 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep ROC Analysis and AUC as Balanced Average Accuracy to Improve Model Selection, Understanding and Interpretation
Mar 21, 2021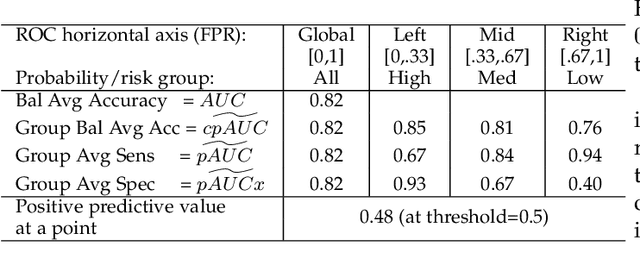
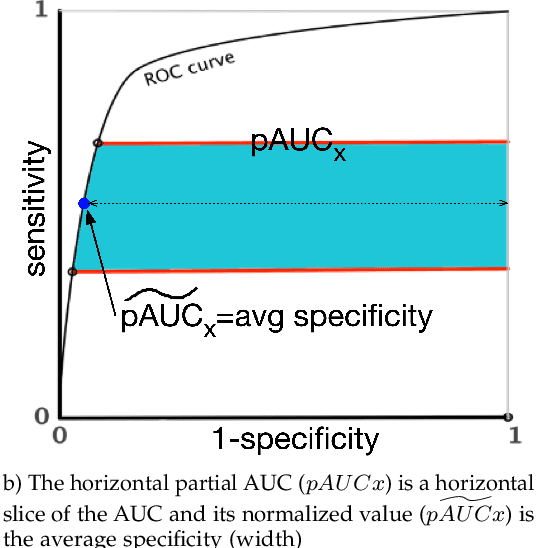
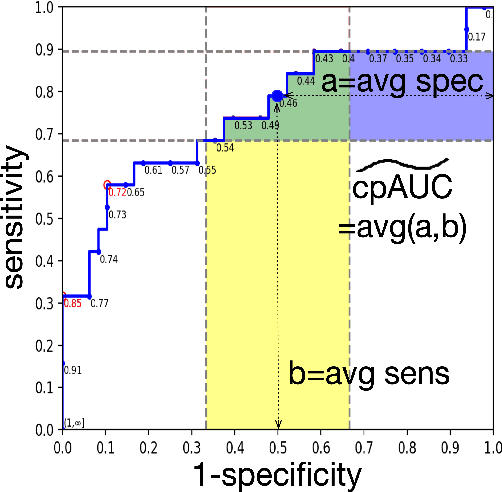
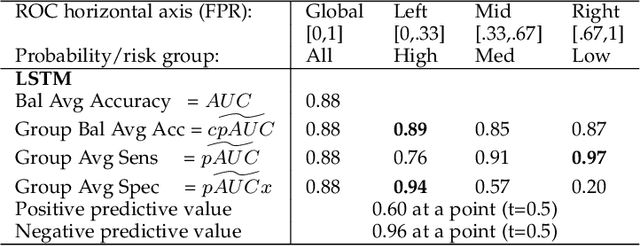
Optimal performance is critical for decision-making tasks from medicine to autonomous driving, however common performance measures may be too general or too specific. For binary classifiers, diagnostic tests or prognosis at a timepoint, measures such as the area under the receiver operating characteristic curve, or the area under the precision recall curve, are too general because they include unrealistic decision thresholds. On the other hand, measures such as accuracy, sensitivity or the F1 score are measures at a single threshold that reflect an individual single probability or predicted risk, rather than a range of individuals or risk. We propose a method in between, deep ROC analysis, that examines groups of probabilities or predicted risks for more insightful analysis. We translate esoteric measures into familiar terms: AUC and the normalized concordant partial AUC are balanced average accuracy (a new finding); the normalized partial AUC is average sensitivity; and the normalized horizontal partial AUC is average specificity. Along with post-test measures, we provide a method that can improve model selection in some cases and provide interpretation and assurance for patients in each risk group. We demonstrate deep ROC analysis in two case studies and provide a toolkit in Python.
KANDINSKYPatterns -- An experimental exploration environment for Pattern Analysis and Machine Intelligence
Feb 28, 2021Machine intelligence is very successful at standard recognition tasks when having high-quality training data. There is still a significant gap between machine-level pattern recognition and human-level concept learning. Humans can learn under uncertainty from only a few examples and generalize these concepts to solve new problems. The growing interest in explainable machine intelligence, requires experimental environments and diagnostic tests to analyze weaknesses in existing approaches to drive progress in the field. In this paper, we discuss existing diagnostic tests and test data sets such as CLEVR, CLEVERER, CLOSURE, CURI, Bongard-LOGO, V-PROM, and present our own experimental environment: The KANDINSKYPatterns, named after the Russian artist Wassily Kandinksy, who made theoretical contributions to compositivity, i.e. that all perceptions consist of geometrically elementary individual components. This was experimentally proven by Hubel &Wiesel in the 1960s and became the basis for machine learning approaches such as the Neocognitron and the even later Deep Learning. While KANDINSKYPatterns have computationally controllable properties on the one hand, bringing ground truth, they are also easily distinguishable by human observers, i.e., controlled patterns can be described by both humans and algorithms, making them another important contribution to international research in machine intelligence.
Predicting Prostate Cancer-Specific Mortality with A.I.-based Gleason Grading
Nov 25, 2020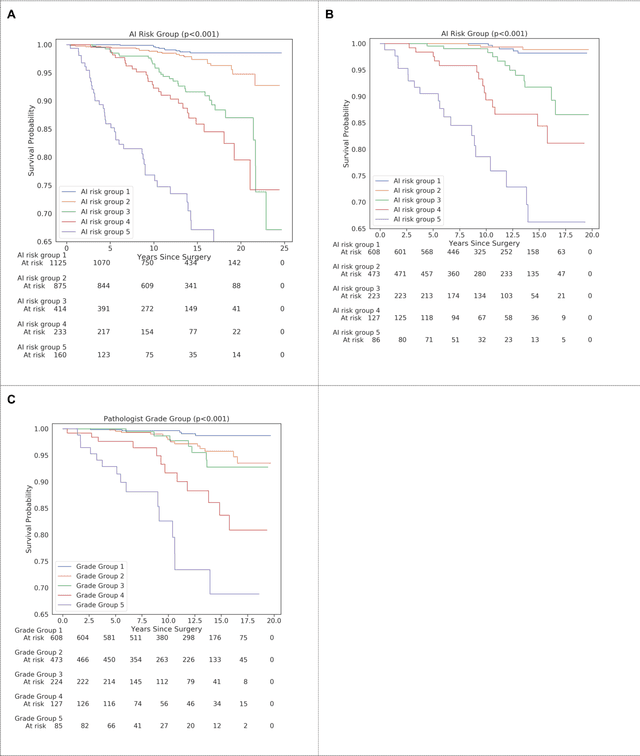
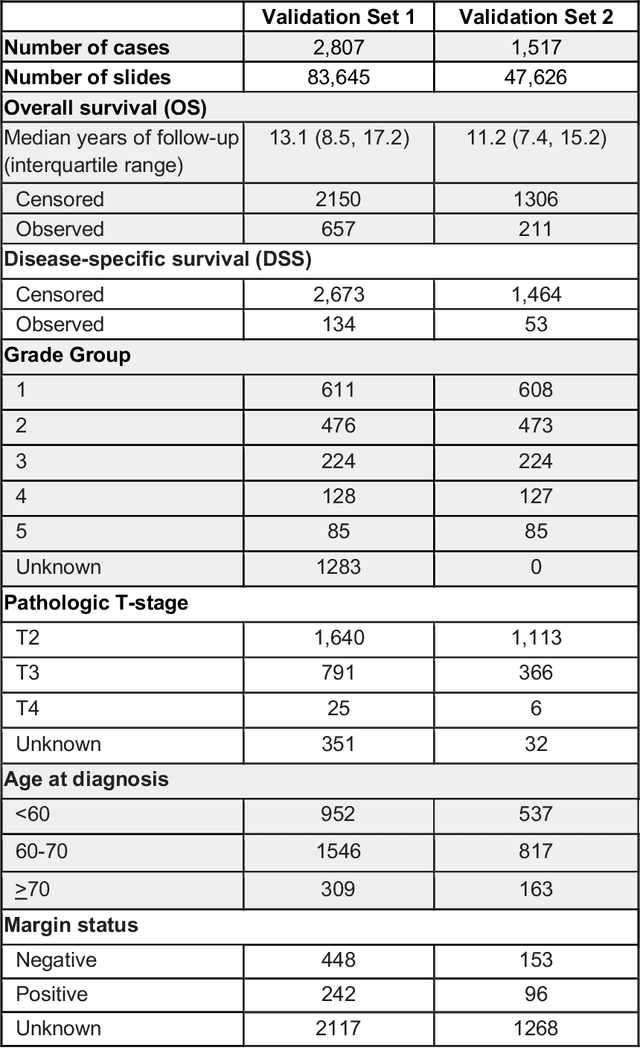
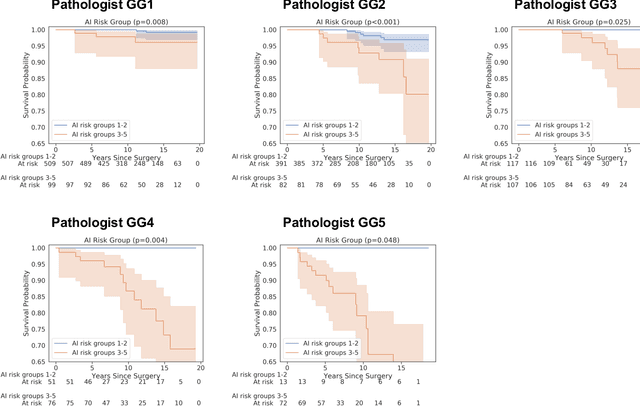
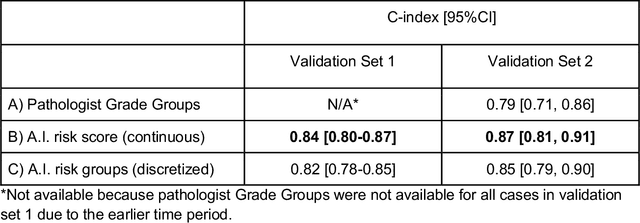
Gleason grading of prostate cancer is an important prognostic factor but suffers from poor reproducibility, particularly among non-subspecialist pathologists. Although artificial intelligence (A.I.) tools have demonstrated Gleason grading on-par with expert pathologists, it remains an open question whether A.I. grading translates to better prognostication. In this study, we developed a system to predict prostate-cancer specific mortality via A.I.-based Gleason grading and subsequently evaluated its ability to risk-stratify patients on an independent retrospective cohort of 2,807 prostatectomy cases from a single European center with 5-25 years of follow-up (median: 13, interquartile range 9-17). The A.I.'s risk scores produced a C-index of 0.84 (95%CI 0.80-0.87) for prostate cancer-specific mortality. Upon discretizing these risk scores into risk groups analogous to pathologist Grade Groups (GG), the A.I. had a C-index of 0.82 (95%CI 0.78-0.85). On the subset of cases with a GG in the original pathology report (n=1,517), the A.I.'s C-indices were 0.87 and 0.85 for continuous and discrete grading, respectively, compared to 0.79 (95%CI 0.71-0.86) for GG obtained from the reports. These represent improvements of 0.08 (95%CI 0.01-0.15) and 0.07 (95%CI 0.00-0.14) respectively. Our results suggest that A.I.-based Gleason grading can lead to effective risk-stratification and warrants further evaluation for improving disease management.
Privacy-preserving Artificial Intelligence Techniques in Biomedicine
Jul 22, 2020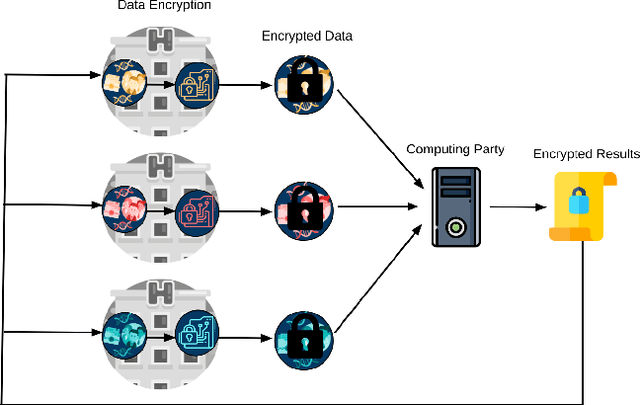
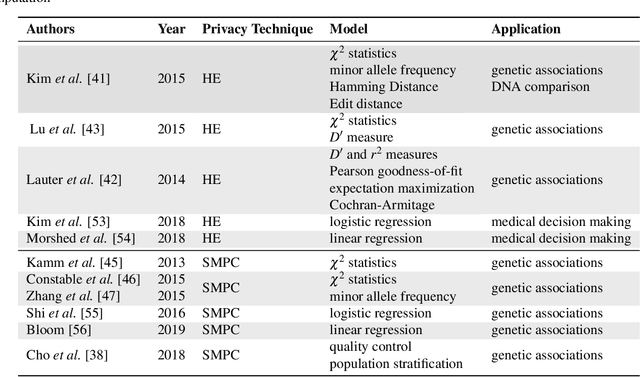
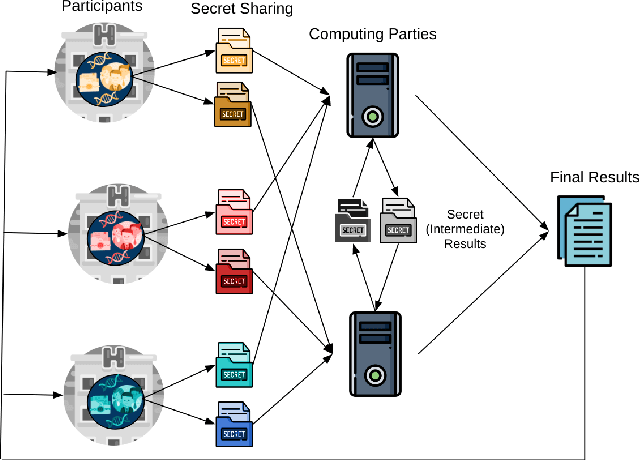
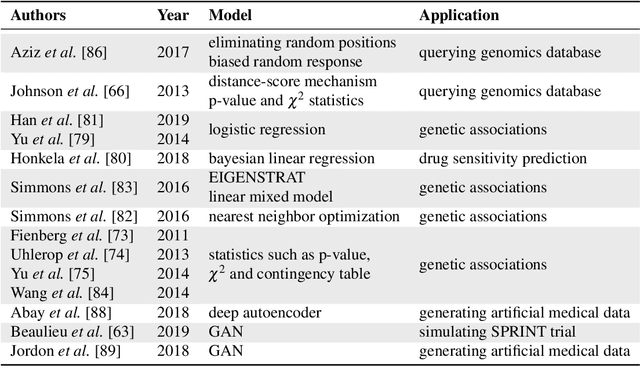
Artificial intelligence (AI) has been successfully applied in numerous scientific domains including biomedicine and healthcare. Here, it has led to several breakthroughs ranging from clinical decision support systems, image analysis to whole genome sequencing. However, training an AI model on sensitive data raises also concerns about the privacy of individual participants. Adversary AIs, for example, can abuse even summary statistics of a study to determine the presence or absence of an individual in a given dataset. This has resulted in increasing restrictions to access biomedical data, which in turn is detrimental for collaborative research and impedes scientific progress. Hence there has been an explosive growth in efforts to harness the power of AI for learning from sensitive data while protecting patients' privacy. This paper provides a structured overview of recent advances in privacy-preserving AI techniques in biomedicine. It places the most important state-of-the-art approaches within a unified taxonomy, and discusses their strengths, limitations, and open problems.
Measuring the Quality of Explanations: The System Causability Scale (SCS). Comparing Human and Machine Explanations
Dec 19, 2019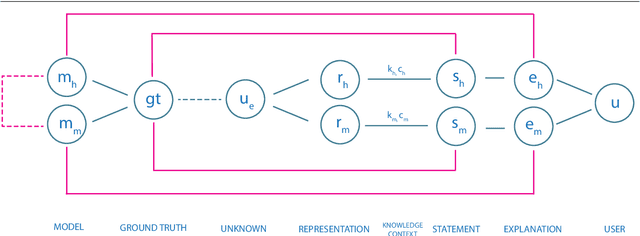
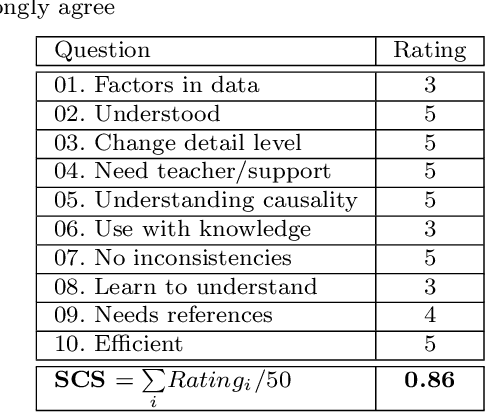
Recent success in Artificial Intelligence (AI) and Machine Learning (ML) allow problem solving automatically without any human intervention. Autonomous approaches can be very convenient. However, in certain domains, e.g., in the medical domain, it is necessary to enable a domain expert to understand, why an algorithm came up with a certain result. Consequently, the field of Explainable AI (xAI) rapidly gained interest worldwide in various domains, particularly in medicine. Explainable AI studies transparency and traceability of opaque AI/ML and there are already a huge variety of methods. For example with layer-wise relevance propagation relevant parts of inputs to, and representations in, a neural network which caused a result, can be highlighted. This is a first important step to ensure that end users, e.g., medical professionals, assume responsibility for decision making with AI/ML and of interest to professionals and regulators. Interactive ML adds the component of human expertise to AI/ML processes by enabling them to re-enact and retrace AI/ML results, e.g. let them check it for plausibility. This requires new human-AI interfaces for explainable AI. In order to build effective and efficient interactive human-AI interfaces we have to deal with the question of how to evaluate the quality of explanations given by an explainable AI system. In this paper we introduce our System Causability Scale (SCS) to measure the quality of explanations. It is based on our notion of Causability (Holzinger et al., 2019) combined with concepts adapted from a widely accepted usability scale.
Performing Arithmetic Using a Neural Network Trained on Digit Permutation Pairs
Dec 06, 2019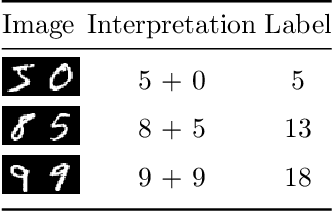

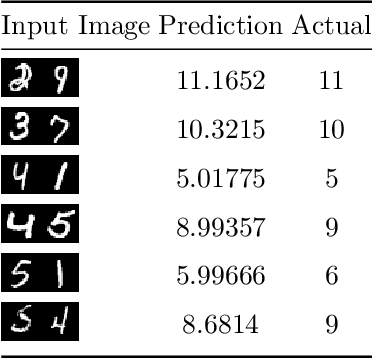
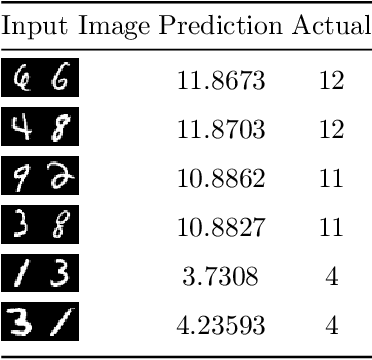
In this paper a neural network is trained to perform simple arithmetic using images of concatenated handwritten digit pairs. A convolutional neural network was trained with images consisting of two side-by-side handwritten digits, where the image's label is the summation of the two digits contained in the combined image. Crucially, the network was tested on permutation pairs that were not present during training in an effort to see if the network could learn the task of addition, as opposed to simply mapping images to labels. A dataset was generated for all possible permutation pairs of length 2 for the digits 0-9 using MNIST as a basis for the images, with one thousand samples generated for each permutation pair. For testing the network, samples generated from previously unseen permutation pairs were fed into the trained network, and its predictions measured. Results were encouraging, with the network achieving an accuracy of over 90% on some permutation train/test splits. This suggests that the network learned at first digit recognition, and subsequently the further task of addition based on the two recognised digits. As far as the authors are aware, no previous work has concentrated on learning a mathematical operation in this way.
Patch augmentation: Towards efficient decision boundaries for neural networks
Nov 25, 2019


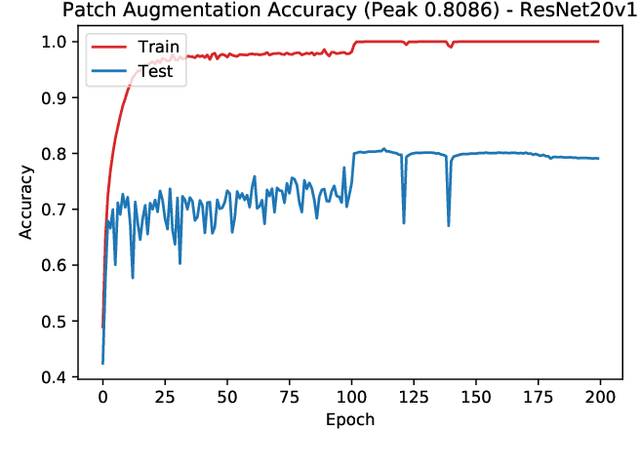
In this paper we propose a new augmentation technique, called patch augmentation, that, in our experiments, improves model accuracy and makes networks more robust to adversarial attacks. In brief, this data-independent approach creates new image data based on image/label pairs, where a patch from one of the two images in the pair is superimposed on to the other image, creating a new augmented sample. The new image's label is a linear combination of the image pair's corresponding labels. Initial experiments show a several percentage point increase in accuracy on CIFAR-10, from a baseline of approximately 81% to 89%. CIFAR-100 sees larger improvements still, from a baseline of 52% to 68% accuracy. Networks trained using patch augmentation are also more robust to adversarial attacks, which we demonstrate using the Fast Gradient Sign Method.
Kandinsky Patterns
Jun 03, 2019

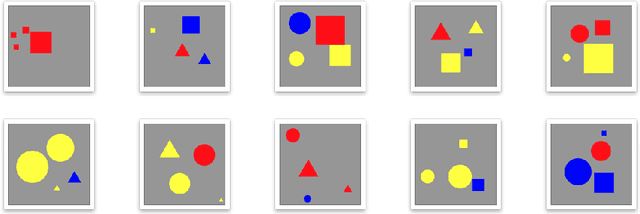
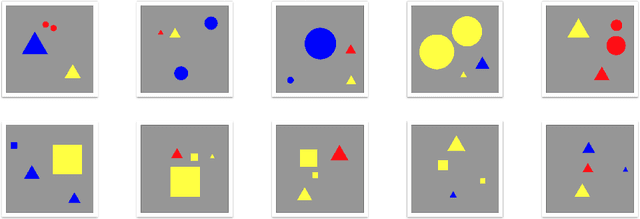
Kandinsky Figures and Kandinsky Patterns are mathematically describable, simple self-contained hence controllable test data sets for the development, validation and training of explainability in artificial intelligence. Whilst Kandinsky Patterns have these computationally manageable properties, they are at the same time easily distinguishable from human observers. Consequently, controlled patterns can be described by both humans and computers. We define a Kandinsky Pattern as a set of Kandinsky Figures, where for each figure an "infallible authority" defines that the figure belongs to the Kandinsky Pattern. With this simple principle we build training and validation data sets for automatic interpretability and context learning. In this paper we describe the basic idea and some underlying principles of Kandinsky Patterns and provide a Github repository to invite the international machine learning research community to a challenge to experiment with our Kandinsky Patterns to expand and thus make progress in the field of explainable AI and to contribute to the upcoming field of explainability and causability.
Human Activity Recognition using Recurrent Neural Networks
Apr 19, 2018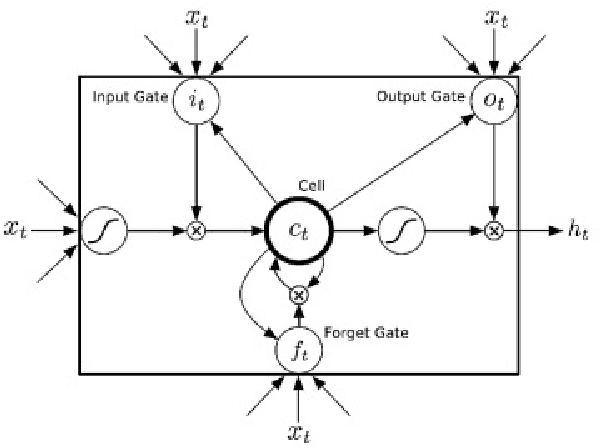
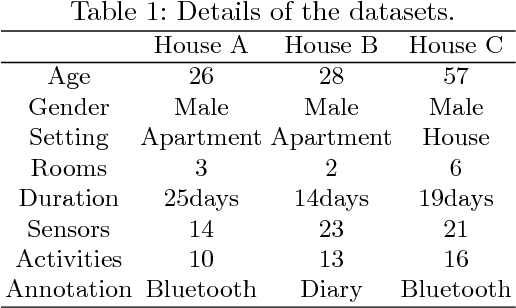
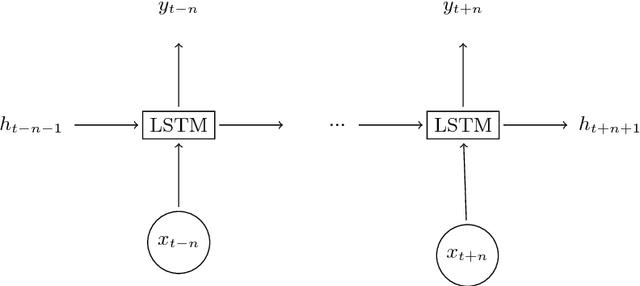
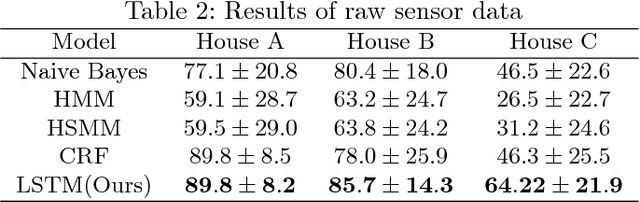
Human activity recognition using smart home sensors is one of the bases of ubiquitous computing in smart environments and a topic undergoing intense research in the field of ambient assisted living. The increasingly large amount of data sets calls for machine learning methods. In this paper, we introduce a deep learning model that learns to classify human activities without using any prior knowledge. For this purpose, a Long Short Term Memory (LSTM) Recurrent Neural Network was applied to three real world smart home datasets. The results of these experiments show that the proposed approach outperforms the existing ones in terms of accuracy and performance.
A Deep Learning Approach for Privacy Preservation in Assisted Living
Feb 22, 2018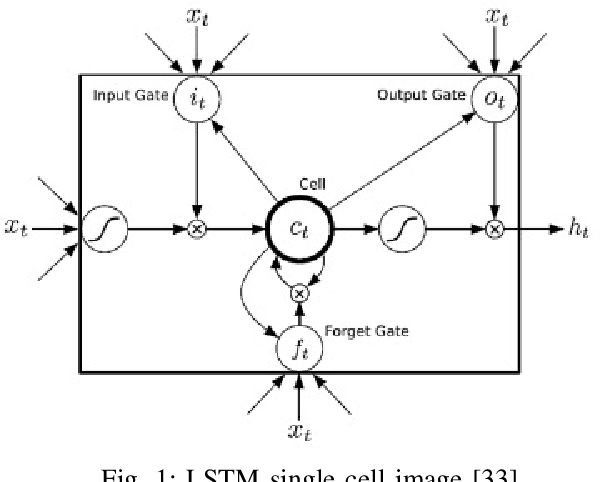
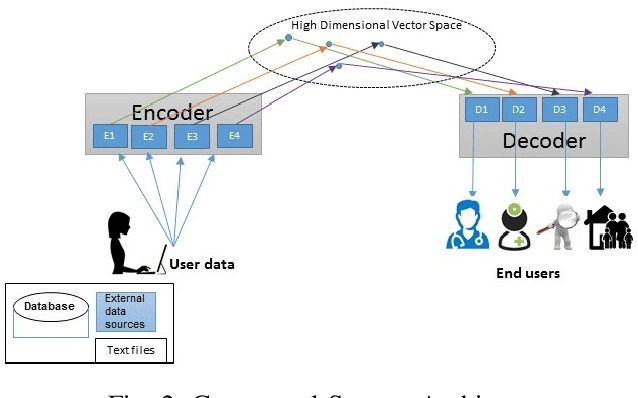
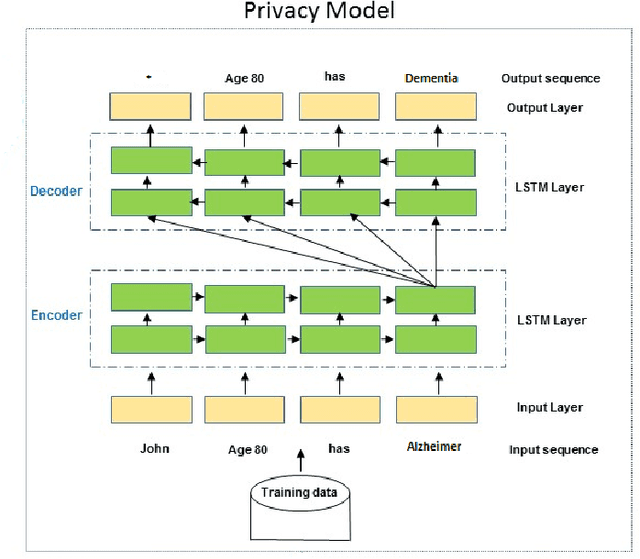
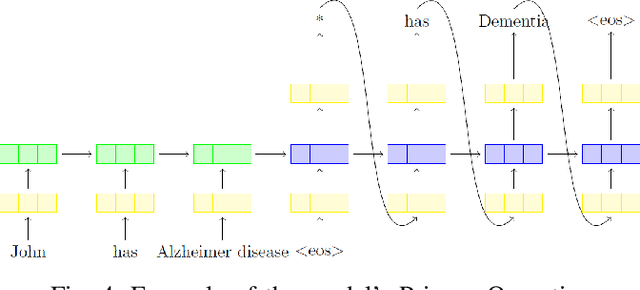
In the era of Internet of Things (IoT) technologies the potential for privacy invasion is becoming a major concern especially in regards to healthcare data and Ambient Assisted Living (AAL) environments. Systems that offer AAL technologies make extensive use of personal data in order to provide services that are context-aware and personalized. This makes privacy preservation a very important issue especially since the users are not always aware of the privacy risks they could face. A lot of progress has been made in the deep learning field, however, there has been lack of research on privacy preservation of sensitive personal data with the use of deep learning. In this paper we focus on a Long Short Term Memory (LSTM) Encoder-Decoder, which is a principal component of deep learning, and propose a new encoding technique that allows the creation of different AAL data views, depending on the access level of the end user and the information they require access to. The efficiency and effectiveness of the proposed method are demonstrated with experiments on a simulated AAL dataset. Qualitatively, we show that the proposed model learns privacy operations such as disclosure, deletion and generalization and can perform encoding and decoding of the data with almost perfect recovery.