 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Calibration in Deep Metric Learning With Cross-Example Softmax
Nov 17, 2020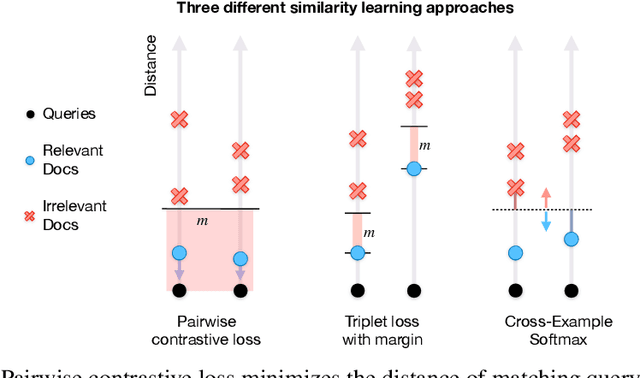
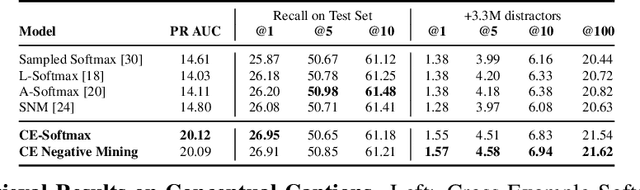
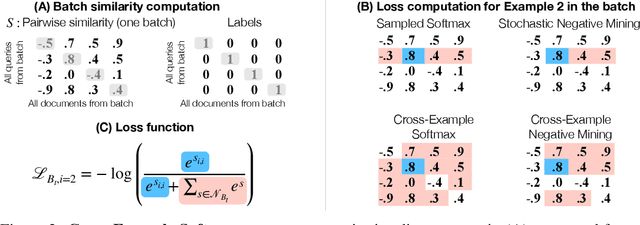
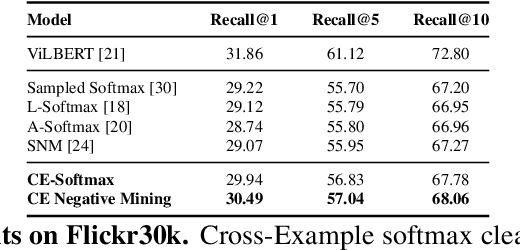
Modern image retrieval systems increasingly rely on the use of deep neural networks to learn embedding spaces in which distance encodes the relevance between a given query and image. In this setting, existing approaches tend to emphasize one of two properties. Triplet-based methods capture top-$k$ relevancy, where all top-$k$ scoring documents are assumed to be relevant to a given query Pairwise contrastive models capture threshold relevancy, where all documents scoring higher than some threshold are assumed to be relevant. In this paper, we propose Cross-Example Softmax which combines the properties of top-$k$ and threshold relevancy. In each iteration, the proposed loss encourages all queries to be closer to their matching images than all queries are to all non-matching images. This leads to a globally more calibrated similarity metric and makes distance more interpretable as an absolute measure of relevance. We further introduce Cross-Example Negative Mining, in which each pair is compared to the hardest negative comparisons across the entire batch. Empirically, we show in a series of experiments on Conceptual Captions and Flickr30k, that the proposed method effectively improves global calibration and also retrieval performance.
Coping with Label Shift via Distributionally Robust Optimisation
Oct 23, 2020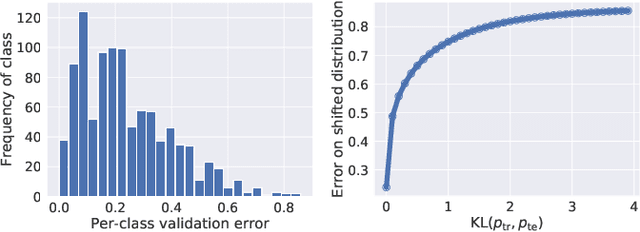

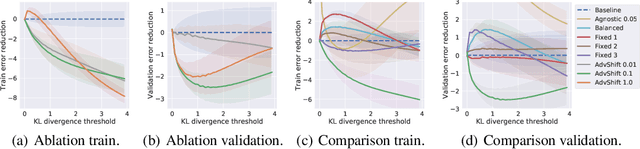
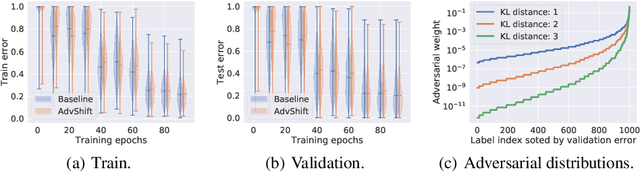
The label shift problem refers to the supervised learning setting where the train and test label distributions do not match. Existing work addressing label shift usually assumes access to an \emph{unlabelled} test sample. This sample may be used to estimate the test label distribution, and to then train a suitably re-weighted classifier. While approaches using this idea have proven effective, their scope is limited as it is not always feasible to access the target domain; further, they require repeated retraining if the model is to be deployed in \emph{multiple} test environments. Can one instead learn a \emph{single} classifier that is robust to arbitrary label shifts from a broad family? In this paper, we answer this question by proposing a model that minimises an objective based on distributionally robust optimisation (DRO). We then design and analyse a gradient descent-proximal mirror ascent algorithm tailored for large-scale problems to optimise the proposed objective. %, and establish its convergence. Finally, through experiments on CIFAR-100 and ImageNet, we show that our technique can significantly improve performance over a number of baselines in settings where label shift is present.
Long-tail learning via logit adjustment
Jul 14, 2020
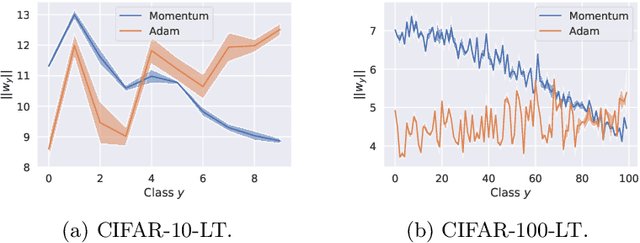
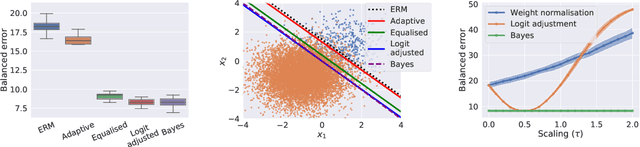
Real-world classification problems typically exhibit an imbalanced or long-tailed label distribution, wherein many labels are associated with only a few samples. This poses a challenge for generalisation on such labels, and also makes na\"ive learning biased towards dominant labels. In this paper, we present two simple modifications of standard softmax cross-entropy training to cope with these challenges. Our techniques revisit the classic idea of logit adjustment based on the label frequencies, either applied post-hoc to a trained model, or enforced in the loss during training. Such adjustment encourages a large relative margin between logits of rare versus dominant labels. These techniques unify and generalise several recent proposals in the literature, while possessing firmer statistical grounding and empirical performance.
Doubly-stochastic mining for heterogeneous retrieval
Apr 23, 2020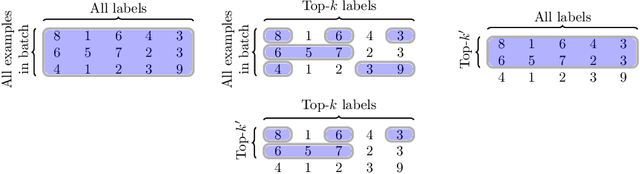


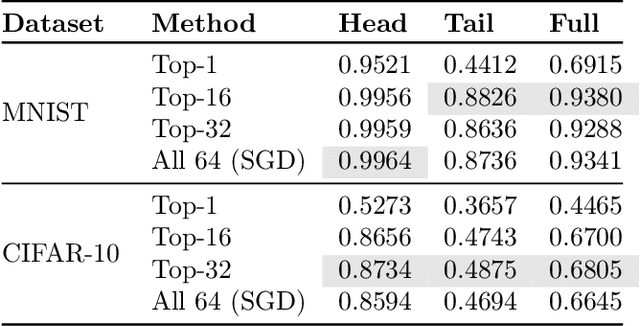
Modern retrieval problems are characterised by training sets with potentially billions of labels, and heterogeneous data distributions across subpopulations (e.g., users of a retrieval system may be from different countries), each of which poses a challenge. The first challenge concerns scalability: with a large number of labels, standard losses are difficult to optimise even on a single example. The second challenge concerns uniformity: one ideally wants good performance on each subpopulation. While several solutions have been proposed to address the first challenge, the second challenge has received relatively less attention. In this paper, we propose doubly-stochastic mining (S2M ), a stochastic optimization technique that addresses both challenges. In each iteration of S2M, we compute a per-example loss based on a subset of hardest labels, and then compute the minibatch loss based on the hardest examples. We show theoretically and empirically that by focusing on the hardest examples, S2M ensures that all data subpopulations are modelled well.
Why ADAM Beats SGD for Attention Models
Dec 06, 2019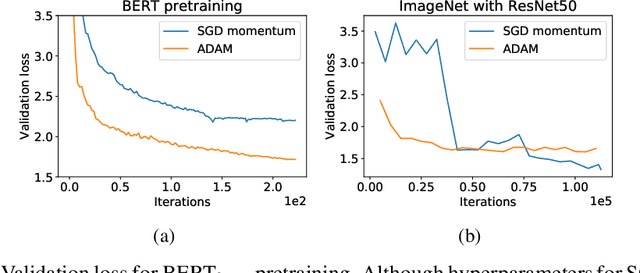

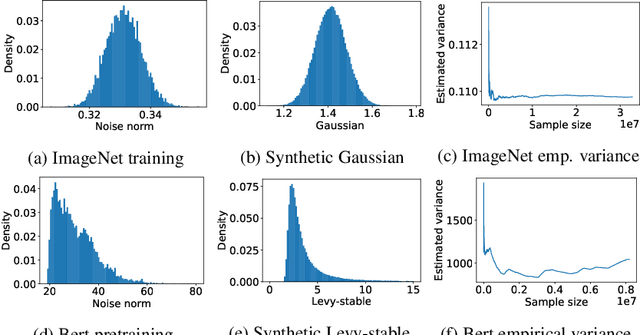

While stochastic gradient descent (SGD) is still the de facto algorithm in deep learning, adaptive methods like Adam have been observed to outperform SGD across important tasks, such as attention models. The settings under which SGD performs poorly in comparison to Adam are not well understood yet. In this paper, we provide empirical and theoretical evidence that a heavy-tailed distribution of the noise in stochastic gradients is a root cause of SGD's poor performance. Based on this observation, we study clipped variants of SGD that circumvent this issue; we then analyze their convergence under heavy-tailed noise. Furthermore, we develop a new adaptive coordinate-wise clipping algorithm (ACClip) tailored to such settings. Subsequently, we show how adaptive methods like Adam can be viewed through the lens of clipping, which helps us explain Adam's strong performance under heavy-tail noise settings. Finally, we show that the proposed ACClip outperforms Adam for both BERT pretraining and finetuning tasks.
How To Backdoor Federated Learning
Oct 01, 2018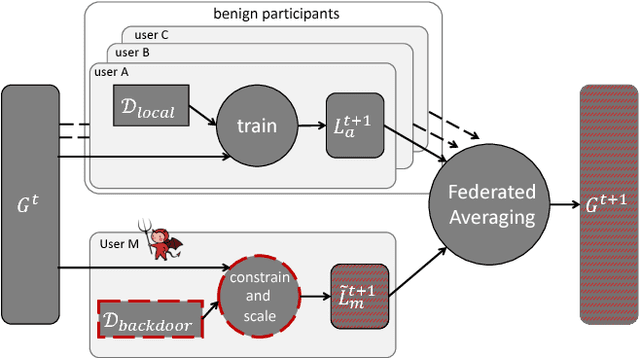
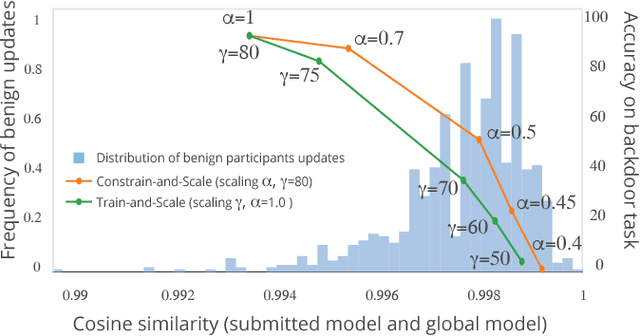
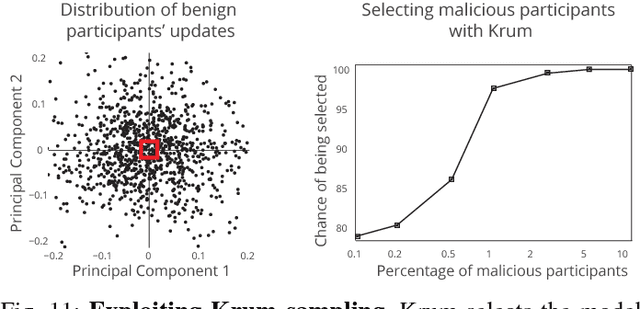
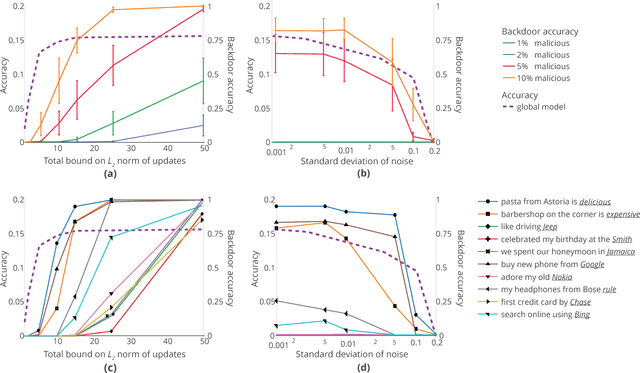
Federated learning enables thousands of participants to construct a deep learning model without sharing their private training data with each other. For example, multiple smartphones can jointly train a next-word predictor for keyboards without revealing what individual users type. We demonstrate that any participant in federated learning can introduce hidden backdoor functionality into the joint global model, e.g., to ensure that an image classifier assigns an attacker-chosen label to images with certain features, or that a word predictor completes certain sentences with an attacker-chosen word. We design and evaluate a new model-poisoning methodology based on model replacement. An attacker selected in a single round of federated learning can cause the global model to immediately reach 100% accuracy on the backdoor task. We evaluate the attack under different assumptions for the standard federated-learning tasks and show that it greatly outperforms data poisoning. Our generic constrain-and-scale technique also evades anomaly detection-based defenses by incorporating the evasion into the attacker's loss function during training.
Semantic Segmentation with Scarce Data
Aug 02, 2018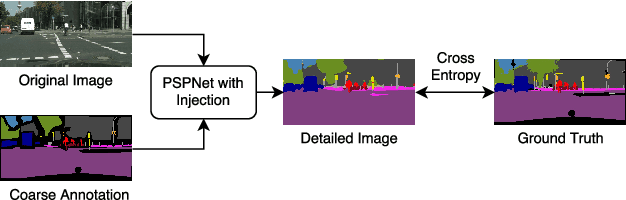
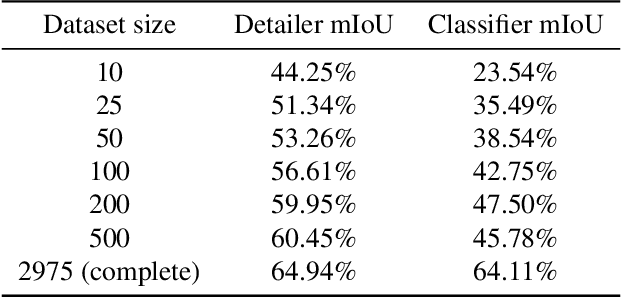
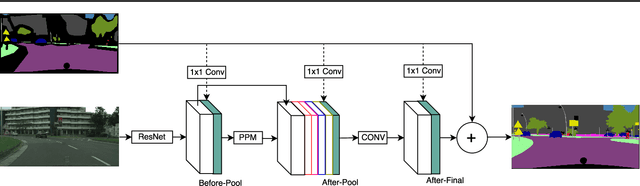
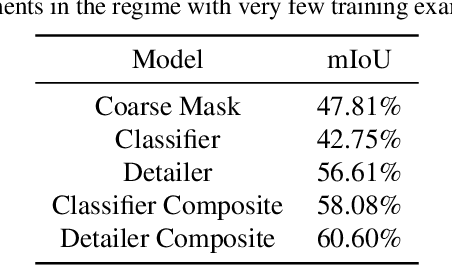
Semantic segmentation is a challenging vision problem that usually necessitates the collection of large amounts of finely annotated data, which is often quite expensive to obtain. Coarsely annotated data provides an interesting alternative as it is usually substantially more cheap. In this work, we present a method to leverage coarsely annotated data along with fine supervision to produce better segmentation results than would be obtained when training using only the fine data. We validate our approach by simulating a scarce data setting with less than 200 low resolution images from the Cityscapes dataset and show that our method substantially outperforms solely training on the fine annotation data by an average of 15.52% mIoU and outperforms the coarse mask by an average of 5.28% mIoU.
Convolutional Networks with Adaptive Inference Graphs
Jul 24, 2018
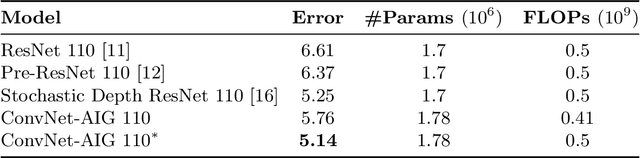
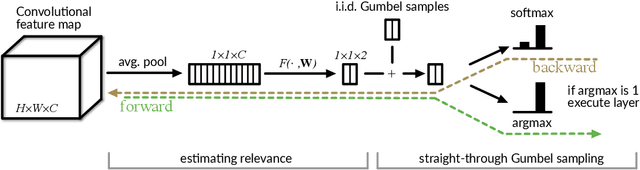
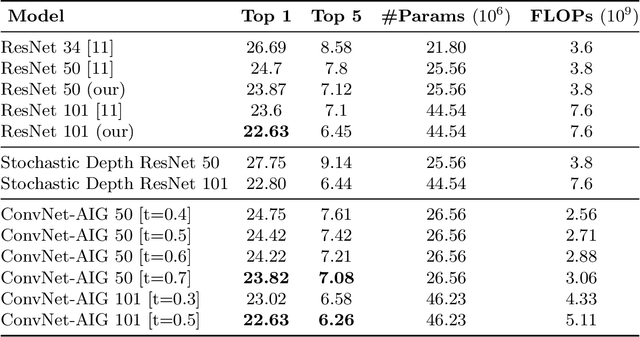
Do convolutional networks really need a fixed feed-forward structure? What if, after identifying the high-level concept of an image, a network could move directly to a layer that can distinguish fine-grained differences? Currently, a network would first need to execute sometimes hundreds of intermediate layers that specialize in unrelated aspects. Ideally, the more a network already knows about an image, the better it should be at deciding which layer to compute next. In this work, we propose convolutional networks with adaptive inference graphs (ConvNet-AIG) that adaptively define their network topology conditioned on the input image. Following a high-level structure similar to residual networks (ResNets), ConvNet-AIG decides for each input image on the fly which layers are needed. In experiments on ImageNet we show that ConvNet-AIG learns distinct inference graphs for different categories. Both ConvNet-AIG with 50 and 101 layers outperform their ResNet counterpart, while using 20% and 33% less computations respectively. By grouping parameters into layers for related classes and only executing relevant layers, ConvNet-AIG improves both efficiency and overall classification quality. Lastly, we also study the effect of adaptive inference graphs on the susceptibility towards adversarial examples. We observe that ConvNet-AIG shows a higher robustness than ResNets, complementing other known defense mechanisms.
Learning to Evaluate Image Captioning
Jun 17, 2018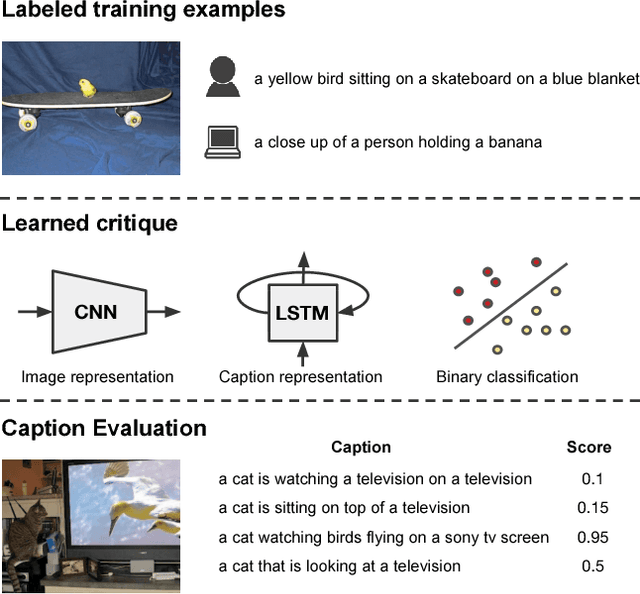
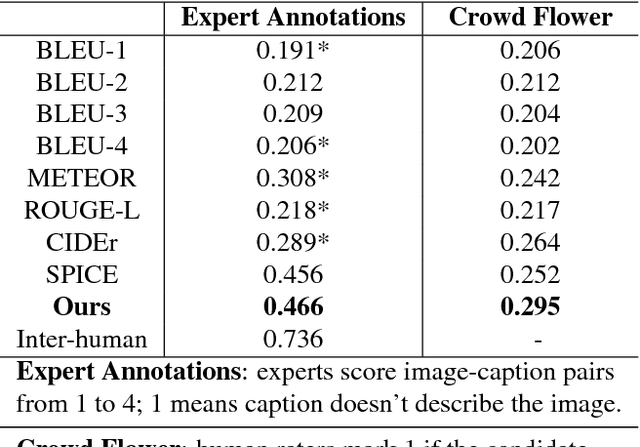
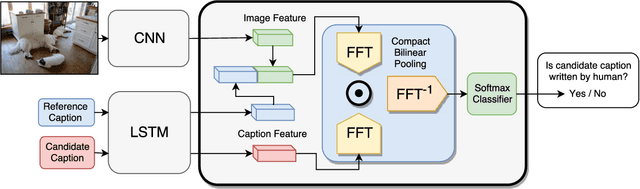
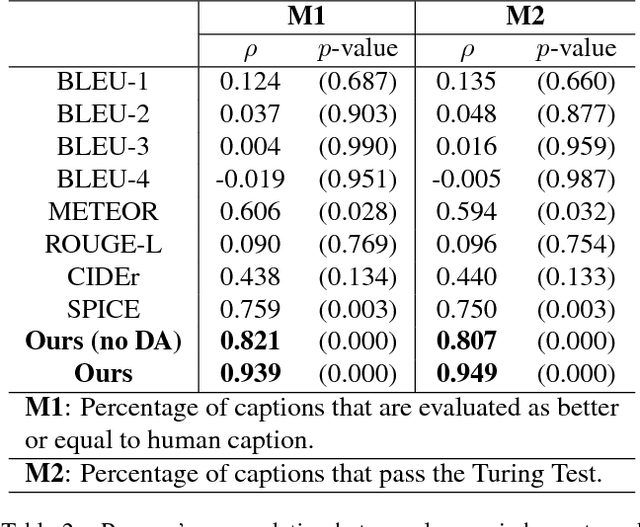
Evaluation metrics for image captioning face two challenges. Firstly, commonly used metrics such as CIDEr, METEOR, ROUGE and BLEU often do not correlate well with human judgments. Secondly, each metric has well known blind spots to pathological caption constructions, and rule-based metrics lack provisions to repair such blind spots once identified. For example, the newly proposed SPICE correlates well with human judgments, but fails to capture the syntactic structure of a sentence. To address these two challenges, we propose a novel learning based discriminative evaluation metric that is directly trained to distinguish between human and machine-generated captions. In addition, we further propose a data augmentation scheme to explicitly incorporate pathological transformations as negative examples during training. The proposed metric is evaluated with three kinds of robustness tests and its correlation with human judgments. Extensive experiments show that the proposed data augmentation scheme not only makes our metric more robust toward several pathological transformations, but also improves its correlation with human judgments. Our metric outperforms other metrics on both caption level human correlation in Flickr 8k and system level human correlation in COCO. The proposed approach could be served as a learning based evaluation metric that is complementary to existing rule-based metrics.
Deep Learning is Robust to Massive Label Noise
Feb 26, 2018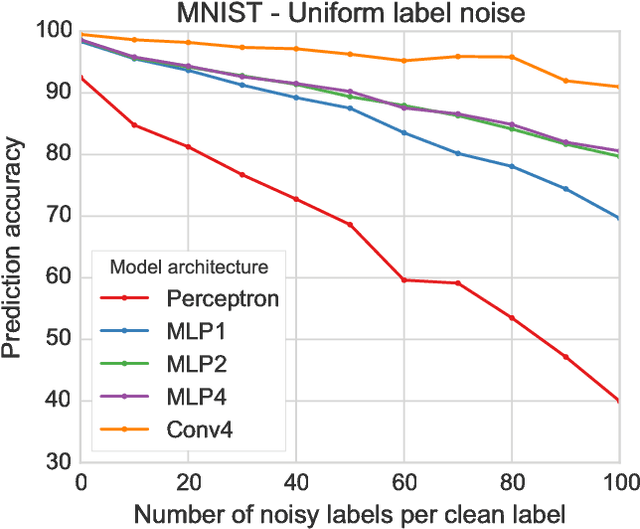
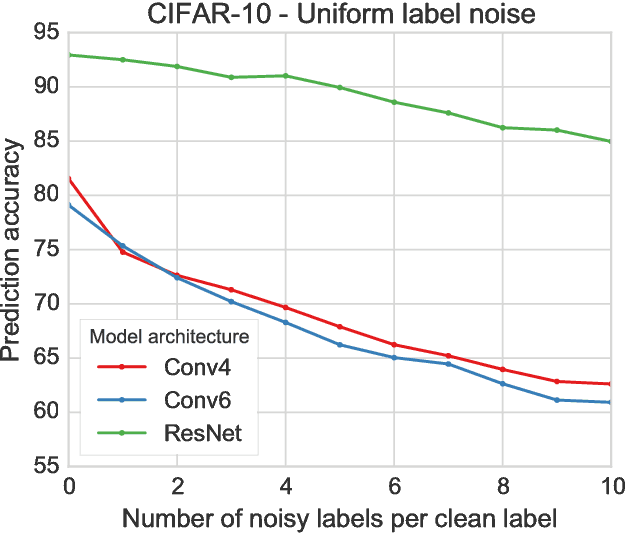
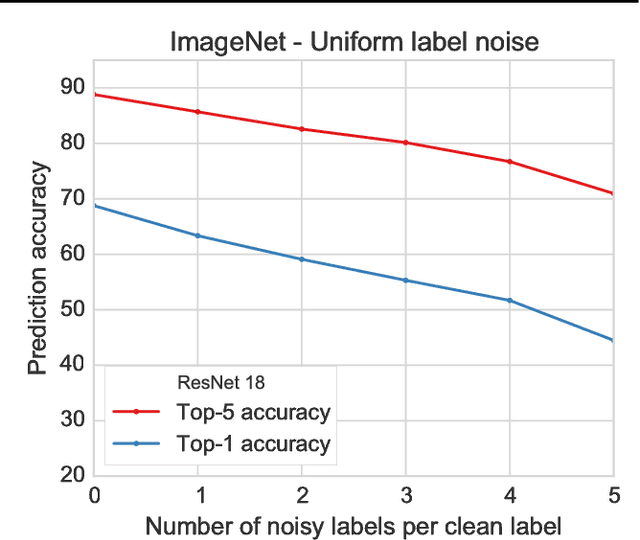
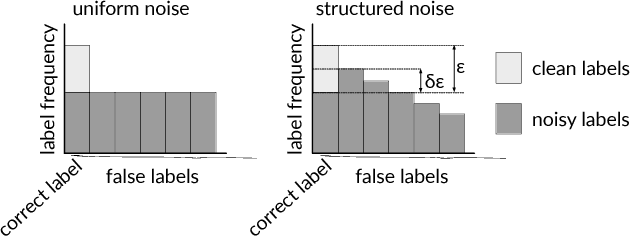
Deep neural networks trained on large supervised datasets have led to impressive results in image classification and other tasks. However, well-annotated datasets can be time-consuming and expensive to collect, lending increased interest to larger but noisy datasets that are more easily obtained. In this paper, we show that deep neural networks are capable of generalizing from training data for which true labels are massively outnumbered by incorrect labels. We demonstrate remarkably high test performance after training on corrupted data from MNIST, CIFAR, and ImageNet. For example, on MNIST we obtain test accuracy above 90 percent even after each clean training example has been diluted with 100 randomly-labeled examples. Such behavior holds across multiple patterns of label noise, even when erroneous labels are biased towards confusing classes. We show that training in this regime requires a significant but manageable increase in dataset size that is related to the factor by which correct labels have been diluted. Finally, we provide an analysis of our results that shows how increasing noise decreases the effective batch size.