 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning Reliable Priors in the Function Space
Jun 06, 2021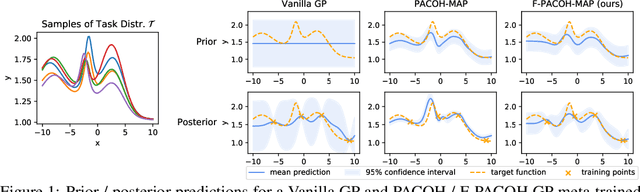
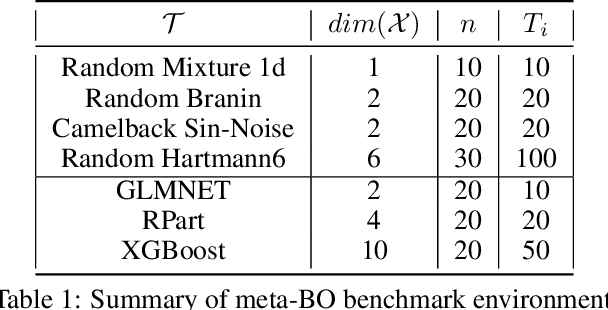
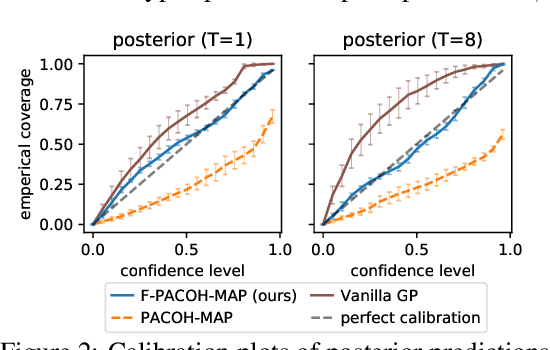

Meta-Learning promises to enable more data-efficient inference by harnessing previous experience from related learning tasks. While existing meta-learning methods help us to improve the accuracy of our predictions in face of data scarcity, they fail to supply reliable uncertainty estimates, often being grossly overconfident in their predictions. Addressing these shortcomings, we introduce a novel meta-learning framework, called F-PACOH, that treats meta-learned priors as stochastic processes and performs meta-level regularization directly in the function space. This allows us to directly steer the probabilistic predictions of the meta-learner towards high epistemic uncertainty in regions of insufficient meta-training data and, thus, obtain well-calibrated uncertainty estimates. Finally, we showcase how our approach can be integrated with sequential decision making, where reliable uncertainty quantification is imperative. In our benchmark study on meta-learning for Bayesian Optimization (BO), F-PACOH significantly outperforms all other meta-learners and standard baselines. Even in a challenging lifelong BO setting, where optimization tasks arrive one at a time and the meta-learner needs to build up informative prior knowledge incrementally, our proposed method demonstrates strong positive transfer.
Energy-Based Learning for Cooperative Games, with Applications to Feature/Data/Model Valuations
Jun 05, 2021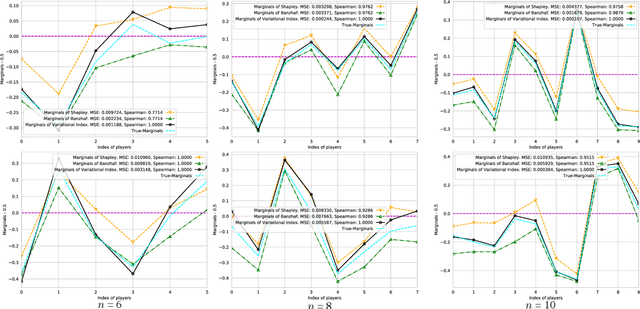
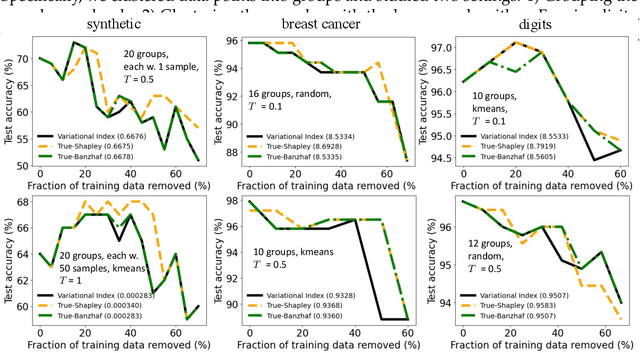
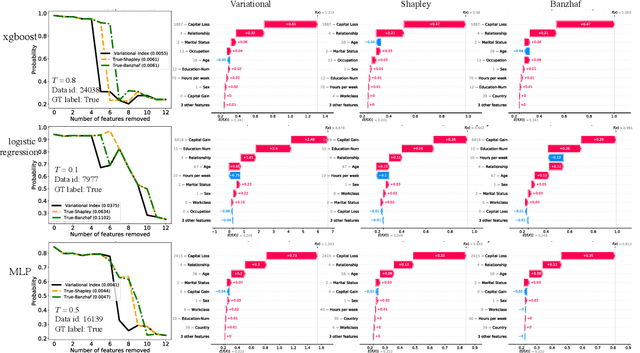
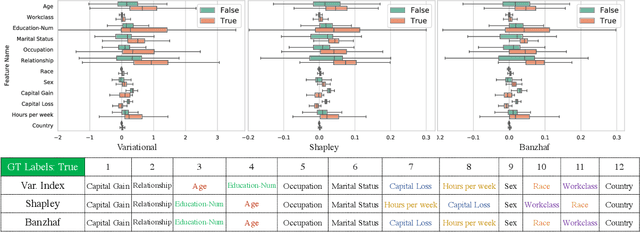
Valuation problems, such as attribution-based feature interpretation, data valuation and model valuation for ensembles, become increasingly more important in many machine learning applications. Such problems are commonly solved by well-known game-theoretic criteria, such as Shapley value or Banzhaf index. In this work, we present a novel energy-based treatment for cooperative games, with a theoretical justification by the maximum entropy framework. Surprisingly, by conducting variational inference of the energy-based model, we recover various game-theoretic valuation criteria, such as Shapley value and Banzhaf index, through conducting one-step gradient ascent for maximizing the mean-field ELBO objective. This observation also verifies the rationality of existing criteria, as they are all trying to decouple the correlations among the players through the mean-field approach. By running gradient ascent for multiple steps, we achieve a trajectory of the valuations, among which we define the valuation with the best conceivable decoupling error as the Variational Index. We experimentally demonstrate that the proposed Variational Index enjoys intriguing properties on certain synthetic and real-world valuation problems.
Addressing the Long-term Impact of ML Decisions via Policy Regret
Jun 02, 2021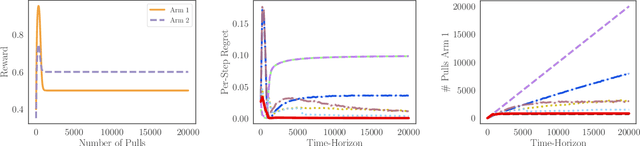
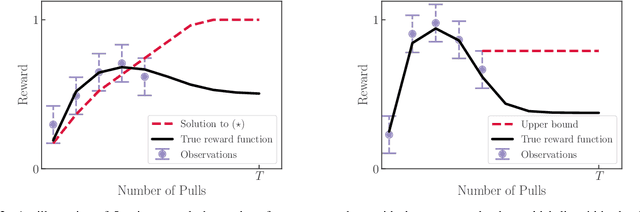
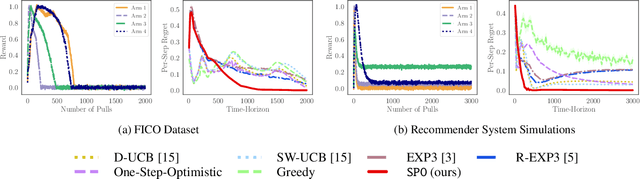
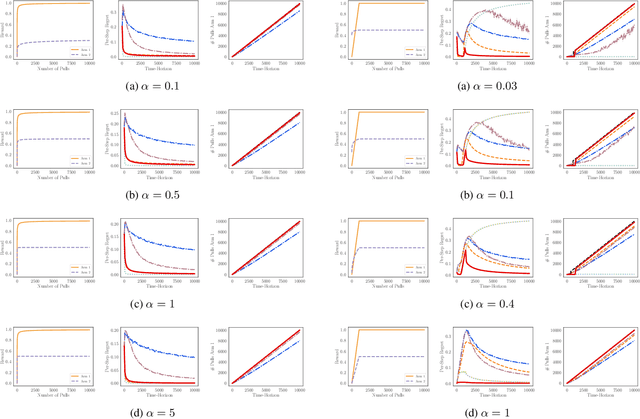
Machine Learning (ML) increasingly informs the allocation of opportunities to individuals and communities in areas such as lending, education, employment, and beyond. Such decisions often impact their subjects' future characteristics and capabilities in an a priori unknown fashion. The decision-maker, therefore, faces exploration-exploitation dilemmas akin to those in multi-armed bandits. Following prior work, we model communities as arms. To capture the long-term effects of ML-based allocation decisions, we study a setting in which the reward from each arm evolves every time the decision-maker pulls that arm. We focus on reward functions that are initially increasing in the number of pulls but may become (and remain) decreasing after a certain point. We argue that an acceptable sequential allocation of opportunities must take an arm's potential for growth into account. We capture these considerations through the notion of policy regret, a much stronger notion than the often-studied external regret, and present an algorithm with provably sub-linear policy regret for sufficiently long time horizons. We empirically compare our algorithm with several baselines and find that it consistently outperforms them, in particular for long time horizons.
Cherry-Picking Gradients: Learning Low-Rank Embeddings of Visual Data via Differentiable Cross-Approximation
May 29, 2021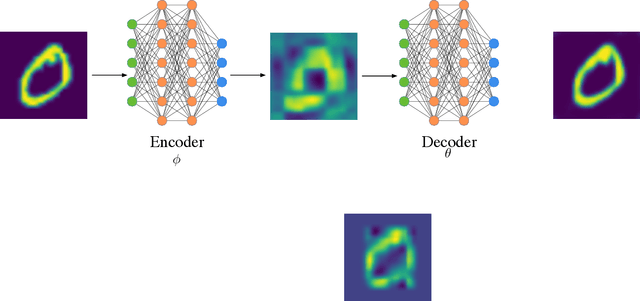


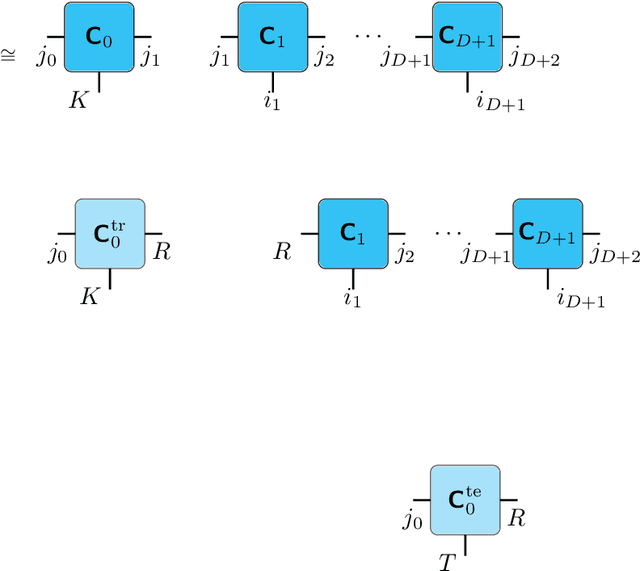
We propose an end-to-end trainable framework that processes large-scale visual data tensors by looking \emph{at a fraction of their entries only}. Our method combines a neural network encoder with a \emph{tensor train decomposition} to learn a low-rank latent encoding, coupled with cross-approximation (CA) to learn the representation through a subset of the original samples. CA is an adaptive sampling algorithm that is native to tensor decompositions and avoids working with the full high-resolution data explicitly. Instead, it actively selects local representative samples that we fetch out-of-core and on-demand. The required number of samples grows only logarithmically with the size of the input. Our implicit representation of the tensor in the network enables processing large grids that could not be otherwise tractable in their uncompressed form. The proposed approach is particularly useful for large-scale multidimensional grid data (e.g., 3D tomography), and for tasks that require context over a large receptive field (e.g., predicting the medical condition of entire organs). The code will be available at https://github.com/aelphy/c-pic
Near-Optimal Multi-Perturbation Experimental Design for Causal Structure Learning
May 28, 2021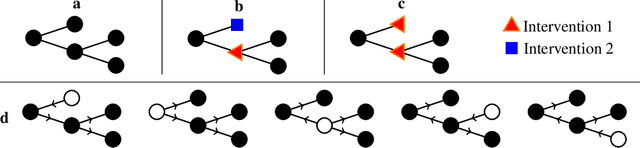
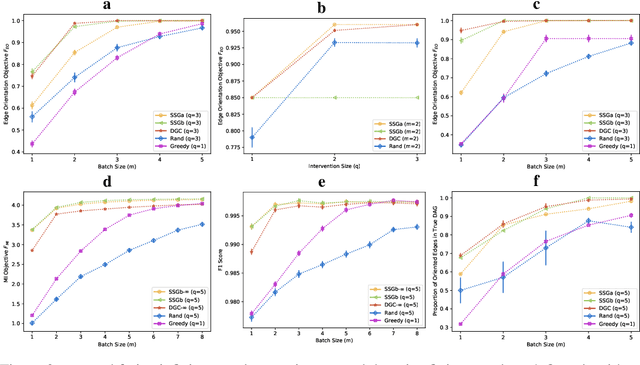
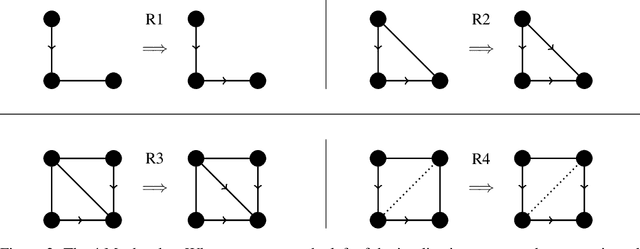
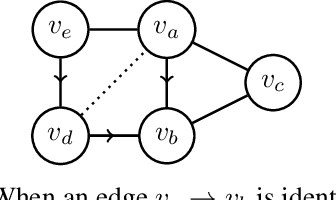
Causal structure learning is a key problem in many domains. Causal structures can be learnt by performing experiments on the system of interest. We address the largely unexplored problem of designing experiments that simultaneously intervene on multiple variables. While potentially more informative than the commonly considered single-variable interventions, selecting such interventions is algorithmically much more challenging, due to the doubly-exponential combinatorial search space over sets of composite interventions. In this paper, we develop efficient algorithms for optimizing different objective functions quantifying the informativeness of experiments. By establishing novel submodularity properties of these objectives, we provide approximation guarantees for our algorithms. Our algorithms empirically perform superior to both random interventions and algorithms that only select single-variable interventions.
DiBS: Differentiable Bayesian Structure Learning
May 25, 2021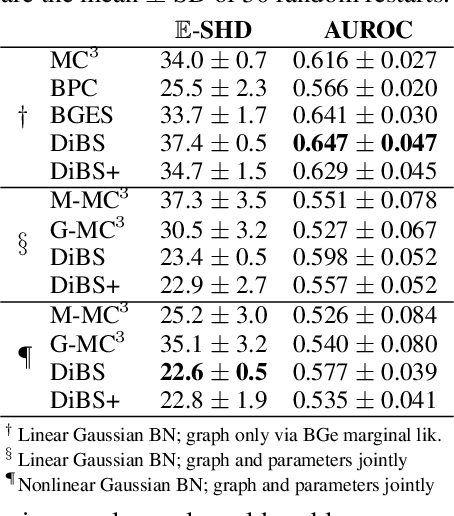
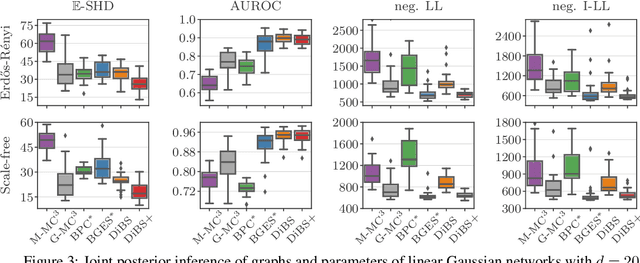
Bayesian structure learning allows inferring Bayesian network structure from data while reasoning about the epistemic uncertainty -- a key element towards enabling active causal discovery and designing interventions in real world systems. In this work, we propose a general, fully differentiable framework for Bayesian structure learning (DiBS) that operates in the continuous space of a latent probabilistic graph representation. Building on recent advances in variational inference, we use DiBS to devise an efficient method for approximating posteriors over structural models. Contrary to existing work, DiBS is agnostic to the form of the local conditional distributions and allows for joint posterior inference of both the graph structure and the conditional distribution parameters. This makes our method directly applicable to posterior inference of nonstandard Bayesian network models, e.g., with nonlinear dependencies encoded by neural networks. In evaluations on simulated and real-world data, DiBS significantly outperforms related approaches to joint posterior inference.
Regret Bounds for Gaussian-Process Optimization in Large Domains
Apr 29, 2021

The goal of this paper is to characterize Gaussian-Process optimization in the setting where the function domain is large relative to the number of admissible function evaluations, i.e., where it is impossible to find the global optimum. We provide upper bounds on the suboptimality (Bayesian simple regret) of the solution found by optimization strategies that are closely related to the widely used expected improvement (EI) and upper confidence bound (UCB) algorithms. These regret bounds illuminate the relationship between the number of evaluations, the domain size (i.e. cardinality of finite domains / Lipschitz constant of the covariance function in continuous domains), and the optimality of the retrieved function value. In particular, they show that even when the number of evaluations is far too small to find the global optimum, we can find nontrivial function values (e.g. values that achieve a certain ratio with the optimal value).
Overfitting in Bayesian Optimization: an empirical study and early-stopping solution
Apr 16, 2021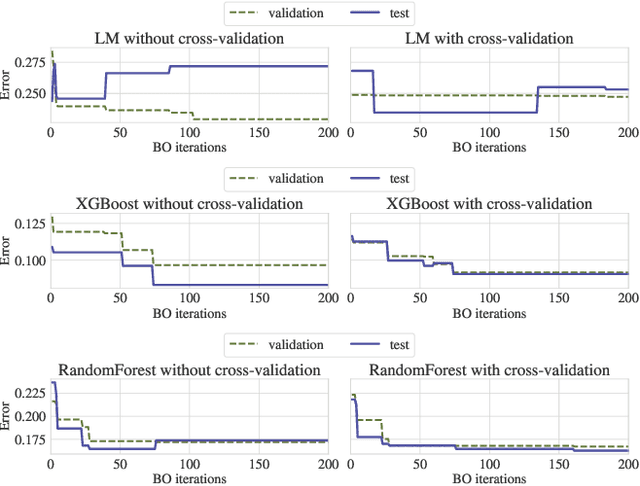
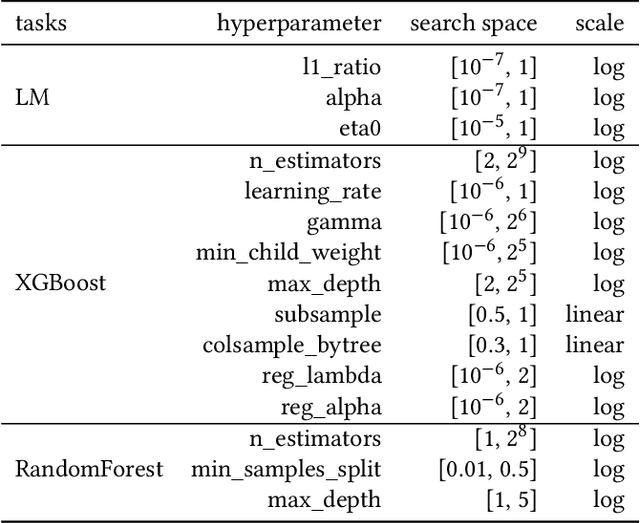
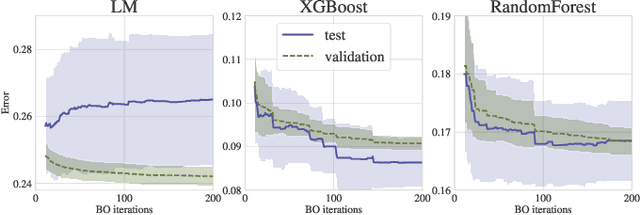
Bayesian Optimization (BO) is a successful methodology to tune the hyperparameters of machine learning algorithms. The user defines a metric of interest, such as the validation error, and BO finds the optimal hyperparameters that minimize it. However, the metric improvements on the validation set may not translate to the test set, especially on small datasets. In other words, BO can overfit. While cross-validation mitigates this, it comes with high computational cost. In this paper, we carry out the first systematic investigation of overfitting in BO and demonstrate that this is a serious yet often overlooked concern in practice. We propose the first problem-adaptive and interpretable criterion to early stop BO, reducing overfitting while mitigating the cost of cross-validation. Experimental results on real-world hyperparameter optimization tasks show that our approach can substantially reduce compute time with little to no loss of test accuracy,demonstrating a clear practical advantage over existing techniques.
Combining Pessimism with Optimism for Robust and Efficient Model-Based Deep Reinforcement Learning
Mar 18, 2021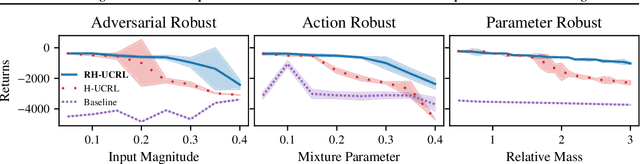
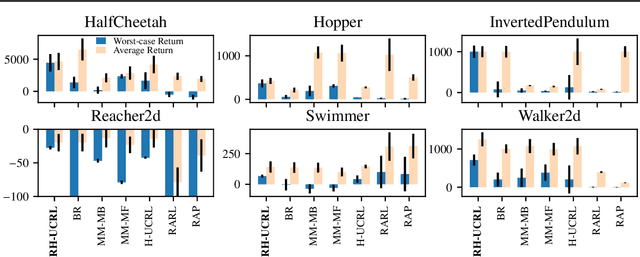
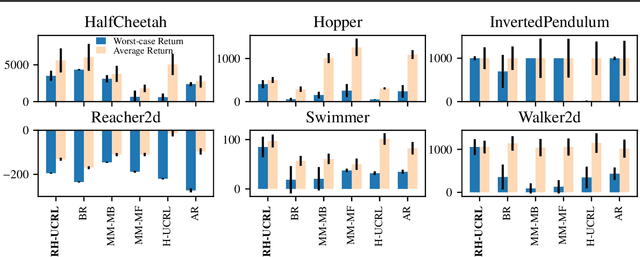
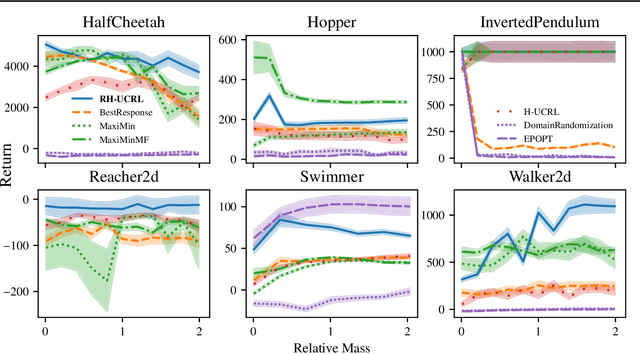
In real-world tasks, reinforcement learning (RL) agents frequently encounter situations that are not present during training time. To ensure reliable performance, the RL agents need to exhibit robustness against worst-case situations. The robust RL framework addresses this challenge via a worst-case optimization between an agent and an adversary. Previous robust RL algorithms are either sample inefficient, lack robustness guarantees, or do not scale to large problems. We propose the Robust Hallucinated Upper-Confidence RL (RH-UCRL) algorithm to provably solve this problem while attaining near-optimal sample complexity guarantees. RH-UCRL is a model-based reinforcement learning (MBRL) algorithm that effectively distinguishes between epistemic and aleatoric uncertainty and efficiently explores both the agent and adversary decision spaces during policy learning. We scale RH-UCRL to complex tasks via neural networks ensemble models as well as neural network policies. Experimentally, we demonstrate that RH-UCRL outperforms other robust deep RL algorithms in a variety of adversarial environments.
Information Directed Reward Learning for Reinforcement Learning
Feb 24, 2021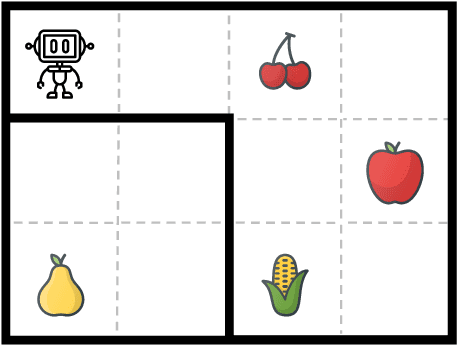

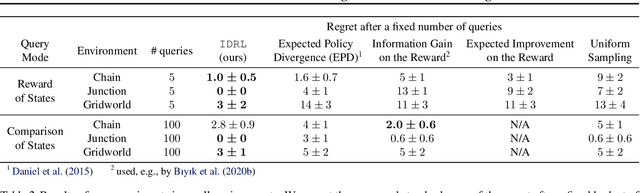
For many reinforcement learning (RL) applications, specifying a reward is difficult. In this paper, we consider an RL setting where the agent can obtain information about the reward only by querying an expert that can, for example, evaluate individual states or provide binary preferences over trajectories. From such expensive feedback, we aim to learn a model of the reward function that allows standard RL algorithms to achieve high expected return with as few expert queries as possible. For this purpose, we propose Information Directed Reward Learning (IDRL), which uses a Bayesian model of the reward function and selects queries that maximize the information gain about the difference in return between potentially optimal policies. In contrast to prior active reward learning methods designed for specific types of queries, IDRL naturally accommodates different query types. Moreover, by shifting the focus from reducing the reward approximation error to improving the policy induced by the reward model, it achieves similar or better performance with significantly fewer queries. We support our findings with extensive evaluations in multiple environments and with different types of queries.