 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGo for a Walk and Arrive at the Answer: Reasoning Over Paths in Knowledge Bases using Reinforcement Learning
Nov 15, 2017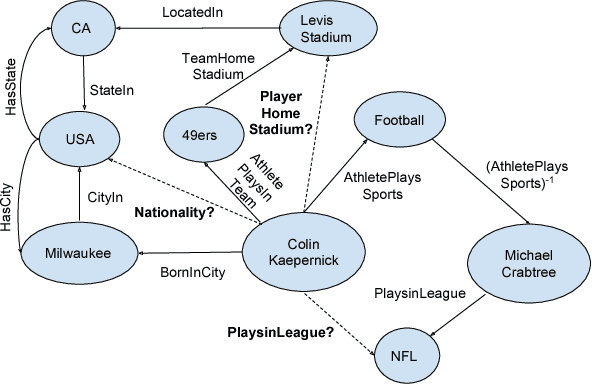
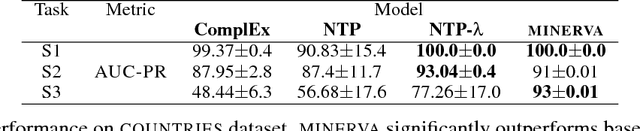
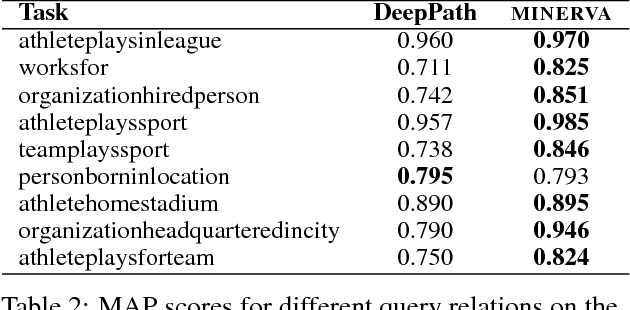
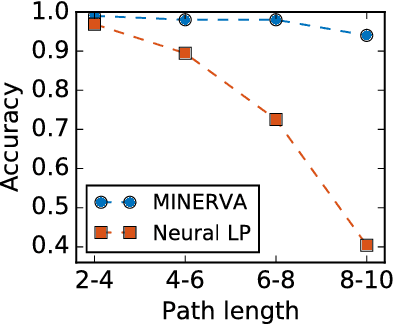
Knowledge bases (KB), both automatically and manually constructed, are often incomplete --- many valid facts can be inferred from the KB by synthesizing existing information. A popular approach to KB completion is to infer new relations by combinatory reasoning over the information found along other paths connecting a pair of entities. Given the enormous size of KBs and the exponential number of paths, previous path-based models have considered only the problem of predicting a missing relation given two entities or evaluating the truth of a proposed triple. Additionally, these methods have traditionally used random paths between fixed entity pairs or more recently learned to pick paths between them. We propose a new algorithm MINERVA, which addresses the much more difficult and practical task of answering questions where the relation is known, but only one entity. Since random walks are impractical in a setting with combinatorially many destinations from a start node, we present a neural reinforcement learning approach which learns how to navigate the graph conditioned on the input query to find predictive paths. Empirically, this approach obtains state-of-the-art results on several datasets, significantly outperforming prior methods.
Finer Grained Entity Typing with TypeNet
Nov 15, 2017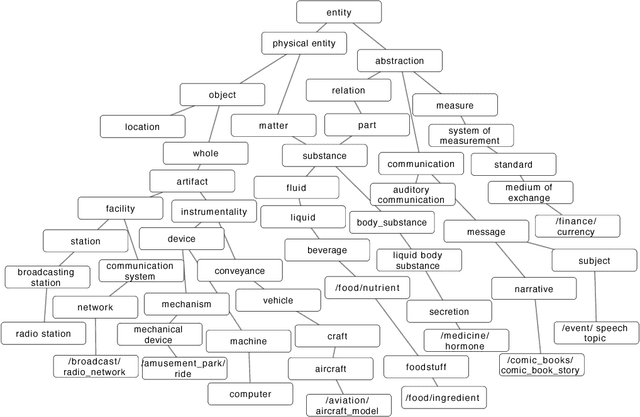
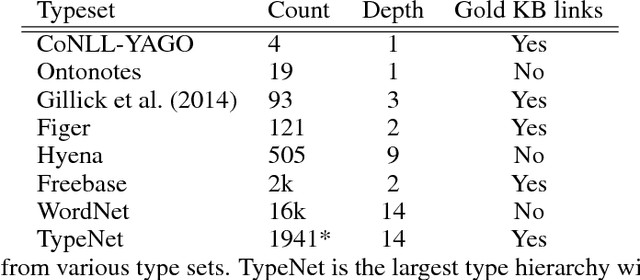
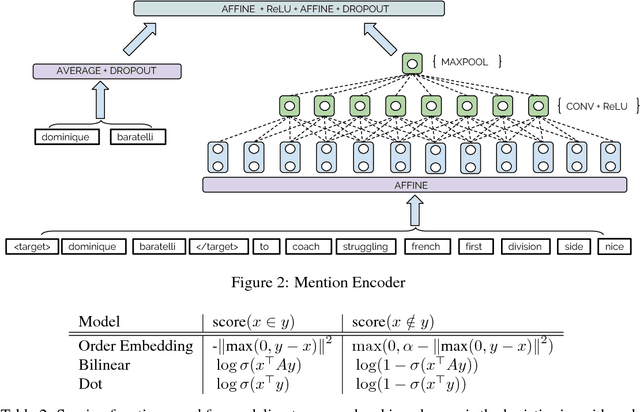
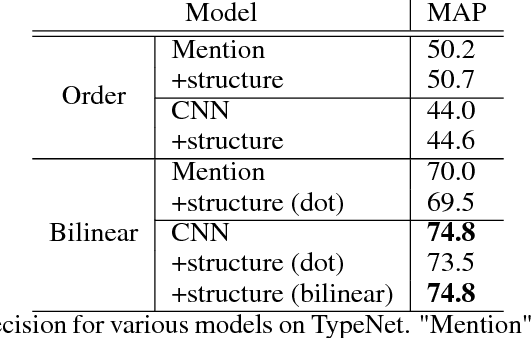
We consider the challenging problem of entity typing over an extremely fine grained set of types, wherein a single mention or entity can have many simultaneous and often hierarchically-structured types. Despite the importance of the problem, there is a relative lack of resources in the form of fine-grained, deep type hierarchies aligned to existing knowledge bases. In response, we introduce TypeNet, a dataset of entity types consisting of over 1941 types organized in a hierarchy, obtained by manually annotating a mapping from 1081 Freebase types to WordNet. We also experiment with several models comparable to state-of-the-art systems and explore techniques to incorporate a structure loss on the hierarchy with the standard mention typing loss, as a first step towards future research on this dataset.
Attending to All Mention Pairs for Full Abstract Biological Relation Extraction
Nov 15, 2017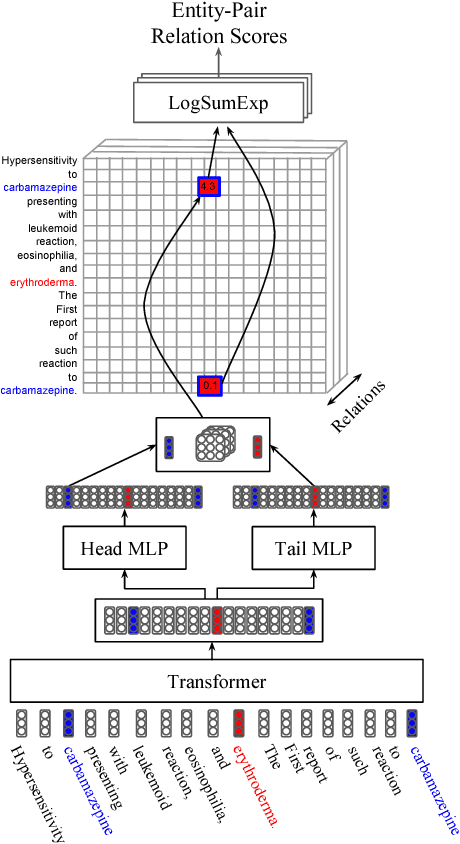
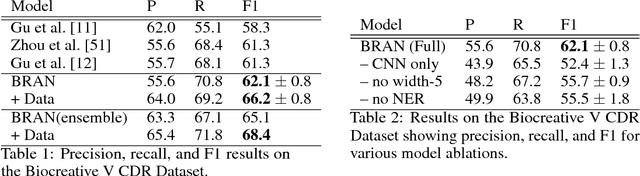
Most work in relation extraction forms a prediction by looking at a short span of text within a single sentence containing a single entity pair mention. However, many relation types, particularly in biomedical text, are expressed across sentences or require a large context to disambiguate. We propose a model to consider all mention and entity pairs simultaneously in order to make a prediction. We encode full paper abstracts using an efficient self-attention encoder and form pairwise predictions between all mentions with a bi-affine operation. An entity-pair wise pooling aggregates mention pair scores to make a final prediction while alleviating training noise by performing within document multi-instance learning. We improve our model's performance by jointly training the model to predict named entities and adding an additional corpus of weakly labeled data. We demonstrate our model's effectiveness by achieving the state of the art on the Biocreative V Chemical Disease Relation dataset for models without KB resources, outperforming ensembles of models which use hand-crafted features and additional linguistic resources.
Low-Rank Hidden State Embeddings for Viterbi Sequence Labeling
Aug 02, 2017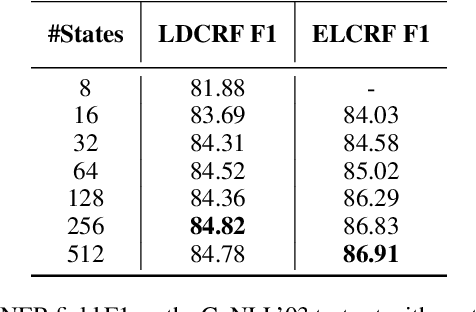

In textual information extraction and other sequence labeling tasks it is now common to use recurrent neural networks (such as LSTM) to form rich embedded representations of long-term input co-occurrence patterns. Representation of output co-occurrence patterns is typically limited to a hand-designed graphical model, such as a linear-chain CRF representing short-term Markov dependencies among successive labels. This paper presents a method that learns embedded representations of latent output structure in sequence data. Our model takes the form of a finite-state machine with a large number of latent states per label (a latent variable CRF), where the state-transition matrix is factorized---effectively forming an embedded representation of state-transitions capable of enforcing long-term label dependencies, while supporting exact Viterbi inference over output labels. We demonstrate accuracy improvements and interpretable latent structure in a synthetic but complex task based on CoNLL named entity recognition.
Improved Representation Learning for Predicting Commonsense Ontologies
Aug 01, 2017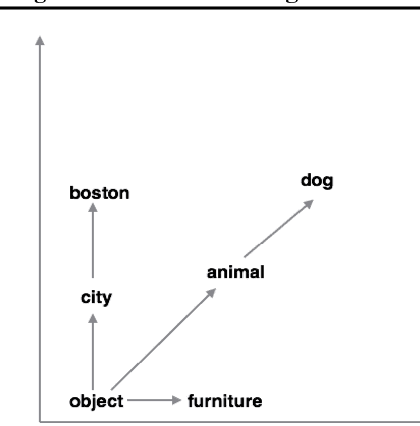

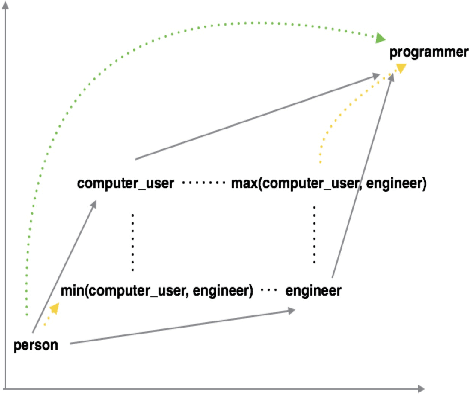
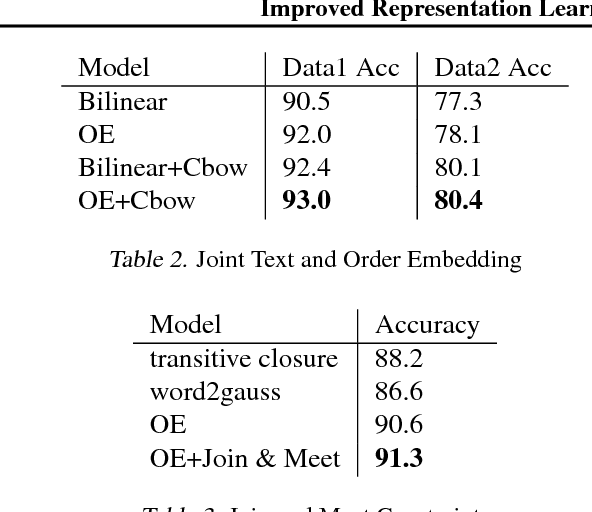
Recent work in learning ontologies (hierarchical and partially-ordered structures) has leveraged the intrinsic geometry of spaces of learned representations to make predictions that automatically obey complex structural constraints. We explore two extensions of one such model, the order-embedding model for hierarchical relation learning, with an aim towards improved performance on text data for commonsense knowledge representation. Our first model jointly learns ordering relations and non-hierarchical knowledge in the form of raw text. Our second extension exploits the partial order structure of the training data to find long-distance triplet constraints among embeddings which are poorly enforced by the pairwise training procedure. We find that both incorporating free text and augmented training constraints improve over the original order-embedding model and other strong baselines.
Fast and Accurate Entity Recognition with Iterated Dilated Convolutions
Jul 22, 2017
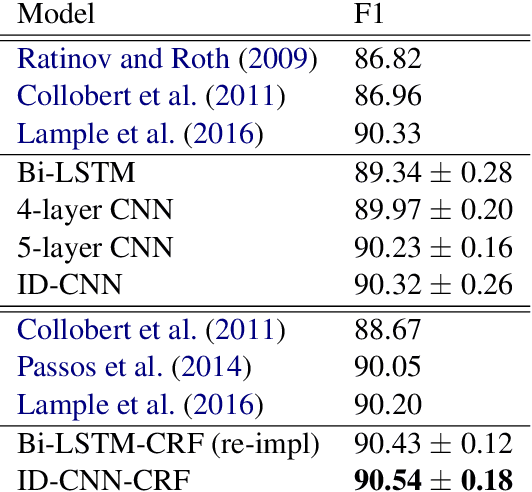
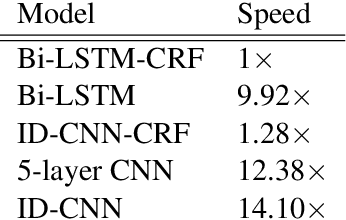
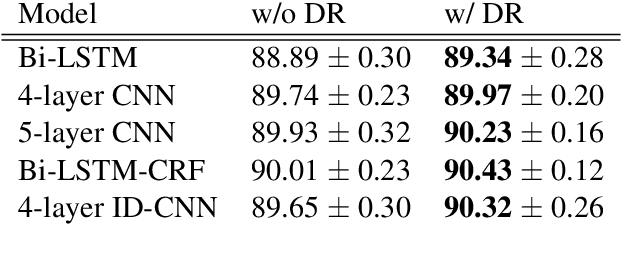
Today when many practitioners run basic NLP on the entire web and large-volume traffic, faster methods are paramount to saving time and energy costs. Recent advances in GPU hardware have led to the emergence of bi-directional LSTMs as a standard method for obtaining per-token vector representations serving as input to labeling tasks such as NER (often followed by prediction in a linear-chain CRF). Though expressive and accurate, these models fail to fully exploit GPU parallelism, limiting their computational efficiency. This paper proposes a faster alternative to Bi-LSTMs for NER: Iterated Dilated Convolutional Neural Networks (ID-CNNs), which have better capacity than traditional CNNs for large context and structured prediction. Unlike LSTMs whose sequential processing on sentences of length N requires O(N) time even in the face of parallelism, ID-CNNs permit fixed-depth convolutions to run in parallel across entire documents. We describe a distinct combination of network structure, parameter sharing and training procedures that enable dramatic 14-20x test-time speedups while retaining accuracy comparable to the Bi-LSTM-CRF. Moreover, ID-CNNs trained to aggregate context from the entire document are even more accurate while maintaining 8x faster test time speeds.
Dependency Parsing with Dilated Iterated Graph CNNs
Jul 21, 2017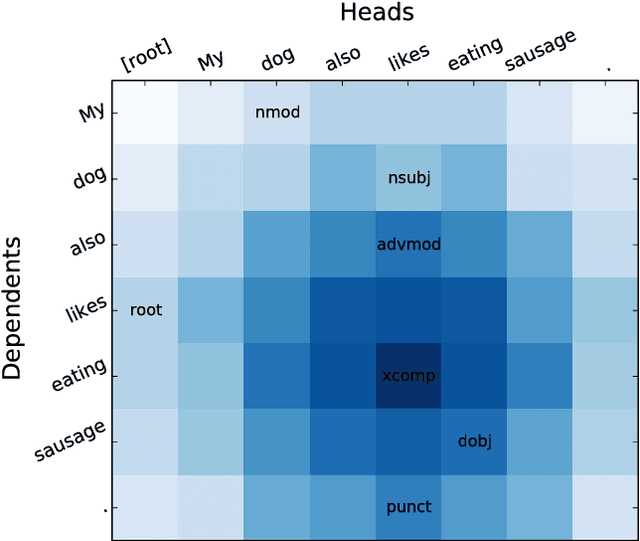
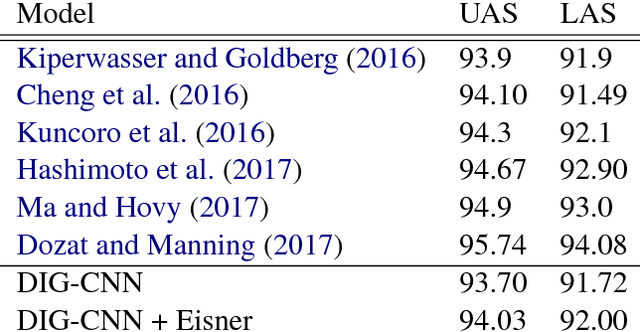
Dependency parses are an effective way to inject linguistic knowledge into many downstream tasks, and many practitioners wish to efficiently parse sentences at scale. Recent advances in GPU hardware have enabled neural networks to achieve significant gains over the previous best models, these models still fail to leverage GPUs' capability for massive parallelism due to their requirement of sequential processing of the sentence. In response, we propose Dilated Iterated Graph Convolutional Neural Networks (DIG-CNNs) for graph-based dependency parsing, a graph convolutional architecture that allows for efficient end-to-end GPU parsing. In experiments on the English Penn TreeBank benchmark, we show that DIG-CNNs perform on par with some of the best neural network parsers.
End-to-End Learning for Structured Prediction Energy Networks
Jul 15, 2017
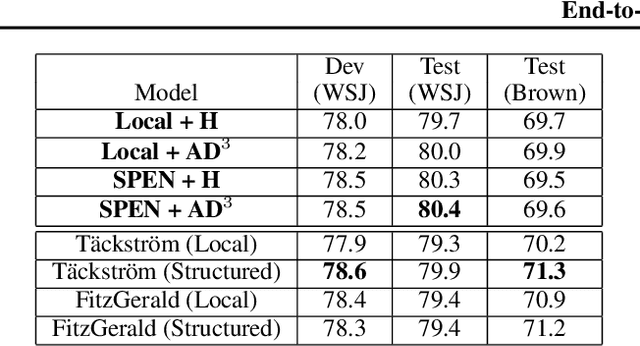
Structured Prediction Energy Networks (SPENs) are a simple, yet expressive family of structured prediction models (Belanger and McCallum, 2016). An energy function over candidate structured outputs is given by a deep network, and predictions are formed by gradient-based optimization. This paper presents end-to-end learning for SPENs, where the energy function is discriminatively trained by back-propagating through gradient-based prediction. In our experience, the approach is substantially more accurate than the structured SVM method of Belanger and McCallum (2016), as it allows us to use more sophisticated non-convex energies. We provide a collection of techniques for improving the speed, accuracy, and memory requirements of end-to-end SPENs, and demonstrate the power of our method on 7-Scenes image denoising and CoNLL-2005 semantic role labeling tasks. In both, inexact minimization of non-convex SPEN energies is superior to baseline methods that use simplistic energy functions that can be minimized exactly.
SemEval 2017 Task 10: ScienceIE - Extracting Keyphrases and Relations from Scientific Publications
May 02, 2017

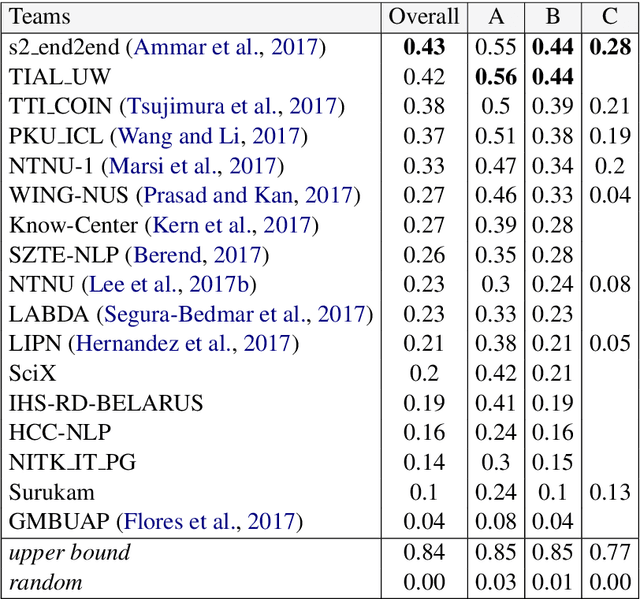
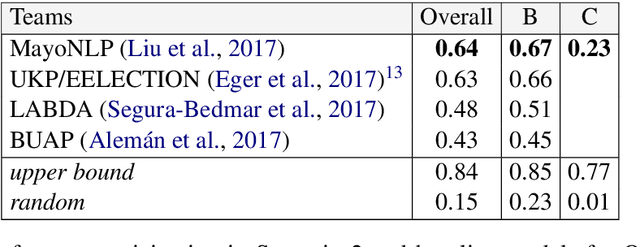
We describe the SemEval task of extracting keyphrases and relations between them from scientific documents, which is crucial for understanding which publications describe which processes, tasks and materials. Although this was a new task, we had a total of 26 submissions across 3 evaluation scenarios. We expect the task and the findings reported in this paper to be relevant for researchers working on understanding scientific content, as well as the broader knowledge base population and information extraction communities.
Chains of Reasoning over Entities, Relations, and Text using Recurrent Neural Networks
May 01, 2017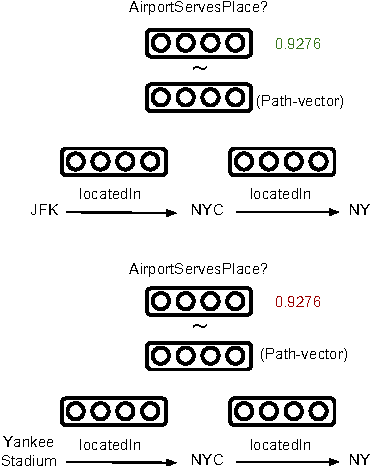
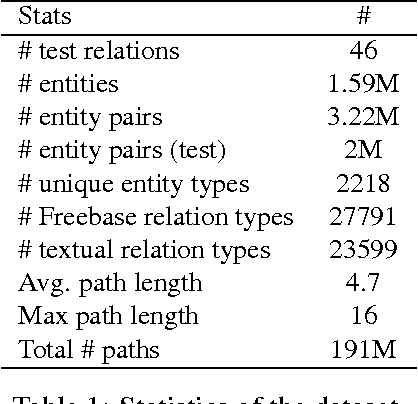
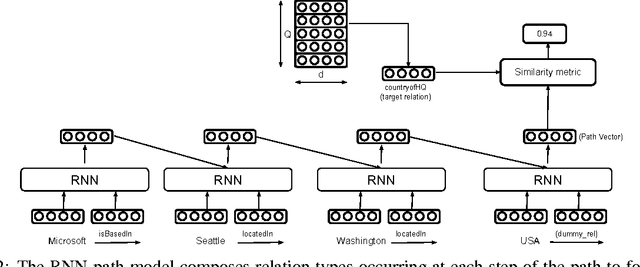
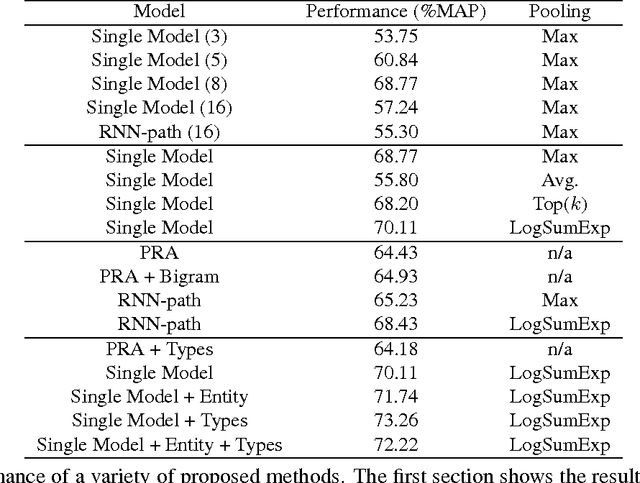
Our goal is to combine the rich multistep inference of symbolic logical reasoning with the generalization capabilities of neural networks. We are particularly interested in complex reasoning about entities and relations in text and large-scale knowledge bases (KBs). Neelakantan et al. (2015) use RNNs to compose the distributed semantics of multi-hop paths in KBs; however for multiple reasons, the approach lacks accuracy and practicality. This paper proposes three significant modeling advances: (1) we learn to jointly reason about relations, entities, and entity-types; (2) we use neural attention modeling to incorporate multiple paths; (3) we learn to share strength in a single RNN that represents logical composition across all relations. On a largescale Freebase+ClueWeb prediction task, we achieve 25% error reduction, and a 53% error reduction on sparse relations due to shared strength. On chains of reasoning in WordNet we reduce error in mean quantile by 84% versus previous state-of-the-art. The code and data are available at https://rajarshd.github.io/ChainsofReasoning