 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Automated Survey Coders via Interactive Machine Learning
Paper and Code
Mar 28, 2019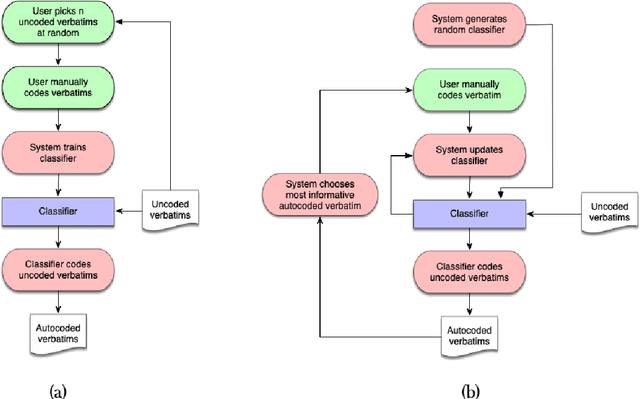
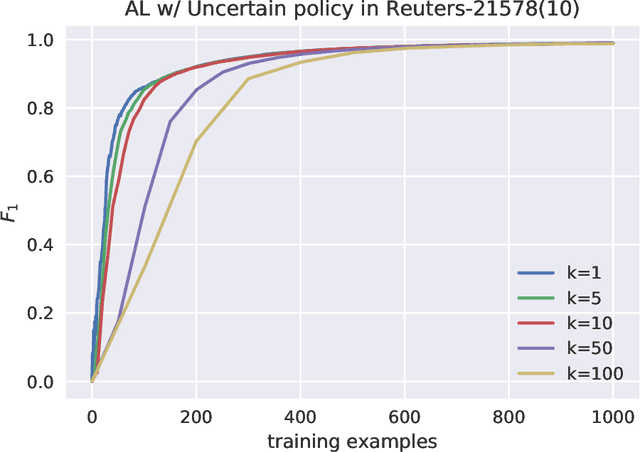
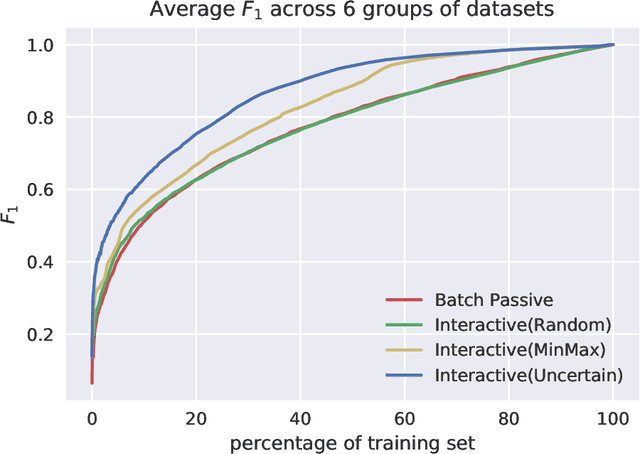
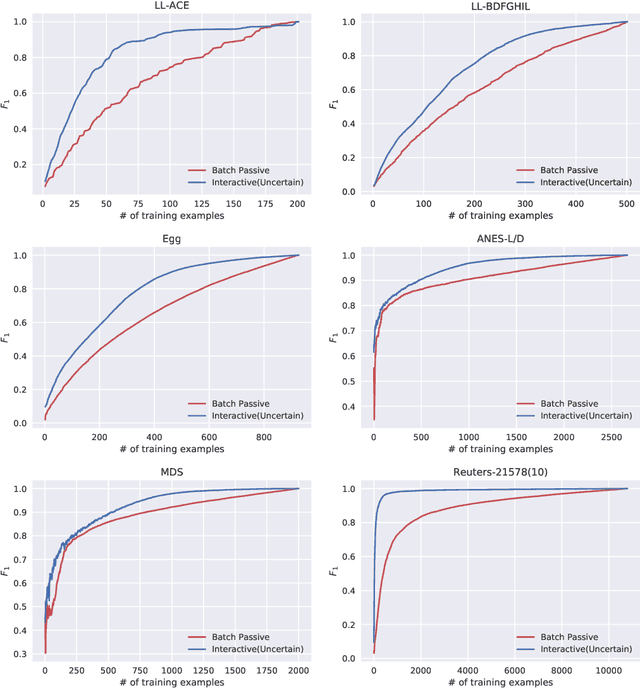
Software systems trained via machine learning to automatically classify open-ended answers (a.k.a. verbatims) are by now a reality. Still, their adoption in the survey coding industry has been less widespread than it might have been. Among the factors that have hindered a more massive takeup of this technology are the effort involved in manually coding a sufficient amount of training data, the fact that small studies do not seem to justify this effort, and the fact that the process needs to be repeated anew when brand new coding tasks arise. In this paper we will argue for an approach to building verbatim classifiers that we will call "Interactive Learning", and that addresses all the above problems. We will show that, for the same amount of training effort, interactive learning delivers much better coding accuracy than standard "non-interactive" learning. This is especially true when the amount of data we are willing to manually code is small, which makes this approach attractive also for small-scale studies. Interactive learning also lends itself to reusing previously trained classifiers for dealing with new (albeit related) coding tasks. Interactive learning also integrates better in the daily workflow of the survey specialist, and delivers a better user experience overall.