 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Study of Decoder-Only LLMs for Text-to-Image Generation
Jun 09, 2025Both text-to-image generation and large language models (LLMs) have made significant advancements. However, many text-to-image models still employ the somewhat outdated T5 and CLIP as their text encoders. In this work, we investigate the effectiveness of using modern decoder-only LLMs as text encoders for text-to-image diffusion models. We build a standardized training and evaluation pipeline that allows us to isolate and evaluate the effect of different text embeddings. We train a total of 27 text-to-image models with 12 different text encoders to analyze the critical aspects of LLMs that could impact text-to-image generation, including the approaches to extract embeddings, different LLMs variants, and model sizes. Our experiments reveal that the de facto way of using last-layer embeddings as conditioning leads to inferior performance. Instead, we explore embeddings from various layers and find that using layer-normalized averaging across all layers significantly improves alignment with complex prompts. Most LLMs with this conditioning outperform the baseline T5 model, showing enhanced performance in advanced visio-linguistic reasoning skills.
Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning
Mar 18, 2025Physical AI systems need to perceive, understand, and perform complex actions in the physical world. In this paper, we present the Cosmos-Reason1 models that can understand the physical world and generate appropriate embodied decisions (e.g., next step action) in natural language through long chain-of-thought reasoning processes. We begin by defining key capabilities for Physical AI reasoning, with a focus on physical common sense and embodied reasoning. To represent physical common sense, we use a hierarchical ontology that captures fundamental knowledge about space, time, and physics. For embodied reasoning, we rely on a two-dimensional ontology that generalizes across different physical embodiments. Building on these capabilities, we develop two multimodal large language models, Cosmos-Reason1-8B and Cosmos-Reason1-56B. We curate data and train our models in four stages: vision pre-training, general supervised fine-tuning (SFT), Physical AI SFT, and Physical AI reinforcement learning (RL) as the post-training. To evaluate our models, we build comprehensive benchmarks for physical common sense and embodied reasoning according to our ontologies. Evaluation results show that Physical AI SFT and reinforcement learning bring significant improvements. To facilitate the development of Physical AI, we will make our code and pre-trained models available under the NVIDIA Open Model License at https://github.com/nvidia-cosmos/cosmos-reason1.
ConvoKit: A Toolkit for the Analysis of Conversations
May 08, 2020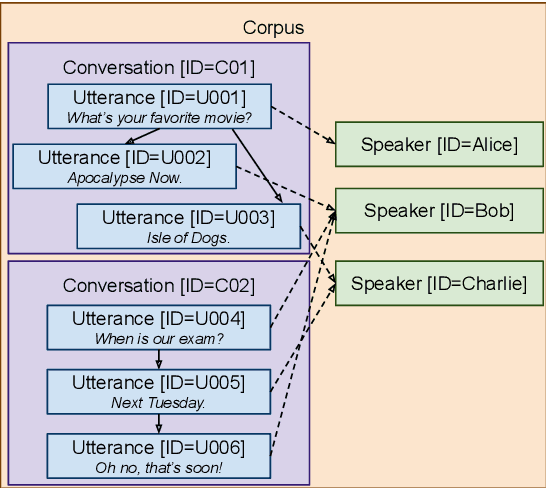
This paper describes the design and functionality of ConvoKit, an open-source toolkit for analyzing conversations and the social interactions embedded within. ConvoKit provides an unified framework for representing and manipulating conversational data, as well as a large and diverse collection of conversational datasets. By providing an intuitive interface for exploring and interacting with conversational data, this toolkit lowers the technical barriers for the broad adoption of computational methods for conversational analysis.