 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuaPy: A Python-Based Framework for Quantification
Jun 18, 2021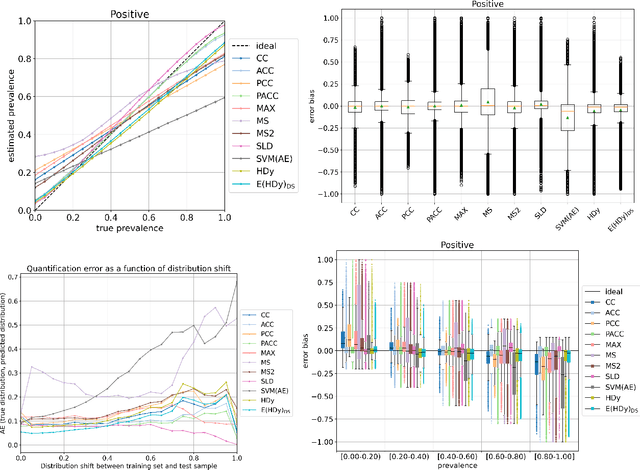
QuaPy is an open-source framework for performing quantification (a.k.a. supervised prevalence estimation), written in Python. Quantification is the task of training quantifiers via supervised learning, where a quantifier is a predictor that estimates the relative frequencies (a.k.a. prevalence values) of the classes of interest in a sample of unlabelled data. While quantification can be trivially performed by applying a standard classifier to each unlabelled data item and counting how many data items have been assigned to each class, it has been shown that this "classify and count" method is outperformed by methods specifically designed for quantification. QuaPy provides implementations of a number of baseline methods and advanced quantification methods, of routines for quantification-oriented model selection, of several broadly accepted evaluation measures, and of robust evaluation protocols routinely used in the field. QuaPy also makes available datasets commonly used for testing quantifiers, and offers visualization tools for facilitating the analysis and interpretation of the results. The software is open-source and publicly available under a BSD-3 licence via https://github.com/HLT-ISTI/QuaPy, and can be installed via pip (https://pypi.org/project/QuaPy/)
Fine-grained Visual Textual Alignment for Cross-Modal Retrieval using Transformer Encoders
Aug 12, 2020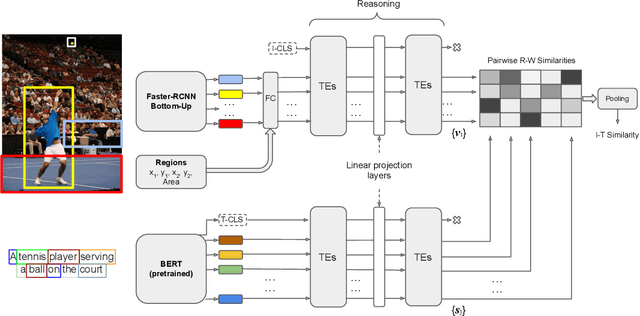
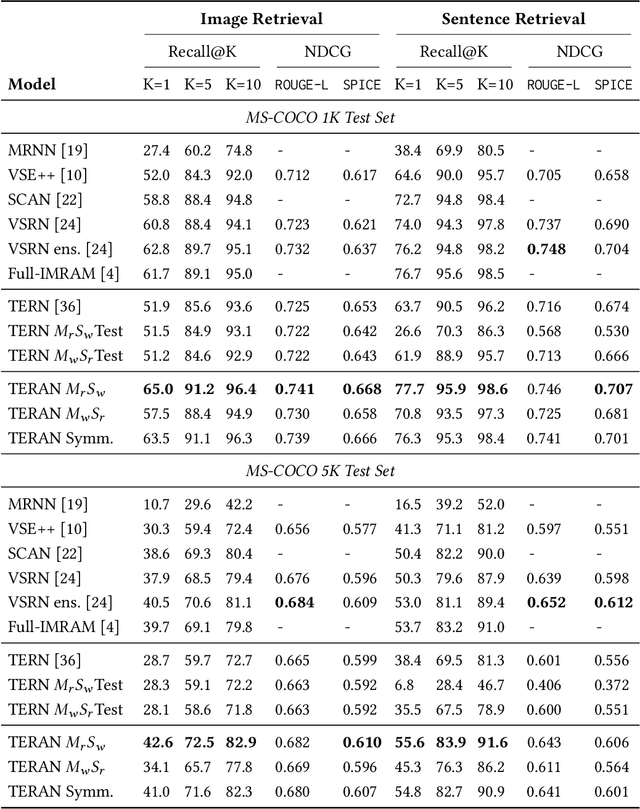
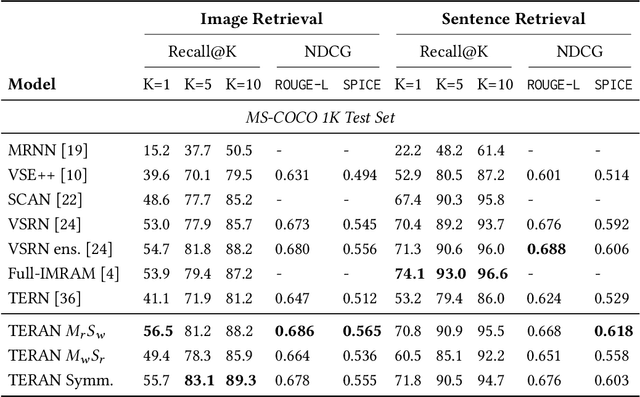

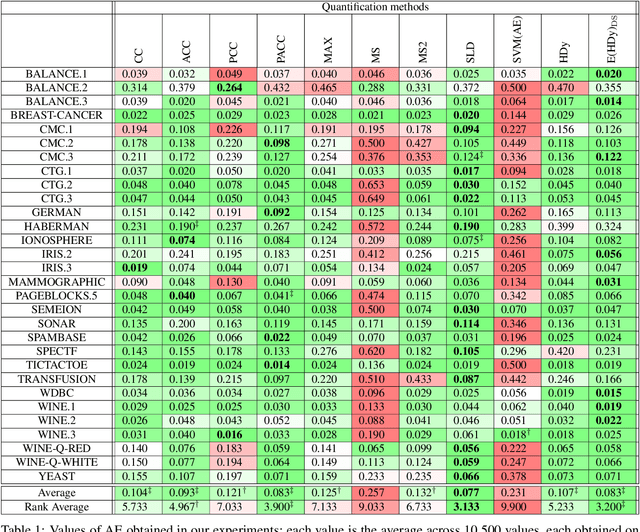
Despite the evolution of deep-learning-based visual-textual processing systems, precise multi-modal matching remains a challenging task. In this work, we tackle the problem of accurate cross-media retrieval through image-sentence matching based on word-region alignments using supervision only at the global image-sentence level. In particular, we present an approach called Transformer Encoder Reasoning and Alignment Network (TERAN). TERAN enforces a fine-grained match between the underlying components of images and sentences, i.e., image regions and words, respectively, in order to preserve the informative richness of both modalities. The proposed approach obtains state-of-the-art results on the image retrieval task on both MS-COCO and Flickr30k. Moreover, on MS-COCO, it defeats current approaches also on the sentence retrieval task. Given our long-term interest in scalable cross-modal information retrieval, TERAN is designed to keep the visual and textual data pipelines well separated. In fact, cross-attention links invalidate any chance to separately extract visual and textual features needed for the online search and the offline indexing steps in large-scale retrieval systems. In this respect, TERAN merges the information from the two domains only during the final alignment phase, immediately before the loss computation. We argue that the fine-grained alignments produced by TERAN pave the way towards the research for effective and efficient methods for large-scale cross-modal information retrieval. We compare the effectiveness of our approach against the best eight methods in this research area. On the MS-COCO 1K test set, we obtain an improvement of 3.5% and 1.2% respectively on the image and the sentence retrieval tasks on the Recall@1 metric. The code used for the experiments is publicly available on GitHub at https://github.com/mesnico/TERAN.
Transformer Reasoning Network for Image-Text Matching and Retrieval
Apr 20, 2020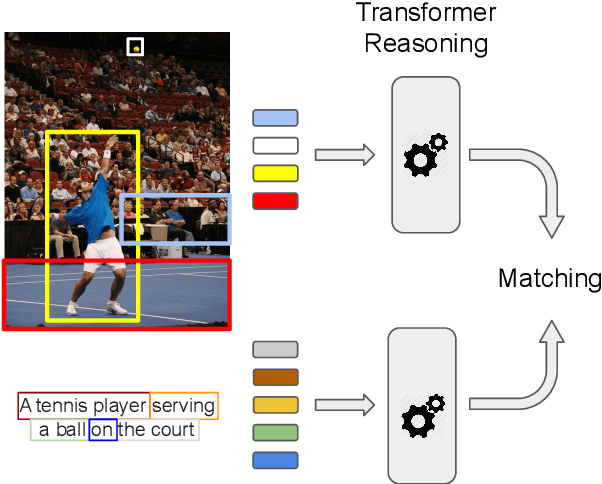
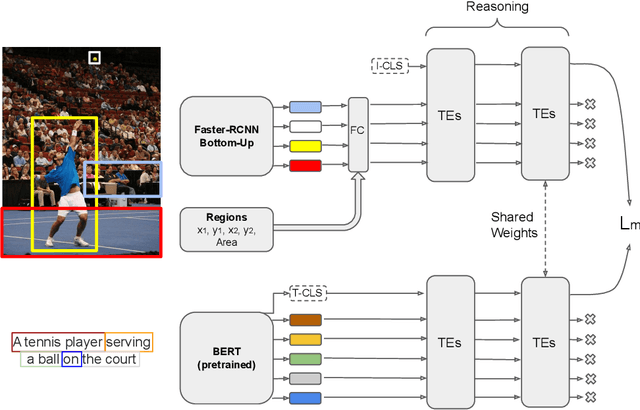

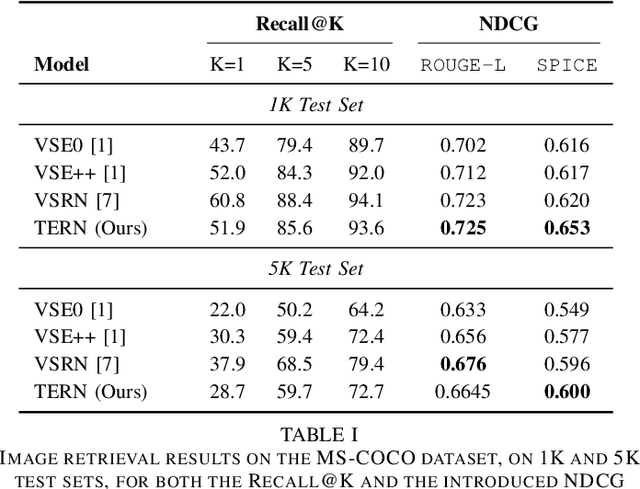
Image-text matching is an interesting and fascinating task in modern AI research. Despite the evolution of deep-learning-based image and text processing systems, multi-modal matching remains a challenging problem. In this work, we consider the problem of accurate image-text matching for the task of multi-modal large-scale information retrieval. State-of-the-art results in image-text matching are achieved by inter-playing image and text features from the two different processing pipelines, usually using mutual attention mechanisms. However, this invalidates any chance to extract separate visual and textual features needed for later indexing steps in large-scale retrieval systems. In this regard, we introduce the Transformer Encoder Reasoning Network (TERN), an architecture built upon one of the modern relationship-aware self-attentive architectures, the Transformer Encoder (TE). This architecture is able to separately reason on the two different modalities and to enforce a final common abstract concept space by sharing the weights of the deeper transformer layers. Thanks to this design, the implemented network is able to produce compact and very rich visual and textual features available for the successive indexing step. Experiments are conducted on the MS-COCO dataset, and we evaluate the results using a discounted cumulative gain metric with relevance computed exploiting caption similarities, in order to assess possibly non-exact but relevant search results. We demonstrate that on this metric we are able to achieve state-of-the-art results in the image retrieval task. Our code is freely available at https://github.com/mesnico/TERN
Word-Class Embeddings for Multiclass Text Classification
Nov 26, 2019
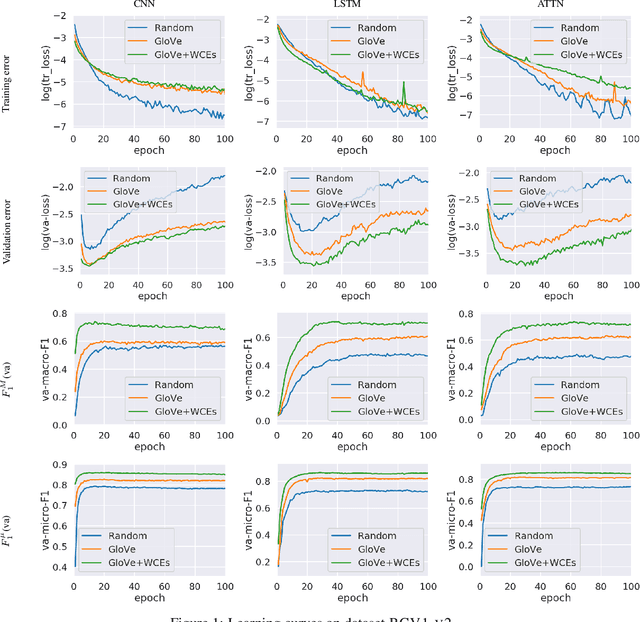
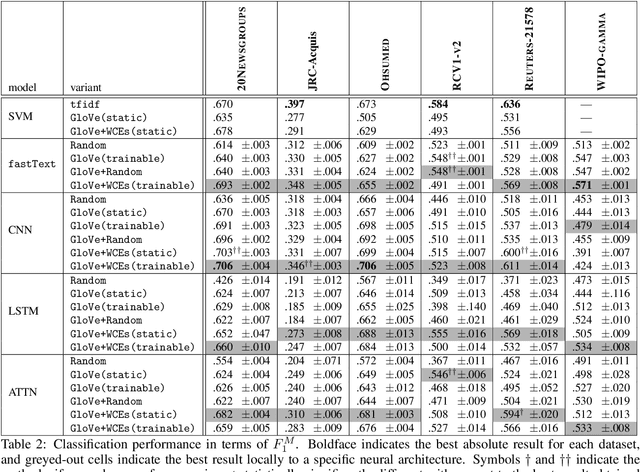
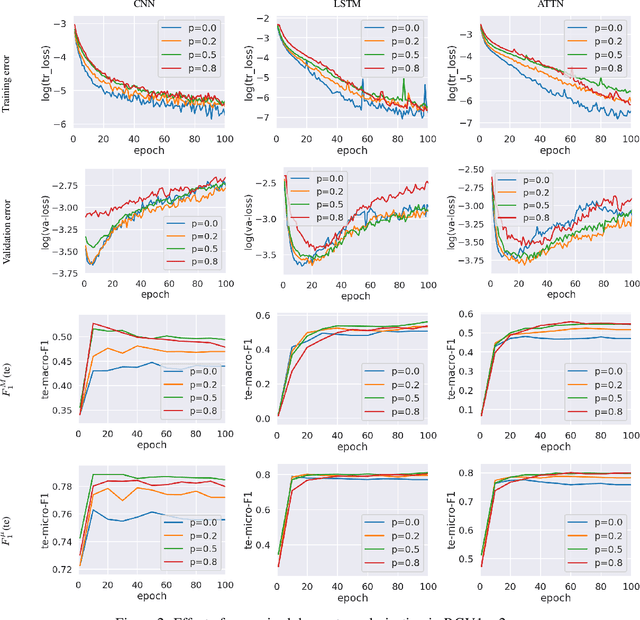
Pre-trained word embeddings encode general word semantics and lexical regularities of natural language, and have proven useful across many NLP tasks, including word sense disambiguation, machine translation, and sentiment analysis, to name a few. In supervised tasks such as multiclass text classification (the focus of this article) it seems appealing to enhance word representations with ad-hoc embeddings that encode task-specific information. We propose (supervised) word-class embeddings (WCEs), and show that, when concatenated to (unsupervised) pre-trained word embeddings, they substantially facilitate the training of deep-learning models in multiclass classification by topic. We show empirical evidence that WCEs yield a consistent improvement in multiclass classification accuracy, using four popular neural architectures and six widely used and publicly available datasets for multiclass text classification. Our code that implements WCEs is publicly available at https://github.com/AlexMoreo/word-class-embeddings
Cross-Lingual Sentiment Quantification
Apr 16, 2019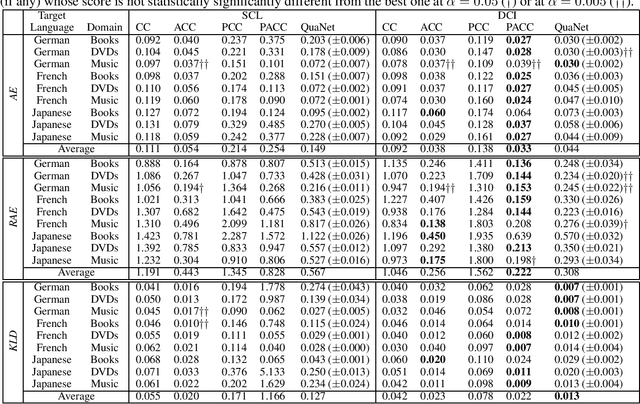
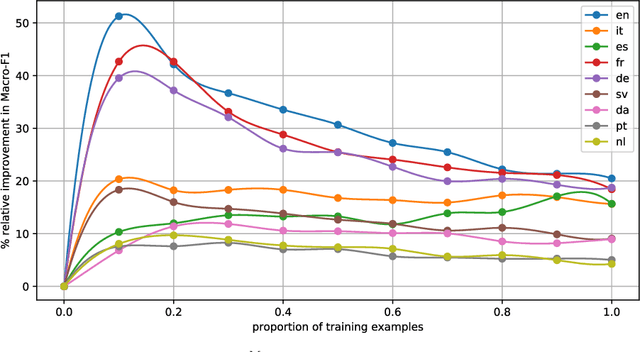
We discuss \emph{Cross-Lingual Text Quantification} (CLTQ), the task of performing text quantification (i.e., estimating the relative frequency $p_{c}(D)$ of all classes $c\in\mathcal{C}$ in a set $D$ of unlabelled documents) when training documents are available for a source language $\mathcal{S}$ but not for the target language $\mathcal{T}$ for which quantification needs to be performed. CLTQ has never been discussed before in the literature; we establish baseline results for the binary case by combining state-of-the-art quantification methods with methods capable of generating cross-lingual vectorial representations of the source and target documents involved. We present experimental results obtained on publicly available datasets for cross-lingual sentiment classification; the results show that the presented methods can perform CLTQ with a surprising level of accuracy.
Funnelling: A New Ensemble Method for Heterogeneous Transfer Learning and its Application to Cross-Lingual Text Classification
Apr 16, 2019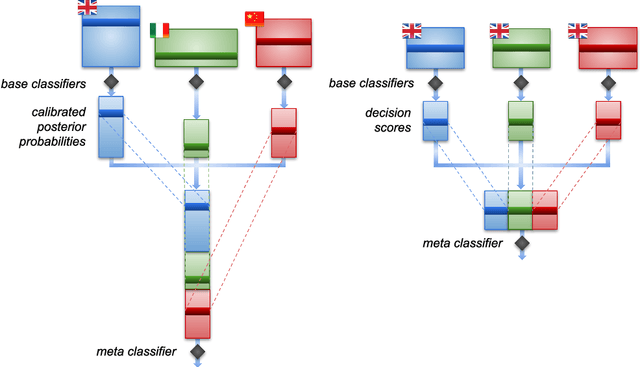
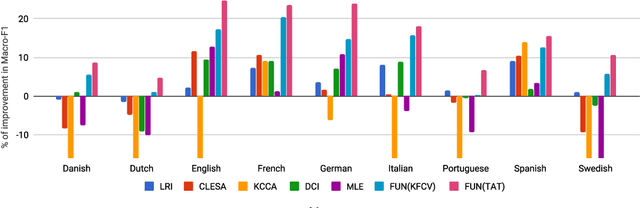
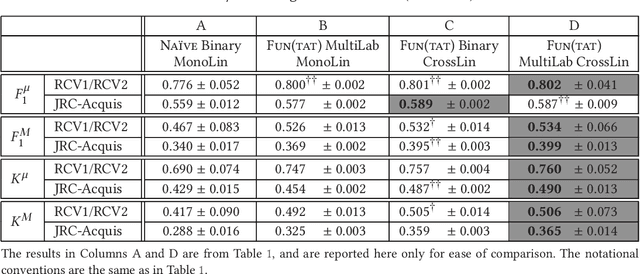
Cross-lingual Text Classification (CLC) consists of automatically classifying, according to a common set C of classes, documents each written in one of a set of languages L, and doing so more accurately than when naively classifying each document via its corresponding language-specific classifier. In order to obtain an increase in the classification accuracy for a given language, the system thus needs to also leverage the training examples written in the other languages. We tackle multilabel CLC via funnelling, a new ensemble learning method that we propose here. Funnelling consists of generating a two-tier classification system where all documents, irrespectively of language, are classified by the same (2nd-tier) classifier. For this classifier all documents are represented in a common, language-independent feature space consisting of the posterior probabilities generated by 1st-tier, language-dependent classifiers. This allows the classification of all test documents, of any language, to benefit from the information present in all training documents, of any language. We present substantial experiments, run on publicly available multilingual text collections, in which funnelling is shown to significantly outperform a number of state-of-the-art baselines. All code and datasets (in vector form) are made publicly available.
* 28 pages, 4 figures
Building Automated Survey Coders via Interactive Machine Learning
Mar 28, 2019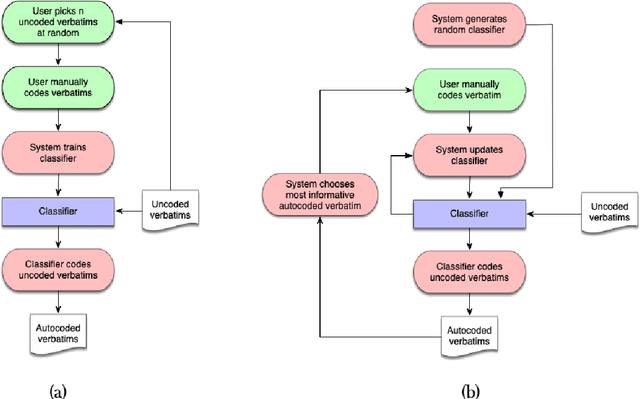
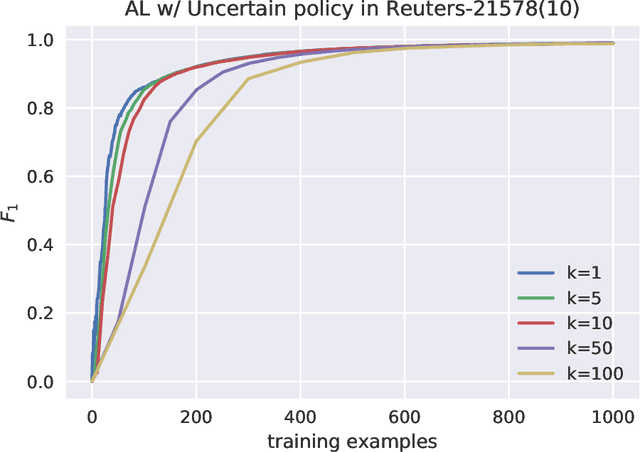
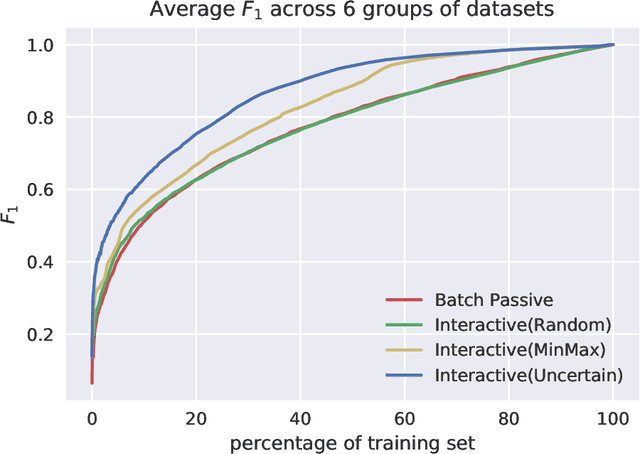
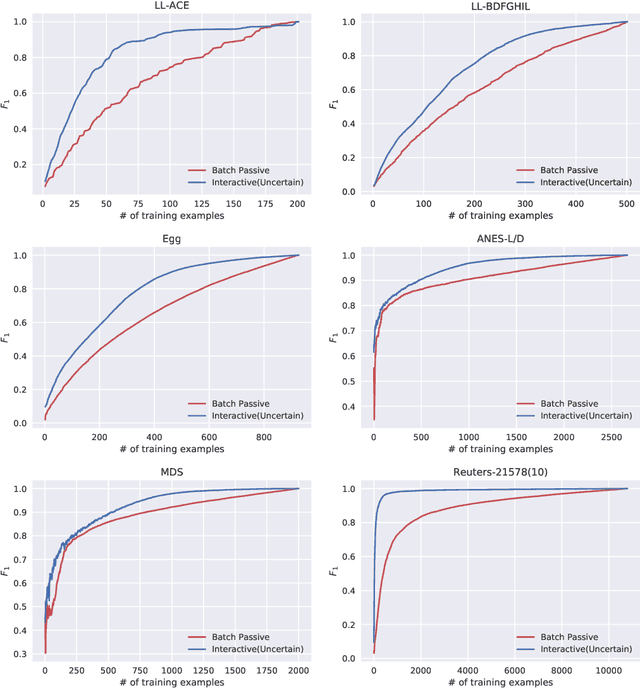
Software systems trained via machine learning to automatically classify open-ended answers (a.k.a. verbatims) are by now a reality. Still, their adoption in the survey coding industry has been less widespread than it might have been. Among the factors that have hindered a more massive takeup of this technology are the effort involved in manually coding a sufficient amount of training data, the fact that small studies do not seem to justify this effort, and the fact that the process needs to be repeated anew when brand new coding tasks arise. In this paper we will argue for an approach to building verbatim classifiers that we will call "Interactive Learning", and that addresses all the above problems. We will show that, for the same amount of training effort, interactive learning delivers much better coding accuracy than standard "non-interactive" learning. This is especially true when the amount of data we are willing to manually code is small, which makes this approach attractive also for small-scale studies. Interactive learning also lends itself to reusing previously trained classifiers for dealing with new (albeit related) coding tasks. Interactive learning also integrates better in the daily workflow of the survey specialist, and delivers a better user experience overall.
Learning to Weight for Text Classification
Mar 28, 2019
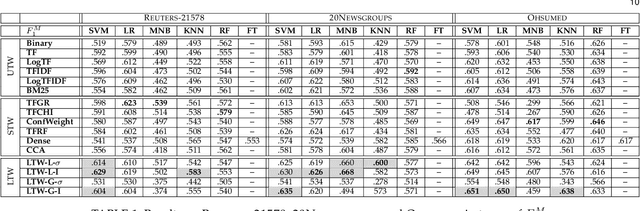

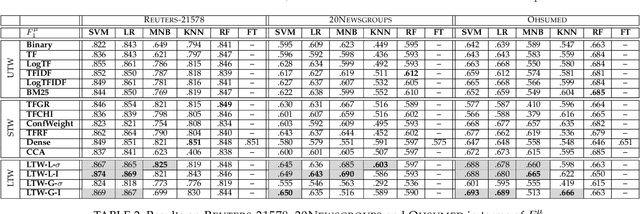
In information retrieval (IR) and related tasks, term weighting approaches typically consider the frequency of the term in the document and in the collection in order to compute a score reflecting the importance of the term for the document. In tasks characterized by the presence of training data (such as text classification) it seems logical that the term weighting function should take into account the distribution (as estimated from training data) of the term across the classes of interest. Although `supervised term weighting' approaches that use this intuition have been described before, they have failed to show consistent improvements. In this article we analyse the possible reasons for this failure, and call consolidated assumptions into question. Following this criticism we propose a novel supervised term weighting approach that, instead of relying on any predefined formula, learns a term weighting function optimised on the training set of interest; we dub this approach \emph{Learning to Weight} (LTW). The experiments that we run on several well-known benchmarks, and using different learning methods, show that our method outperforms previous term weighting approaches in text classification.
Revisiting Distributional Correspondence Indexing: A Python Reimplementation and New Experiments
Oct 19, 2018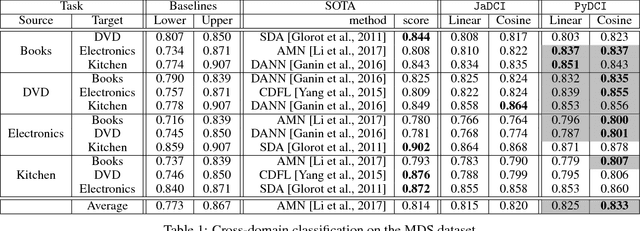
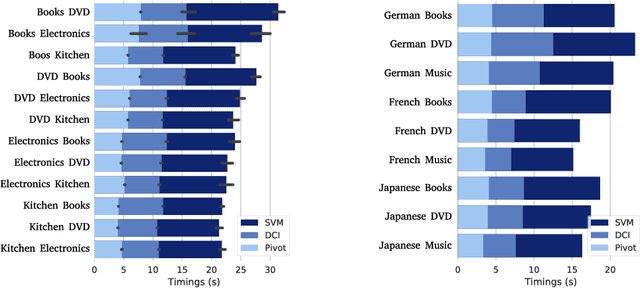
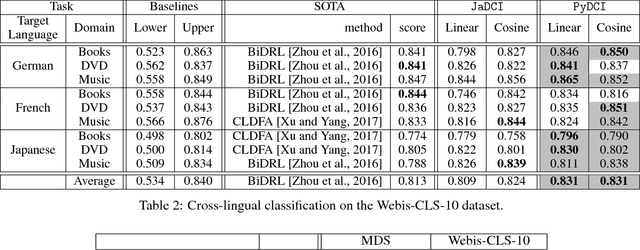
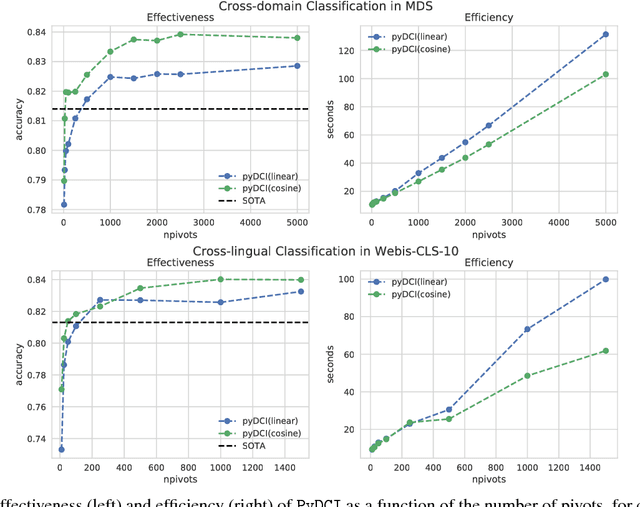
This paper introduces PyDCI, a new implementation of Distributional Correspondence Indexing (DCI) written in Python. DCI is a transfer learning method for cross-domain and cross-lingual text classification for which we had provided an implementation (here called JaDCI) built on top of JaTeCS, a Java framework for text classification. PyDCI is a stand-alone version of DCI that exploits scikit-learn and the SciPy stack. We here report on new experiments that we have carried out in order to test PyDCI, and in which we use as baselines new high-performing methods that have appeared after DCI was originally proposed. These experiments show that, thanks to a few subtle ways in which we have improved DCI, PyDCI outperforms both JaDCI and the above-mentioned high-performing methods, and delivers the best known results on the two popular benchmarks on which we had tested DCI, i.e., MultiDomainSentiment (a.k.a. MDS -- for cross-domain adaptation) and Webis-CLS-10 (for cross-lingual adaptation). PyDCI, together with the code allowing to replicate our experiments, is available at https://github.com/AlexMoreo/pydci .
A Recurrent Neural Network for Sentiment Quantification
Sep 04, 2018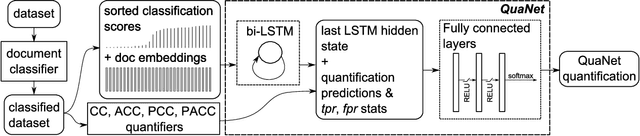
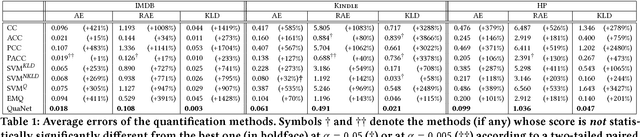
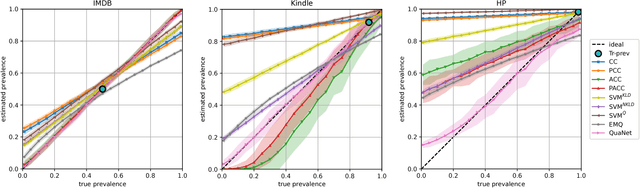
Quantification is a supervised learning task that consists in predicting, given a set of classes C and a set D of unlabelled items, the prevalence (or relative frequency) p(c|D) of each class c in C. Quantification can in principle be solved by classifying all the unlabelled items and counting how many of them have been attributed to each class. However, this "classify and count" approach has been shown to yield suboptimal quantification accuracy; this has established quantification as a task of its own, and given rise to a number of methods specifically devised for it. We propose a recurrent neural network architecture for quantification (that we call QuaNet) that observes the classification predictions to learn higher-order "quantification embeddings", which are then refined by incorporating quantification predictions of simple classify-and-count-like methods. We test {QuaNet on sentiment quantification on text, showing that it substantially outperforms several state-of-the-art baselines.