 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack-Box Batch Active Learning for Regression
Feb 17, 2023Batch active learning is a popular approach for efficiently training machine learning models on large, initially unlabelled datasets, which repeatedly acquires labels for a batch of data points. However, many recent batch active learning methods are white-box approaches limited to differentiable parametric models: they score unlabeled points using acquisition functions based on model embeddings or first- and second-order derivatives. In this paper, we propose black-box batch active learning for regression tasks as an extension of white-box approaches. This approach is compatible with a wide range of machine learning models including regular and Bayesian deep learning models and non-differentiable models such as random forests. It is rooted in Bayesian principles and utilizes recent kernel-based approaches. Importantly, our method only relies on model predictions. This allows us to extend a wide range of existing state-of-the-art white-box batch active learning methods (BADGE, BAIT, LCMD) to black-box models. We demonstrate the effectiveness of our approach through extensive experimental evaluations on regression datasets, achieving surprisingly strong performance compared to white-box approaches for deep learning models.
Speeding Up BatchBALD: A k-BALD Family of Approximations for Active Learning
Jan 23, 2023Active learning is a powerful method for training machine learning models with limited labeled data. One commonly used technique for active learning is BatchBALD, which uses Bayesian neural networks to find the most informative points to label in a pool set. However, BatchBALD can be very slow to compute, especially for larger datasets. In this paper, we propose a new approximation, k-BALD, which uses k-wise mutual information terms to approximate BatchBALD, making it much less expensive to compute. Results on the MNIST dataset show that k-BALD is significantly faster than BatchBALD while maintaining similar performance. Additionally, we also propose a dynamic approach for choosing k based on the quality of the approximation, making it more efficient for larger datasets.
Unifying Approaches in Data Subset Selection via Fisher Information and Information-Theoretic Quantities
Aug 01, 2022The mutual information between predictions and model parameters -- also referred to as expected information gain or BALD in machine learning -- measures informativeness. It is a popular acquisition function in Bayesian active learning and Bayesian optimal experiment design. In data subset selection, i.e. active learning and active sampling, several recent works use Fisher information, Hessians, similarity matrices based on the gradients, or simply the gradient lengths to compute the acquisition scores that guide sample selection. Are these different approaches connected, and if so how? In this paper, we revisit the Fisher information and use it to show how several otherwise disparate methods are connected as approximations of information-theoretic quantities.
Plex: Towards Reliability using Pretrained Large Model Extensions
Jul 15, 2022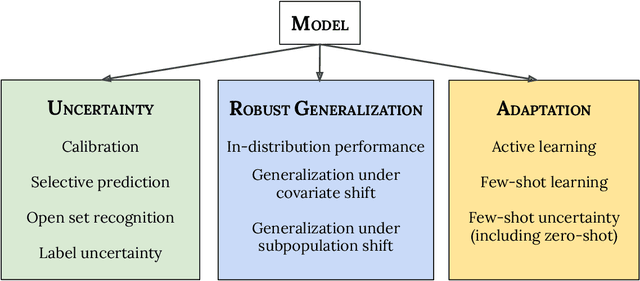

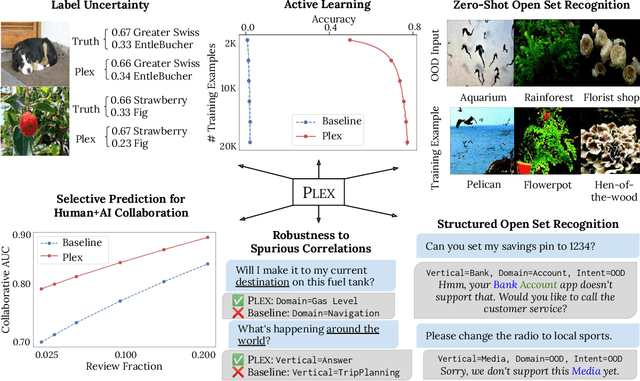

A recent trend in artificial intelligence is the use of pretrained models for language and vision tasks, which have achieved extraordinary performance but also puzzling failures. Probing these models' abilities in diverse ways is therefore critical to the field. In this paper, we explore the reliability of models, where we define a reliable model as one that not only achieves strong predictive performance but also performs well consistently over many decision-making tasks involving uncertainty (e.g., selective prediction, open set recognition), robust generalization (e.g., accuracy and proper scoring rules such as log-likelihood on in- and out-of-distribution datasets), and adaptation (e.g., active learning, few-shot uncertainty). We devise 10 types of tasks over 40 datasets in order to evaluate different aspects of reliability on both vision and language domains. To improve reliability, we developed ViT-Plex and T5-Plex, pretrained large model extensions for vision and language modalities, respectively. Plex greatly improves the state-of-the-art across reliability tasks, and simplifies the traditional protocol as it improves the out-of-the-box performance and does not require designing scores or tuning the model for each task. We demonstrate scaling effects over model sizes up to 1B parameters and pretraining dataset sizes up to 4B examples. We also demonstrate Plex's capabilities on challenging tasks including zero-shot open set recognition, active learning, and uncertainty in conversational language understanding.
Prioritized Training on Points that are Learnable, Worth Learning, and Not Yet Learnt
Jun 16, 2022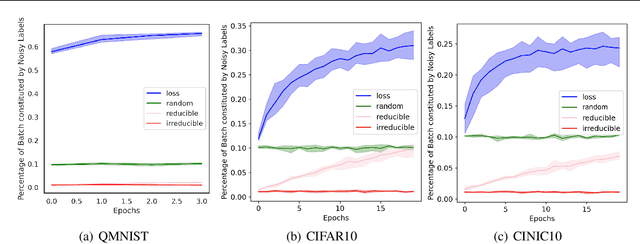
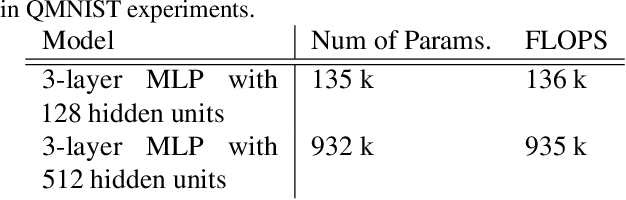
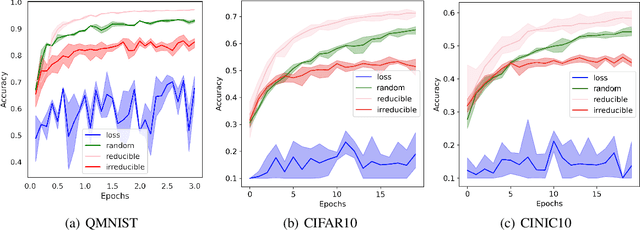
Training on web-scale data can take months. But most computation and time is wasted on redundant and noisy points that are already learnt or not learnable. To accelerate training, we introduce Reducible Holdout Loss Selection (RHO-LOSS), a simple but principled technique which selects approximately those points for training that most reduce the model's generalization loss. As a result, RHO-LOSS mitigates the weaknesses of existing data selection methods: techniques from the optimization literature typically select 'hard' (e.g. high loss) points, but such points are often noisy (not learnable) or less task-relevant. Conversely, curriculum learning prioritizes 'easy' points, but such points need not be trained on once learned. In contrast, RHO-LOSS selects points that are learnable, worth learning, and not yet learnt. RHO-LOSS trains in far fewer steps than prior art, improves accuracy, and speeds up training on a wide range of datasets, hyperparameters, and architectures (MLPs, CNNs, and BERT). On the large web-scraped image dataset Clothing-1M, RHO-LOSS trains in 18x fewer steps and reaches 2% higher final accuracy than uniform data shuffling.
Marginal and Joint Cross-Entropies & Predictives for Online Bayesian Inference, Active Learning, and Active Sampling
May 18, 2022
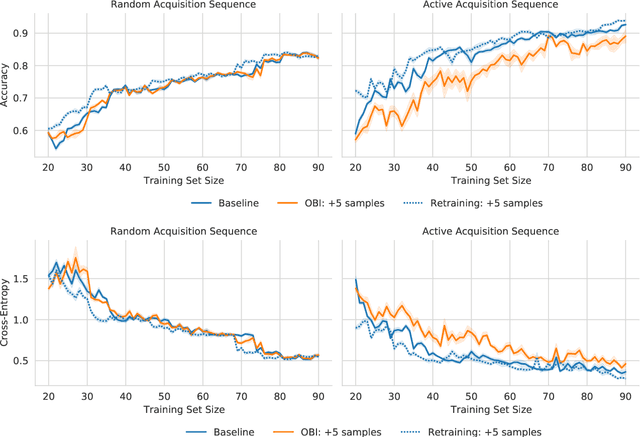
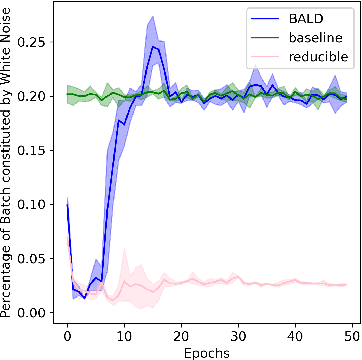
Principled Bayesian deep learning (BDL) does not live up to its potential when we only focus on marginal predictive distributions (marginal predictives). Recent works have highlighted the importance of joint predictives for (Bayesian) sequential decision making from a theoretical and synthetic perspective. We provide additional practical arguments grounded in real-world applications for focusing on joint predictives: we discuss online Bayesian inference, which would allow us to make predictions while taking into account additional data without retraining, and we propose new challenging evaluation settings using active learning and active sampling. These settings are motivated by an examination of marginal and joint predictives, their respective cross-entropies, and their place in offline and online learning. They are more realistic than previously suggested ones, building on work by Wen et al. (2021) and Osband et al. (2022), and focus on evaluating the performance of approximate BNNs in an online supervised setting. Initial experiments, however, raise questions on the feasibility of these ideas in high-dimensional parameter spaces with current BDL inference techniques, and we suggest experiments that might help shed further light on the practicality of current research for these problems. Importantly, our work highlights previously unidentified gaps in current research and the need for better approximate joint predictives.
A Note on "Assessing Generalization of SGD via Disagreement"
Feb 03, 2022Jiang et al. (2021) give empirical evidence that the average test error of deep neural networks can be estimated via the prediction disagreement of two separately trained networks. They also provide a theoretical explanation that this 'Generalization Disagreement Equality' follows from the well-calibrated nature of deep ensembles under the notion of a proposed 'class-aggregated calibration'. In this paper we show that the approach suggested might be impractical because a deep ensemble's calibration deteriorates under distribution shift, which is exactly when the coupling of test error and disagreement would be of practical value. We present both theoretical and experimental evidence, re-deriving the theoretical statements using a simple Bayesian perspective and show them to be straightforward and more generic: they apply to any discriminative model -- not only ensembles whose members output one-hot class predictions. The proposed calibration metrics are also equivalent to two metrics introduced by Nixon et al. (2019): 'ACE' and 'SCE'.
Causal-BALD: Deep Bayesian Active Learning of Outcomes to Infer Treatment-Effects from Observational Data
Nov 03, 2021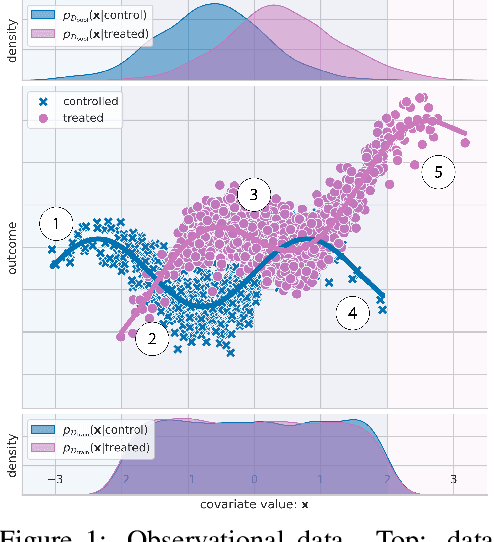
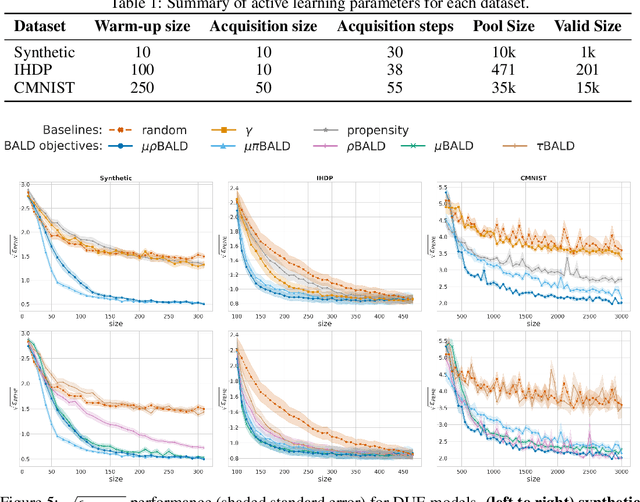
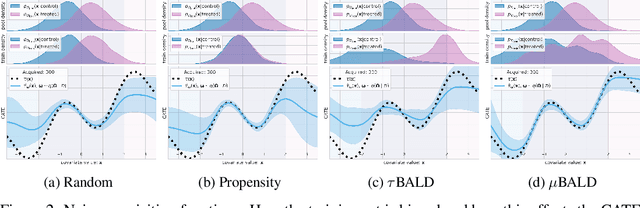

Estimating personalized treatment effects from high-dimensional observational data is essential in situations where experimental designs are infeasible, unethical, or expensive. Existing approaches rely on fitting deep models on outcomes observed for treated and control populations. However, when measuring individual outcomes is costly, as is the case of a tumor biopsy, a sample-efficient strategy for acquiring each result is required. Deep Bayesian active learning provides a framework for efficient data acquisition by selecting points with high uncertainty. However, existing methods bias training data acquisition towards regions of non-overlapping support between the treated and control populations. These are not sample-efficient because the treatment effect is not identifiable in such regions. We introduce causal, Bayesian acquisition functions grounded in information theory that bias data acquisition towards regions with overlapping support to maximize sample efficiency for learning personalized treatment effects. We demonstrate the performance of the proposed acquisition strategies on synthetic and semi-synthetic datasets IHDP and CMNIST and their extensions, which aim to simulate common dataset biases and pathologies.
Prioritized training on points that are learnable, worth learning, and not yet learned
Jul 06, 2021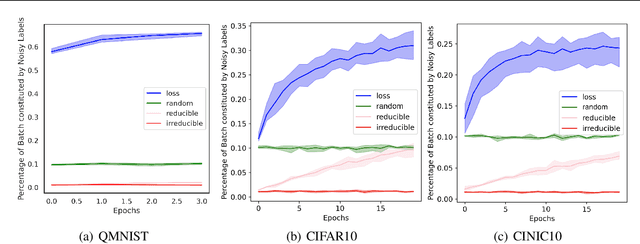
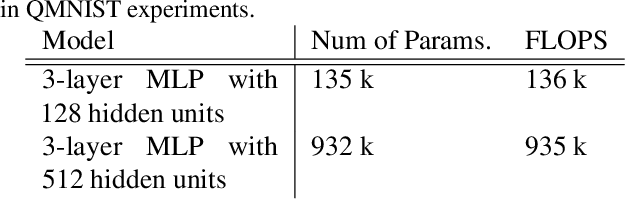
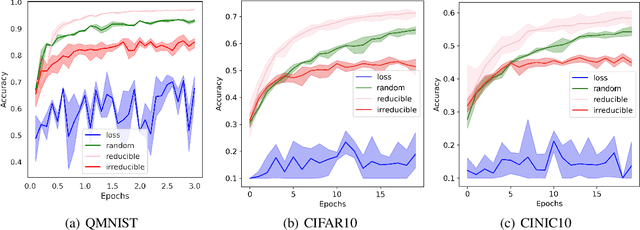
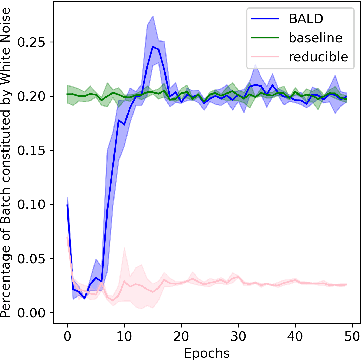
We introduce Goldilocks Selection, a technique for faster model training which selects a sequence of training points that are "just right". We propose an information-theoretic acquisition function -- the reducible validation loss -- and compute it with a small proxy model -- GoldiProx -- to efficiently choose training points that maximize information about a validation set. We show that the "hard" (e.g. high loss) points usually selected in the optimization literature are typically noisy, while the "easy" (e.g. low noise) samples often prioritized for curriculum learning confer less information. Further, points with uncertain labels, typically targeted by active learning, tend to be less relevant to the task. In contrast, Goldilocks Selection chooses points that are "just right" and empirically outperforms the above approaches. Moreover, the selected sequence can transfer to other architectures; practitioners can share and reuse it without the need to recreate it.
A Practical & Unified Notation for Information-Theoretic Quantities in ML
Jun 22, 2021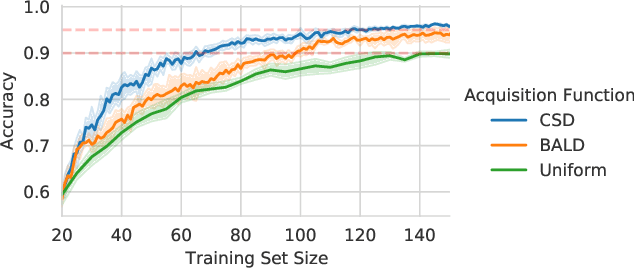

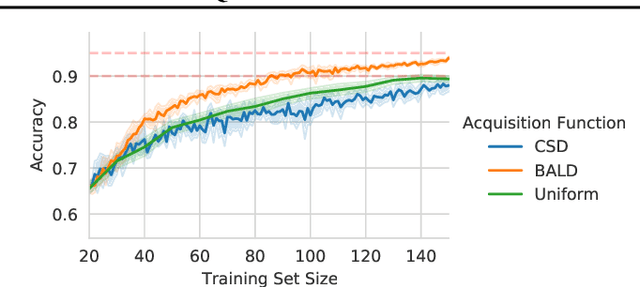
Information theory is of importance to machine learning, but the notation for information-theoretic quantities is sometimes opaque. The right notation can convey valuable intuitions and concisely express new ideas. We propose such a notation for machine learning users and expand it to include information-theoretic quantities between events (outcomes) and random variables. We apply this notation to a popular information-theoretic acquisition function in Bayesian active learning which selects the most informative (unlabelled) samples to be labelled by an expert. We demonstrate the value of our notation when extending the acquisition function to the core-set problem, which consists of selecting the most informative samples \emph{given} the labels.