 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunnelling: A New Ensemble Method for Heterogeneous Transfer Learning and its Application to Cross-Lingual Text Classification
Paper and Code
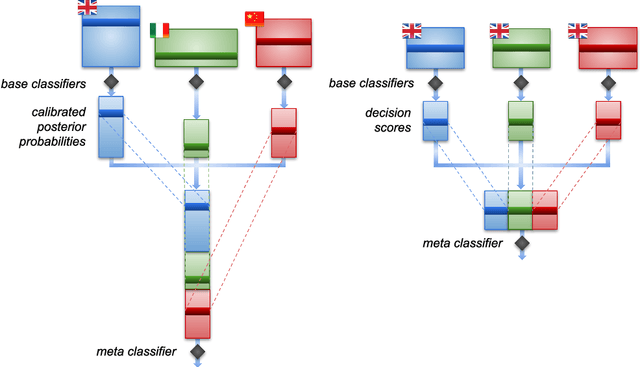
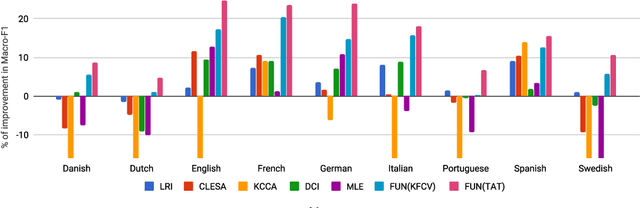
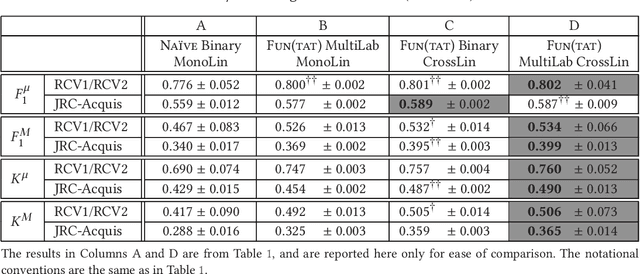
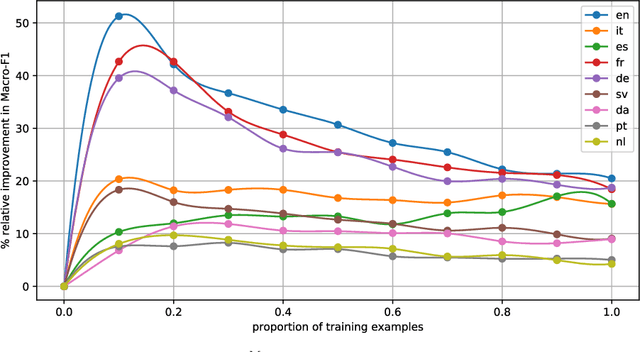
Cross-lingual Text Classification (CLC) consists of automatically classifying, according to a common set C of classes, documents each written in one of a set of languages L, and doing so more accurately than when naively classifying each document via its corresponding language-specific classifier. In order to obtain an increase in the classification accuracy for a given language, the system thus needs to also leverage the training examples written in the other languages. We tackle multilabel CLC via funnelling, a new ensemble learning method that we propose here. Funnelling consists of generating a two-tier classification system where all documents, irrespectively of language, are classified by the same (2nd-tier) classifier. For this classifier all documents are represented in a common, language-independent feature space consisting of the posterior probabilities generated by 1st-tier, language-dependent classifiers. This allows the classification of all test documents, of any language, to benefit from the information present in all training documents, of any language. We present substantial experiments, run on publicly available multilingual text collections, in which funnelling is shown to significantly outperform a number of state-of-the-art baselines. All code and datasets (in vector form) are made publicly available.