 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Set Functions
May 31, 2018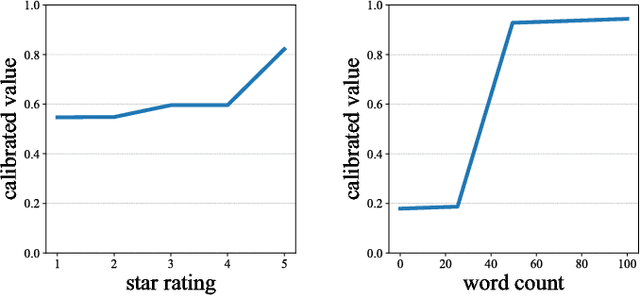

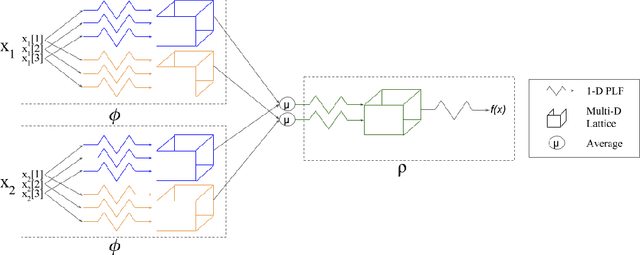
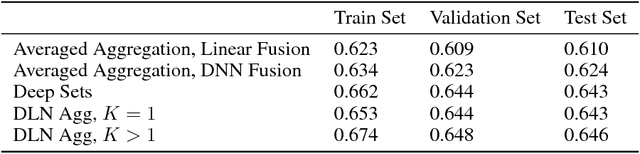
We propose learning flexible but interpretable functions that aggregate a variable-length set of permutation-invariant feature vectors to predict a label. We use a deep lattice network model so we can architect the model structure to enhance interpretability, and add monotonicity constraints between inputs-and-outputs. We then use the proposed set function to automate the engineering of dense, interpretable features from sparse categorical features, which we call semantic feature engine. Experiments on real-world data show the achieved accuracy is similar to deep sets or deep neural networks, and is easier to debug and understand.
Satisfying Real-world Goals with Dataset Constraints
May 03, 2017

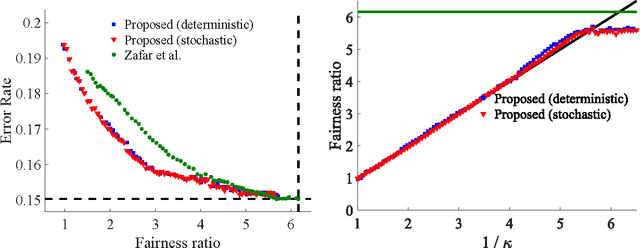
The goal of minimizing misclassification error on a training set is often just one of several real-world goals that might be defined on different datasets. For example, one may require a classifier to also make positive predictions at some specified rate for some subpopulation (fairness), or to achieve a specified empirical recall. Other real-world goals include reducing churn with respect to a previously deployed model, or stabilizing online training. In this paper we propose handling multiple goals on multiple datasets by training with dataset constraints, using the ramp penalty to accurately quantify costs, and present an efficient algorithm to approximately optimize the resulting non-convex constrained optimization problem. Experiments on both benchmark and real-world industry datasets demonstrate the effectiveness of our approach.
A Light Touch for Heavily Constrained SGD
Oct 24, 2016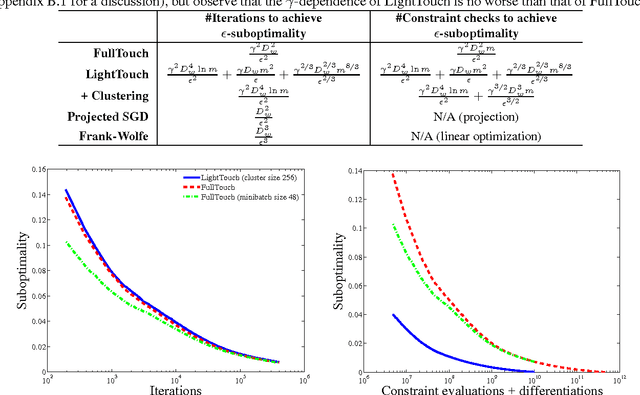
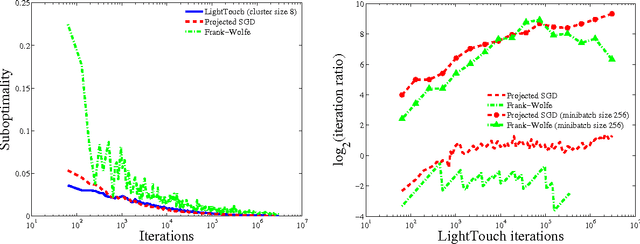

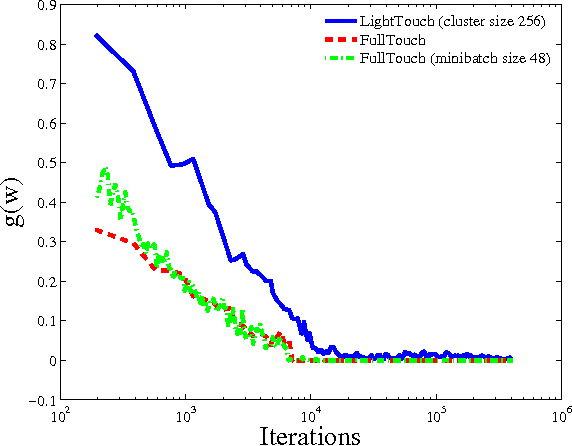
Minimizing empirical risk subject to a set of constraints can be a useful strategy for learning restricted classes of functions, such as monotonic functions, submodular functions, classifiers that guarantee a certain class label for some subset of examples, etc. However, these restrictions may result in a very large number of constraints. Projected stochastic gradient descent (SGD) is often the default choice for large-scale optimization in machine learning, but requires a projection after each update. For heavily-constrained objectives, we propose an efficient extension of SGD that stays close to the feasible region while only applying constraints probabilistically at each iteration. Theoretical analysis shows a compelling trade-off between per-iteration work and the number of iterations needed on problems with a large number of constraints.
Monotonic Calibrated Interpolated Look-Up Tables
Jan 20, 2016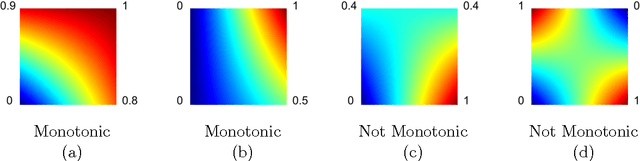
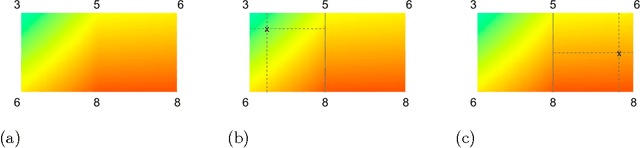
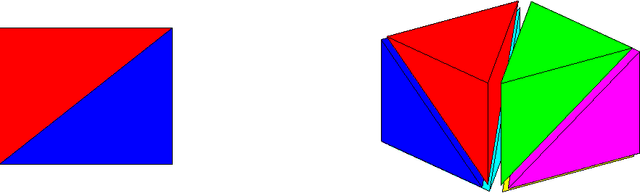
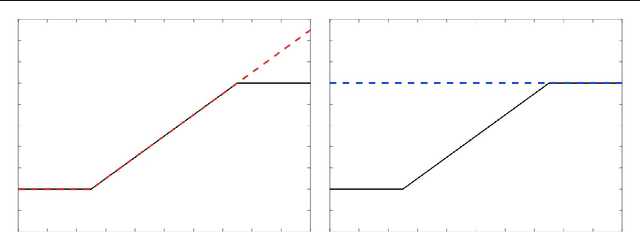
Real-world machine learning applications may require functions that are fast-to-evaluate and interpretable. In particular, guaranteed monotonicity of the learned function can be critical to user trust. We propose meeting these goals for low-dimensional machine learning problems by learning flexible, monotonic functions using calibrated interpolated look-up tables. We extend the structural risk minimization framework of lattice regression to train monotonic look-up tables by solving a convex problem with appropriate linear inequality constraints. In addition, we propose jointly learning interpretable calibrations of each feature to normalize continuous features and handle categorical or missing data, at the cost of making the objective non-convex. We address large-scale learning through parallelization, mini-batching, and propose random sampling of additive regularizer terms. Case studies with real-world problems with five to sixteen features and thousands to millions of training samples demonstrate the proposed monotonic functions can achieve state-of-the-art accuracy on practical problems while providing greater transparency to users.
Stochastic Optimization for Machine Learning
Aug 15, 2013
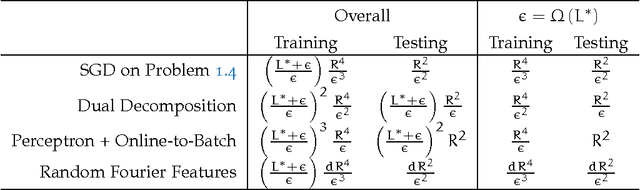
It has been found that stochastic algorithms often find good solutions much more rapidly than inherently-batch approaches. Indeed, a very useful rule of thumb is that often, when solving a machine learning problem, an iterative technique which relies on performing a very large number of relatively-inexpensive updates will often outperform one which performs a smaller number of much "smarter" but computationally-expensive updates. In this thesis, we will consider the application of stochastic algorithms to two of the most important machine learning problems. Part i is concerned with the supervised problem of binary classification using kernelized linear classifiers, for which the data have labels belonging to exactly two classes (e.g. "has cancer" or "doesn't have cancer"), and the learning problem is to find a linear classifier which is best at predicting the label. In Part ii, we will consider the unsupervised problem of Principal Component Analysis, for which the learning task is to find the directions which contain most of the variance of the data distribution. Our goal is to present stochastic algorithms for both problems which are, above all, practical--they work well on real-world data, in some cases better than all known competing algorithms. A secondary, but still very important, goal is to derive theoretical bounds on the performance of these algorithms which are at least competitive with, and often better than, those known for other approaches.
Stochastic Optimization of PCA with Capped MSG
Jul 05, 2013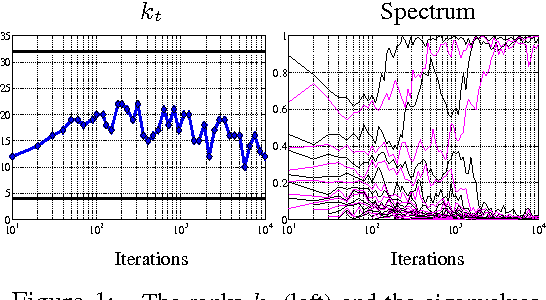
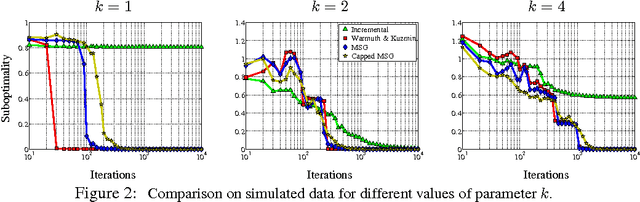
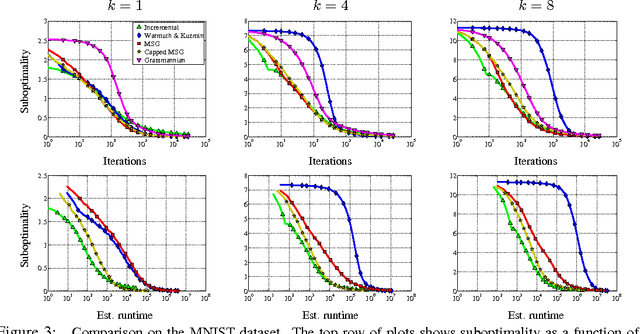
We study PCA as a stochastic optimization problem and propose a novel stochastic approximation algorithm which we refer to as "Matrix Stochastic Gradient" (MSG), as well as a practical variant, Capped MSG. We study the method both theoretically and empirically.
The Kernelized Stochastic Batch Perceptron
Jun 21, 2012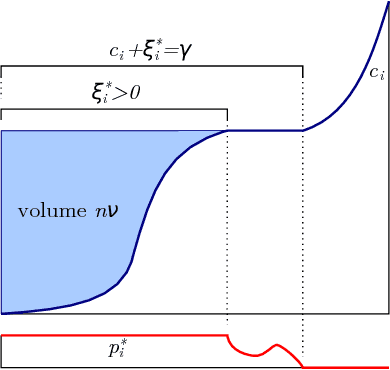

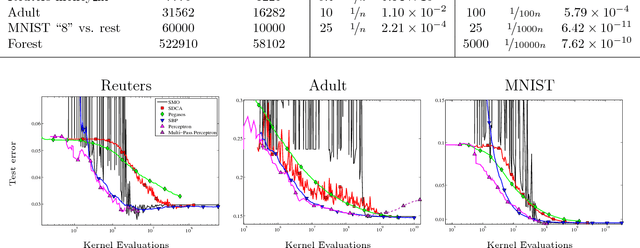
We present a novel approach for training kernel Support Vector Machines, establish learning runtime guarantees for our method that are better then those of any other known kernelized SVM optimization approach, and show that our method works well in practice compared to existing alternatives.
Explicit Approximations of the Gaussian Kernel
Sep 21, 2011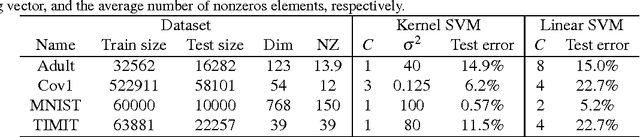
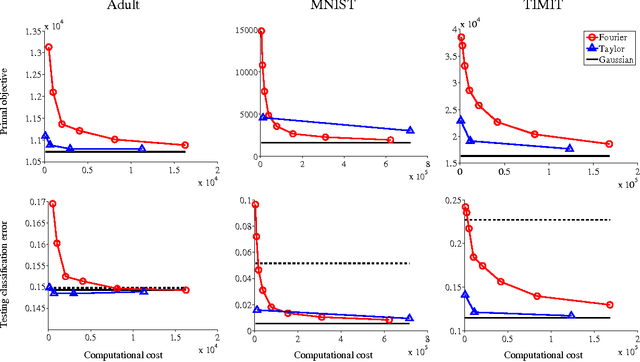
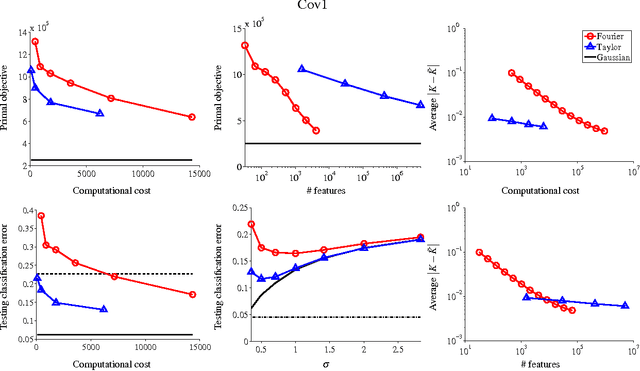

We investigate training and using Gaussian kernel SVMs by approximating the kernel with an explicit finite- dimensional polynomial feature representation based on the Taylor expansion of the exponential. Although not as efficient as the recently-proposed random Fourier features [Rahimi and Recht, 2007] in terms of the number of features, we show how this polynomial representation can provide a better approximation in terms of the computational cost involved. This makes our "Taylor features" especially attractive for use on very large data sets, in conjunction with online or stochastic training.
Better Mini-Batch Algorithms via Accelerated Gradient Methods
Jun 22, 2011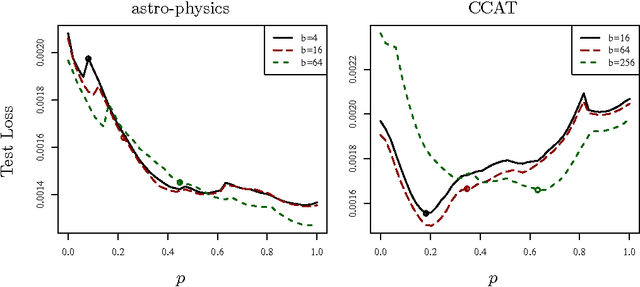
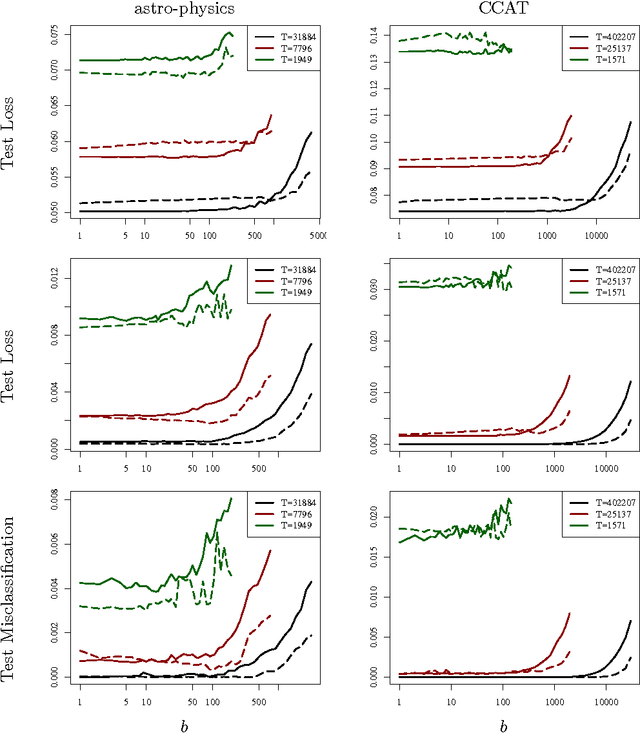
Mini-batch algorithms have been proposed as a way to speed-up stochastic convex optimization problems. We study how such algorithms can be improved using accelerated gradient methods. We provide a novel analysis, which shows how standard gradient methods may sometimes be insufficient to obtain a significant speed-up and propose a novel accelerated gradient algorithm, which deals with this deficiency, enjoys a uniformly superior guarantee and works well in practice.