 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGROUNDEDKG-RAG: Grounded Knowledge Graph Index for Long-document Question Answering
Apr 06, 2026Retrieval-augmented generation (RAG) systems have been widely adopted in contemporary large language models (LLMs) due to their ability to improve generation quality while reducing the required input context length. In this work, we focus on RAG systems for long-document question answering. Current approaches suffer from a heavy reliance on LLM descriptions resulting in high resource consumption and latency, repetitive content across hierarchical levels, and hallucinations due to no or limited grounding in the source text. To improve both efficiency and factual accuracy through grounding, we propose GroundedKG-RAG, a RAG system in which the knowledge graph is explicitly extracted from and grounded in the source document. Specifically, we define nodes in GroundedKG as entities and actions, and edges as temporal or semantic relations, with each node and edge grounded in the original sentences. We construct GroundedKG from semantic role labeling (SRL) and abstract meaning representation (AMR) parses and then embed it for retrieval. During querying, we apply the same transformation to the query and retrieve the most relevant sentences from the grounded source text for question answering. We evaluate GroundedKG-RAG on examples from the NarrativeQA dataset and find that it performs on par with a state-of-the art proprietary long-context model at smaller cost and outperforms a competitive baseline. Additionally, our GroundedKG is interpretable and readable by humans, facilitating auditing of results and error analysis.
With Argus Eyes: Assessing Retrieval Gaps via Uncertainty Scoring to Detect and Remedy Retrieval Blind Spots
Feb 10, 2026Reliable retrieval-augmented generation (RAG) systems depend fundamentally on the retriever's ability to find relevant information. We show that neural retrievers used in RAG systems have blind spots, which we define as the failure to retrieve entities that are relevant to the query, but have low similarity to the query embedding. We investigate the training-induced biases that cause such blind spot entities to be mapped to inaccessible parts of the embedding space, resulting in low retrievability. Using a large-scale dataset constructed from Wikidata relations and first paragraphs of Wikipedia, and our proposed Retrieval Probability Score (RPS), we show that blind spot risk in standard retrievers (e.g., CONTRIEVER, REASONIR) can be predicted pre-index from entity embedding geometry, avoiding expensive retrieval evaluations. To address these blind spots, we introduce ARGUS, a pipeline that enables the retrievability of high-risk (low-RPS) entities through targeted document augmentation from a knowledge base (KB), first paragraphs of Wikipedia, in our case. Extensive experiments on BRIGHT, IMPLIRET, and RAR-B show that ARGUS achieves consistent improvements across all evaluated retrievers (averaging +3.4 nDCG@5 and +4.5 nDCG@10 absolute points), with substantially larger gains in challenging subsets. These results establish that preemptively remedying blind spots is critical for building robust and trustworthy RAG systems (Code and Data).
Apertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
Explaining Away Syntactic Structure in Semantic Document Representations
Jun 05, 2018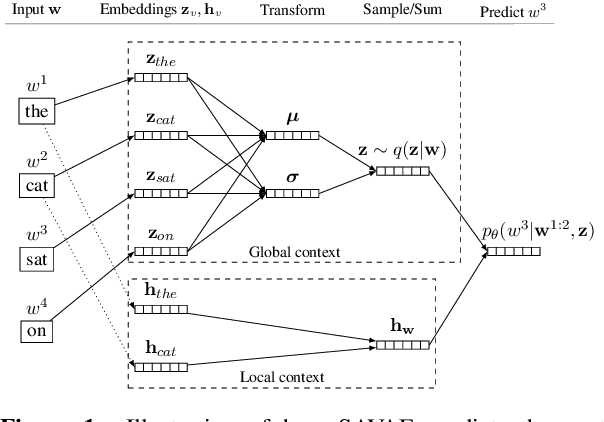
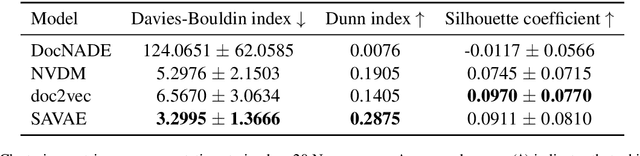
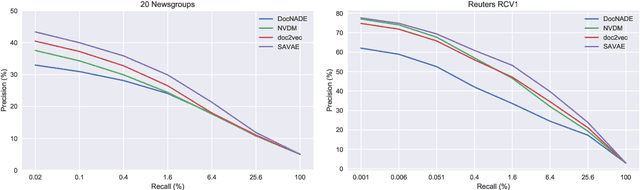

Most generative document models act on bag-of-words input in an attempt to focus on the semantic content and thereby partially forego syntactic information. We argue that it is preferable to keep the original word order intact and explicitly account for the syntactic structure instead. We propose an extension to the Neural Variational Document Model (Miao et al., 2016) that does exactly that to separate local (syntactic) context from the global (semantic) representation of the document. Our model builds on the variational autoencoder framework to define a generative document model based on next-word prediction. We name our approach Sequence-Aware Variational Autoencoder since in contrast to its predecessor, it operates on the true input sequence. In a series of experiments we observe stronger topicality of the learned representations as well as increased robustness to syntactic noise in our training data.
Discovering Valuable Items from Massive Data
Jun 02, 2015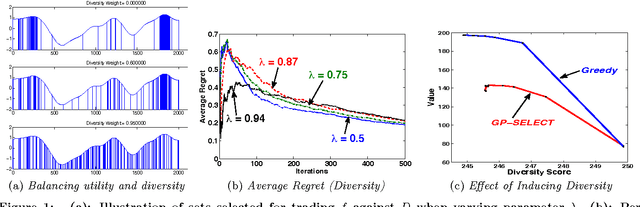
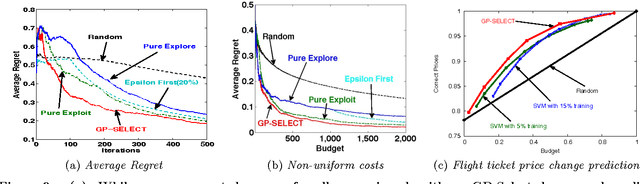
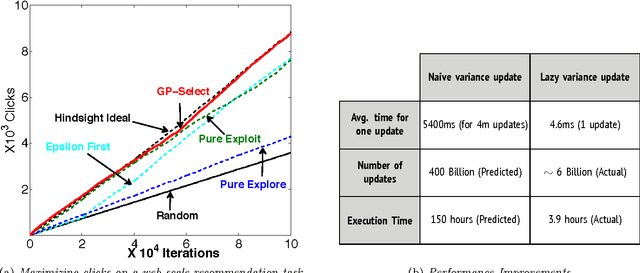
Suppose there is a large collection of items, each with an associated cost and an inherent utility that is revealed only once we commit to selecting it. Given a budget on the cumulative cost of the selected items, how can we pick a subset of maximal value? This task generalizes several important problems such as multi-arm bandits, active search and the knapsack problem. We present an algorithm, GP-Select, which utilizes prior knowledge about similarity be- tween items, expressed as a kernel function. GP-Select uses Gaussian process prediction to balance exploration (estimating the unknown value of items) and exploitation (selecting items of high value). We extend GP-Select to be able to discover sets that simultaneously have high utility and are diverse. Our preference for diversity can be specified as an arbitrary monotone submodular function that quantifies the diminishing returns obtained when selecting similar items. Furthermore, we exploit the structure of the model updates to achieve an order of magnitude (up to 40X) speedup in our experiments without resorting to approximations. We provide strong guarantees on the performance of GP-Select and apply it to three real-world case studies of industrial relevance: (1) Refreshing a repository of prices in a Global Distribution System for the travel industry, (2) Identifying diverse, binding-affine peptides in a vaccine de- sign task and (3) Maximizing clicks in a web-scale recommender system by recommending items to users.