 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPECTRE : Spectral Conditioning Helps to Overcome the Expressivity Limits of One-shot Graph Generators
Apr 04, 2022
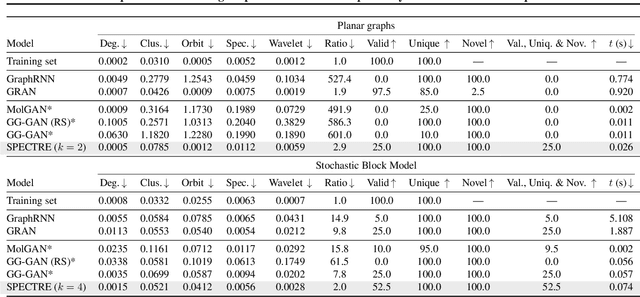
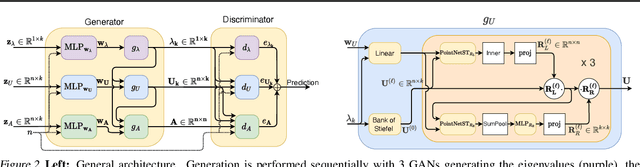
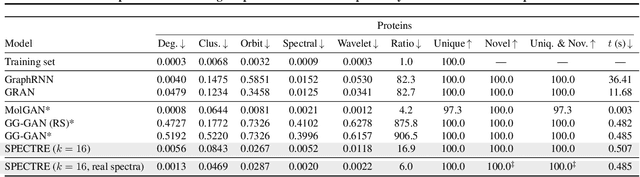
We approach the graph generation problem from a spectral perspective by first generating the dominant parts of the graph Laplacian spectrum and then building a graph matching these eigenvalues and eigenvectors. Spectral conditioning allows for direct modeling of the global and local graph structure and helps to overcome the expressivity and mode collapse issues of one-shot graph generators. Our novel GAN, called SPECTRE, enables the one-shot generation of much larger graphs than previously possible with one-shot models. SPECTRE outperforms state-of-the-art deep autoregressive generators in terms of modeling fidelity, while also avoiding expensive sequential generation and dependence on node ordering. A case in point, in sizable synthetic and real-world graphs SPECTRE achieves a 4-to-170 fold improvement over the best competitor that does not overfit and is 23-to-30 times faster than autoregressive generators.
SQALER: Scaling Question Answering by Decoupling Multi-Hop and Logical Reasoning
Oct 27, 2021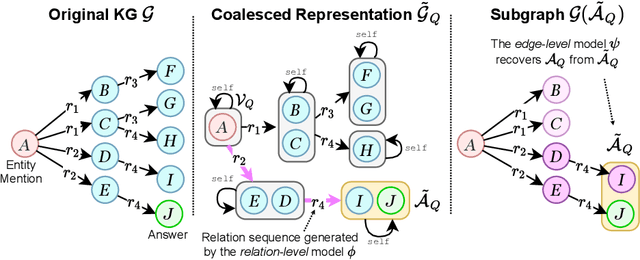
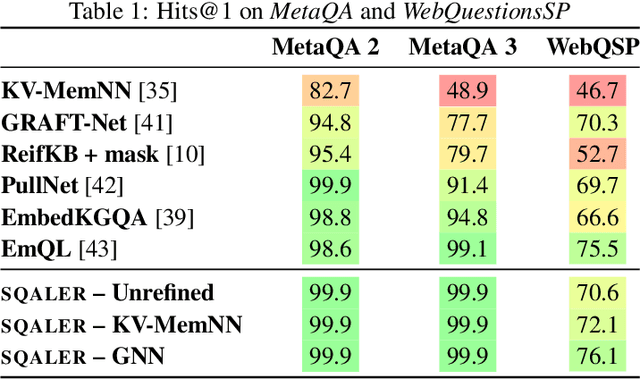
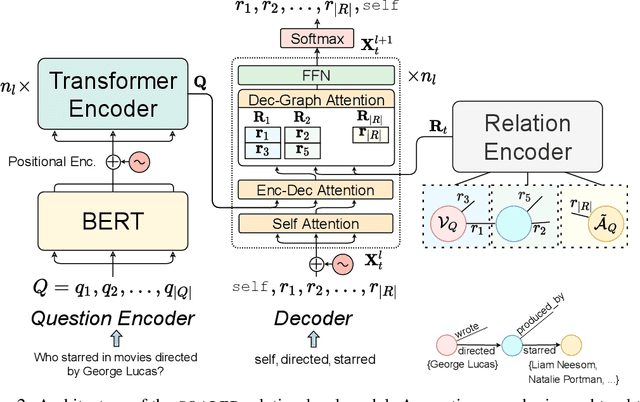
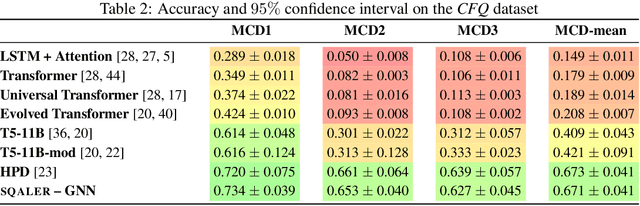
State-of-the-art approaches to reasoning and question answering over knowledge graphs (KGs) usually scale with the number of edges and can only be applied effectively on small instance-dependent subgraphs. In this paper, we address this issue by showing that multi-hop and more complex logical reasoning can be accomplished separately without losing expressive power. Motivated by this insight, we propose an approach to multi-hop reasoning that scales linearly with the number of relation types in the graph, which is usually significantly smaller than the number of edges or nodes. This produces a set of candidate solutions that can be provably refined to recover the solution to the original problem. Our experiments on knowledge-based question answering show that our approach solves the multi-hop MetaQA dataset, achieves a new state-of-the-art on the more challenging WebQuestionsSP, is orders of magnitude more scalable than competitive approaches, and can achieve compositional generalization out of the training distribution.
Partition and Code: learning how to compress graphs
Jul 05, 2021
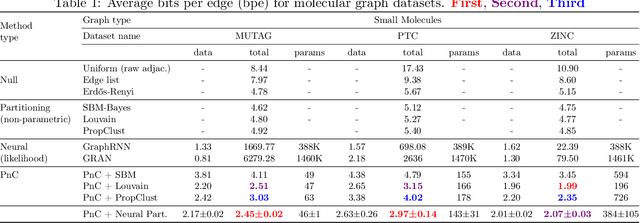
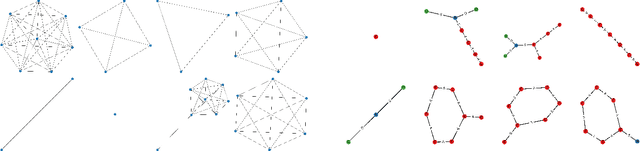
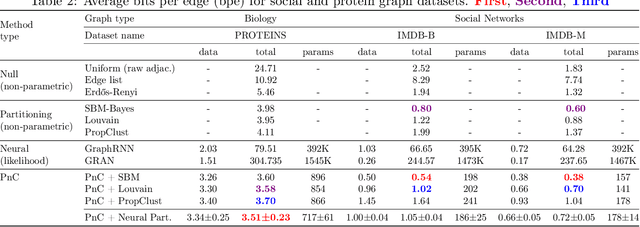
Can we use machine learning to compress graph data? The absence of ordering in graphs poses a significant challenge to conventional compression algorithms, limiting their attainable gains as well as their ability to discover relevant patterns. On the other hand, most graph compression approaches rely on domain-dependent handcrafted representations and cannot adapt to different underlying graph distributions. This work aims to establish the necessary principles a lossless graph compression method should follow to approach the entropy storage lower bound. Instead of making rigid assumptions about the graph distribution, we formulate the compressor as a probabilistic model that can be learned from data and generalise to unseen instances. Our "Partition and Code" framework entails three steps: first, a partitioning algorithm decomposes the graph into elementary structures, then these are mapped to the elements of a small dictionary on which we learn a probability distribution, and finally, an entropy encoder translates the representation into bits. All three steps are parametric and can be trained with gradient descent. We theoretically compare the compression quality of several graph encodings and prove, under mild conditions, a total ordering of their expected description lengths. Moreover, we show that, under the same conditions, PnC achieves compression gains w.r.t. the baselines that grow either linearly or quadratically with the number of vertices. Our algorithms are quantitatively evaluated on diverse real-world networks obtaining significant performance improvements with respect to different families of non-parametric and parametric graph compressors.
What training reveals about neural network complexity
Jun 08, 2021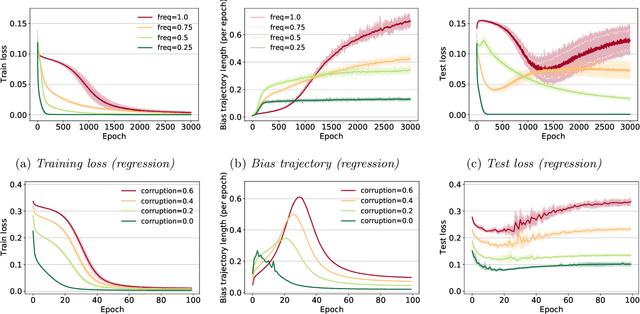
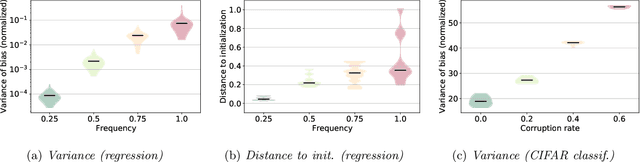
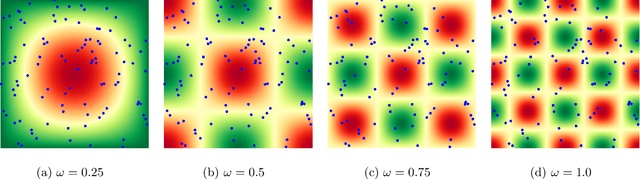
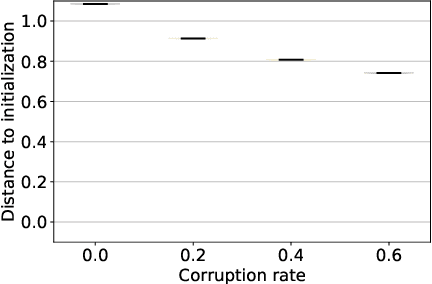
This work explores the hypothesis that the complexity of the function a deep neural network (NN) is learning can be deduced by how fast its weights change during training. Our analysis provides evidence for this supposition by relating the network's distribution of Lipschitz constants (i.e., the norm of the gradient at different regions of the input space) during different training intervals with the behavior of the stochastic training procedure. We first observe that the average Lipschitz constant close to the training data affects various aspects of the parameter trajectory, with more complex networks having a longer trajectory, bigger variance, and often veering further from their initialization. We then show that NNs whose biases are trained more steadily have bounded complexity even in regions of the input space that are far from any training point. Finally, we find that steady training with Dropout implies a training- and data-dependent generalization bound that grows poly-logarithmically with the number of parameters. Overall, our results support the hypothesis that good training behavior can be a useful bias towards good generalization.
Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth
Mar 05, 2021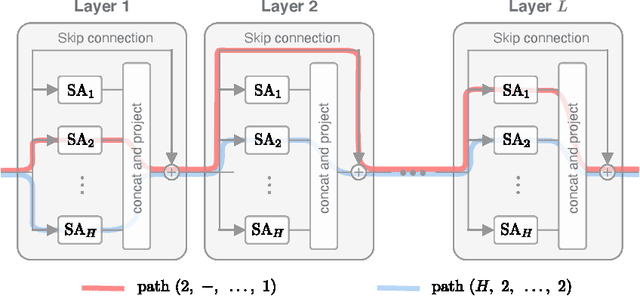
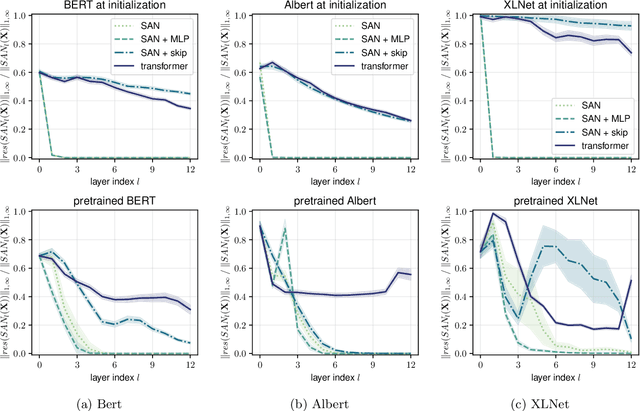
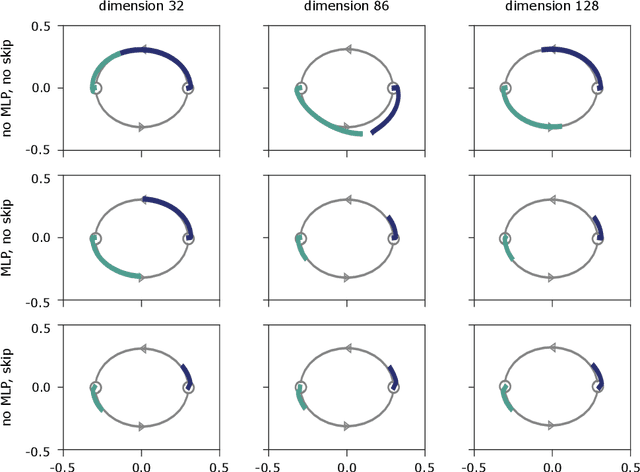
Attention-based architectures have become ubiquitous in machine learning, yet our understanding of the reasons for their effectiveness remains limited. This work proposes a new way to understand self-attention networks: we show that their output can be decomposed into a sum of smaller terms, each involving the operation of a sequence of attention heads across layers. Using this decomposition, we prove that self-attention possesses a strong inductive bias towards "token uniformity". Specifically, without skip connections or multi-layer perceptrons (MLPs), the output converges doubly exponentially to a rank-1 matrix. On the other hand, skip connections and MLPs stop the output from degeneration. Our experiments verify the identified convergence phenomena on different variants of standard transformer architectures.
Building powerful and equivariant graph neural networks with structural message-passing
Jul 11, 2020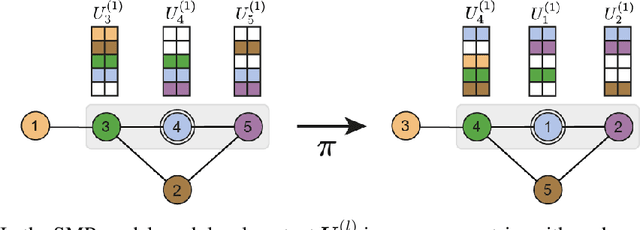


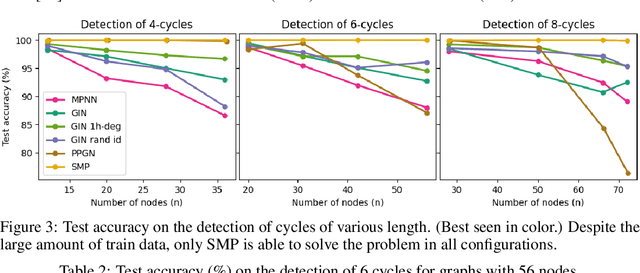
Message-passing has proved to be an effective way to design graph neural networks, as it is able to leverage both permutation equivariance and an inductive bias towards learning local structures to achieve good generalization. However, current message-passing architectures have a limited representation power and fail to learn basic topological properties of graphs. We address this problem and propose a new message-passing framework that is powerful while preserving permutation equivariance. Specifically, we propagate unique node identifiers in the form of a one-hot encoding in order to learn a local context matrix around each node. This enables to learn rich local information about both features and topology, which can be pooled to obtain node representations. Experimentally, we find our model to be superior at predicting various graph topological properties, opening the way to novel powerful architectures that are both equivariant and computationally efficient.
Multi-Head Attention: Collaborate Instead of Concatenate
Jun 29, 2020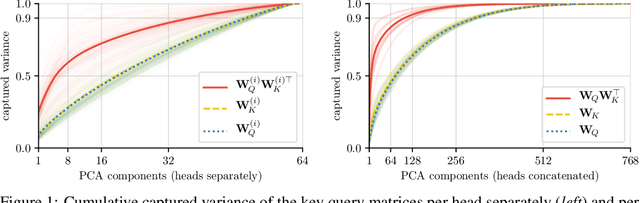
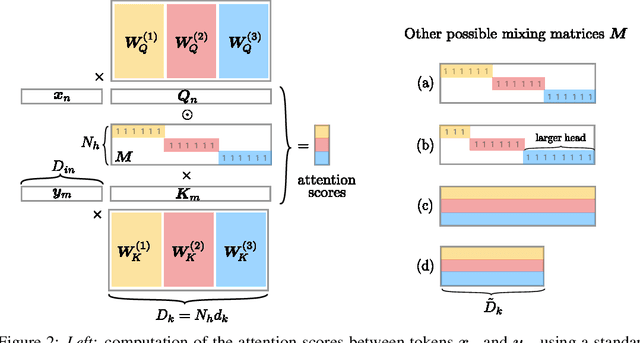
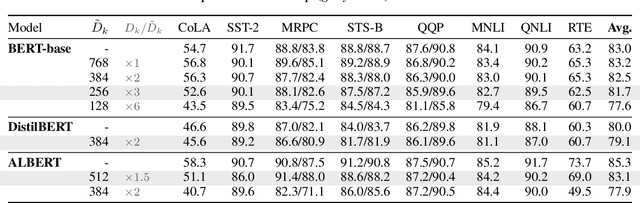

Attention layers are widely used in natural language processing (NLP) and are beginning to influence computer vision architectures. However, they suffer from over-parameterization. For instance, it was shown that the majority of attention heads could be pruned without impacting accuracy. This work aims to enhance current understanding on how multiple heads interact. Motivated by the observation that trained attention heads share common key/query projections, we propose a collaborative multi-head attention layer that enables heads to learn shared projections. Our scheme improves the computational cost and number of parameters in an attention layer and can be used as a drop-in replacement in any transformer architecture. For instance, by allowing heads to collaborate on a neural machine translation task, we can reduce the key dimension by a factor of eight without any loss in performance. We also show that it is possible to re-parametrize a pre-trained multi-head attention layer into our collaborative attention layer. Even without retraining, collaborative multi-head attention manages to reduce the size of the key and query projections by half without sacrificing accuracy. Our code is public.
Erdos Goes Neural: an Unsupervised Learning Framework for Combinatorial Optimization on Graphs
Jun 29, 2020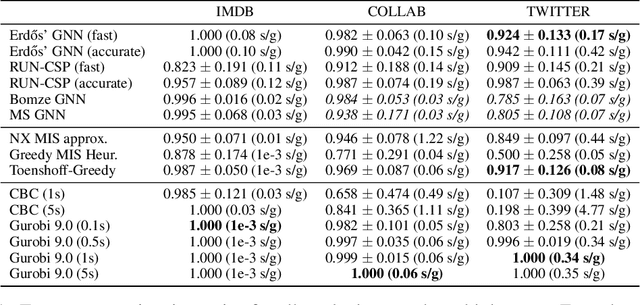
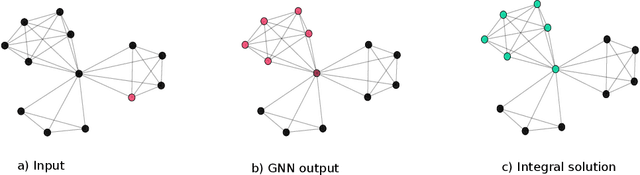
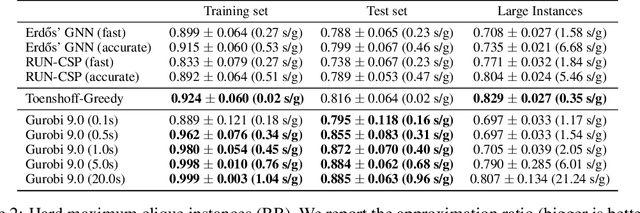
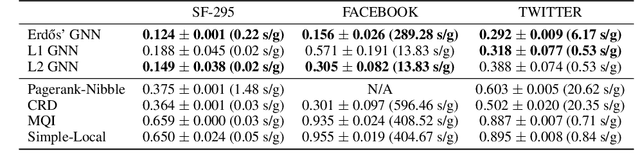
Combinatorial optimization problems are notoriously challenging for neural networks, especially in the absence of labeled instances. This work proposes an unsupervised learning framework for CO problems on graphs that can provide integral solutions of certified quality. Inspired by Erdos' probabilistic method, we use a neural network to parametrize a probability distribution over sets. Crucially, we show that when the network is optimized w.r.t. a suitably chosen loss, the learned distribution contains, with controlled probability, a low-cost integral solution that obeys the constraints of the combinatorial problem. The probabilistic proof of existence is then derandomized to decode the desired solutions. We demonstrate the efficacy of this approach to obtain valid solutions to the maximum clique problem and to perform local graph clustering. Our method achieves competitive results on both real datasets and synthetic hard instances.
How hard is graph isomorphism for graph neural networks?
May 13, 2020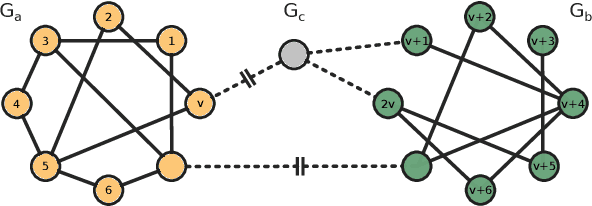

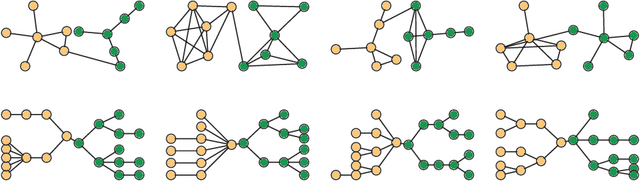

A hallmark of graph neural networks is their ability to distinguish the isomorphism class of their inputs. This study derives the first hardness results for graph isomorphism in the message-passing model (MPNN). MPNN encompasses the majority of graph neural networks used today and is universal in the limit when nodes are given unique features. The analysis relies on the introduced measure of communication capacity. Capacity measures how much information the nodes of a network can exchange during the forward pass and depends on the depth, message-size, global state, and width of the architecture. It is shown that the capacity of MPNN needs to grow linearly with the number of nodes so that a network can distinguish trees and quadratically for general connected graphs. Crucially, the derived bounds are applicable not only to worst-case instances but over a portion of all inputs. An empirical study involving 12 tasks of varying difficulty and 420 networks reveals strong alignment between actual performance and theoretical predictions.
On the Relationship between Self-Attention and Convolutional Layers
Nov 08, 2019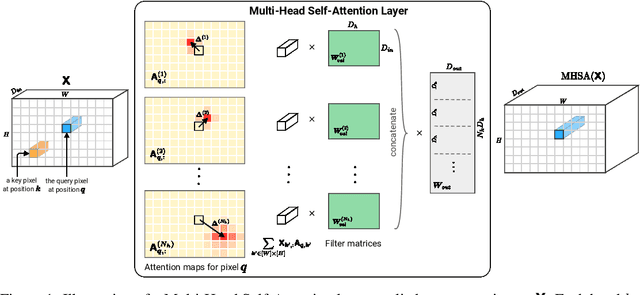
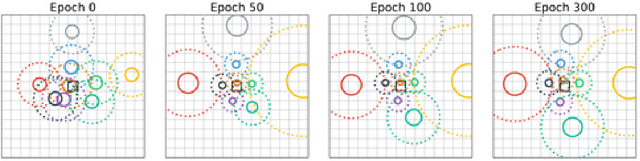

Recent trends of incorporating attention mechanisms in vision have led researchers to reconsider the supremacy of convolutional layers as a primary building block. Beyond helping CNNs to handle long-range dependencies, Ramachandran et al. (2019) showed that attention can completely replace convolution and achieve state-of-the-art performance on vision tasks. This raises the question: do learned attention layers operate similarly to convolutional layers? This work provides evidence that attention layers can perform convolution and, indeed, they often learn to do so in practice. Specifically, we prove that a multi-head self-attention layer with sufficient number of heads is at least as powerful as any convolutional layer. Our numerical experiments then show that the phenomenon also occurs in practice, corroborating our analysis. Our code is publicly available.