 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Lingual Sentiment Quantification
Paper and Code
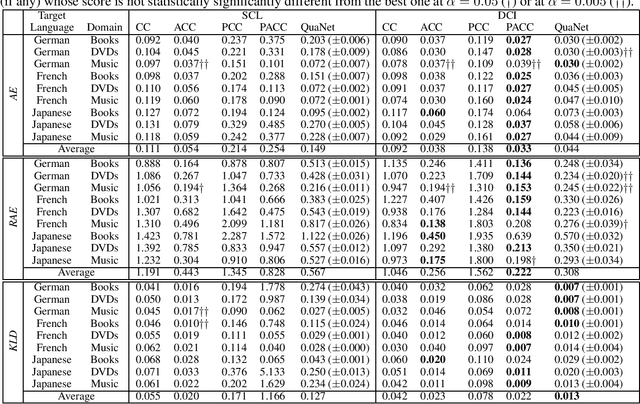
We discuss \emph{Cross-Lingual Text Quantification} (CLTQ), the task of performing text quantification (i.e., estimating the relative frequency $p_{c}(D)$ of all classes $c\in\mathcal{C}$ in a set $D$ of unlabelled documents) when training documents are available for a source language $\mathcal{S}$ but not for the target language $\mathcal{T}$ for which quantification needs to be performed. CLTQ has never been discussed before in the literature; we establish baseline results for the binary case by combining state-of-the-art quantification methods with methods capable of generating cross-lingual vectorial representations of the source and target documents involved. We present experimental results obtained on publicly available datasets for cross-lingual sentiment classification; the results show that the presented methods can perform CLTQ with a surprising level of accuracy.