Drawing on measurement theory, we present a principled framework to aggregate multifaceted indicators of cultural capabilities into a unified assessment of cultural intelligence. We start by developing a working definition of culture that includes identifying core domains of culture. We then introduce a broad-purpose, systematic, and extensible framework for assessing cultural intelligence of AI systems. Drawing on theoretical framing from psychometric measurement validity theory, we decouple the background concept (i.e., cultural intelligence) from its operationalization via measurement. We conceptualize cultural intelligence as a suite of core capabilities spanning diverse domains, which we then operationalize through a set of indicators designed for reliable measurement. Finally, we identify the considerations, challenges, and research pathways to meaningfully measure these indicators, specifically focusing on data collection, probing strategies, and evaluation metrics.
SAFARI: A Community-Engaged Approach and Dataset of Stereotype Resources in the Sub-Saharan African Context
Feb 25, 2026Stereotype repositories are critical to assess generative AI model safety, but currently lack adequate global coverage. It is imperative to prioritize targeted expansion, strategically addressing existing deficits, over merely increasing data volume. This work introduces a multilingual stereotype resource covering four sub-Saharan African countries that are severely underrepresented in NLP resources: Ghana, Kenya, Nigeria, and South Africa. By utilizing socioculturally-situated, community-engaged methods, including telephonic surveys moderated in native languages, we establish a reproducible methodology that is sensitive to the region's complex linguistic diversity and traditional orality. By deliberately balancing the sample across diverse ethnic and demographic backgrounds, we ensure broad coverage, resulting in a dataset of 3,534 stereotypes in English and 3,206 stereotypes across 15 native languages.
Data Cards: Purposeful and Transparent Dataset Documentation for Responsible AI
Apr 03, 2022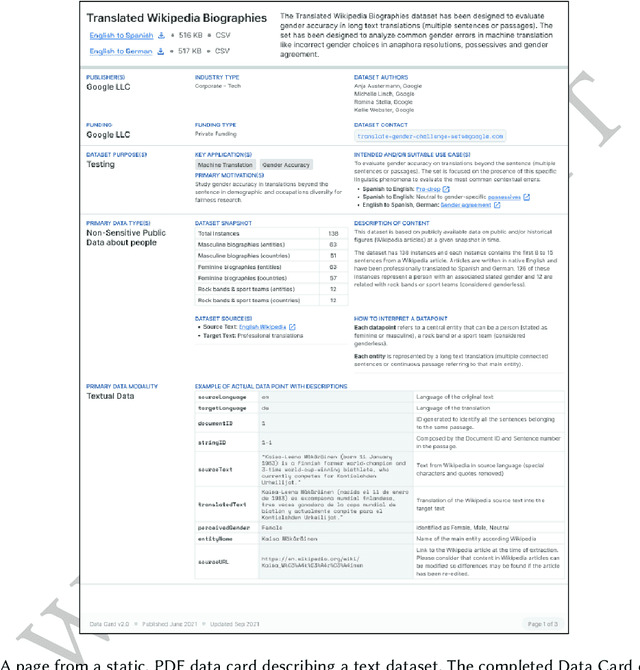
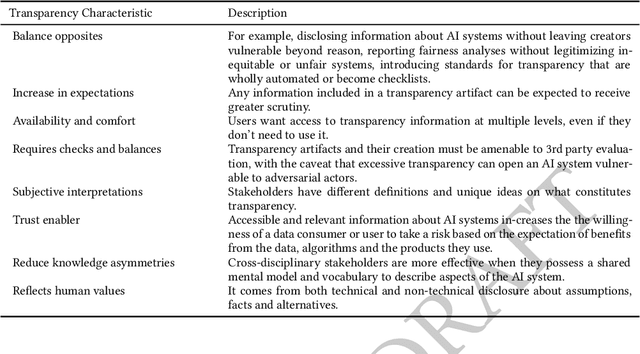
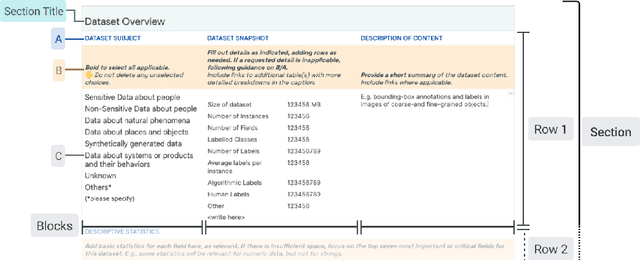

As research and industry moves towards large-scale models capable of numerous downstream tasks, the complexity of understanding multi-modal datasets that give nuance to models rapidly increases. A clear and thorough understanding of a dataset's origins, development, intent, ethical considerations and evolution becomes a necessary step for the responsible and informed deployment of models, especially those in people-facing contexts and high-risk domains. However, the burden of this understanding often falls on the intelligibility, conciseness, and comprehensiveness of the documentation. It requires consistency and comparability across the documentation of all datasets involved, and as such documentation must be treated as a user-centric product in and of itself. In this paper, we propose Data Cards for fostering transparent, purposeful and human-centered documentation of datasets within the practical contexts of industry and research. Data Cards are structured summaries of essential facts about various aspects of ML datasets needed by stakeholders across a dataset's lifecycle for responsible AI development. These summaries provide explanations of processes and rationales that shape the data and consequently the models, such as upstream sources, data collection and annotation methods; training and evaluation methods, intended use; or decisions affecting model performance. We also present frameworks that ground Data Cards in real-world utility and human-centricity. Using two case studies, we report on desirable characteristics that support adoption across domains, organizational structures, and audience groups. Finally, we present lessons learned from deploying over 20 Data Cards.