 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Dynamic Online Selection through Online Contention Resolution Schemes
Jan 08, 2023
We study fully dynamic online selection problems in an adversarial/stochastic setting that includes Bayesian online selection, prophet inequalities, posted price mechanisms, and stochastic probing problems subject to combinatorial constraints. In the classical ``incremental'' version of the problem, selected elements remain active until the end of the input sequence. On the other hand, in the fully dynamic version of the problem, elements stay active for a limited time interval, and then leave. This models, for example, the online matching of tasks to workers with task/worker-dependent working times, and sequential posted pricing of perishable goods. A successful approach to online selection problems in the adversarial setting is given by the notion of Online Contention Resolution Scheme (OCRS), that uses a priori information to formulate a linear relaxation of the underlying optimization problem, whose optimal fractional solution is rounded online for any adversarial order of the input sequence. Our main contribution is providing a general method for constructing an OCRS for fully dynamic online selection problems. Then, we show how to employ such OCRS to construct no-regret algorithms in a partial information model with semi-bandit feedback and adversarial inputs.
A Unifying Framework for Online Optimization with Long-Term Constraints
Sep 15, 2022
We study online learning problems in which a decision maker has to take a sequence of decisions subject to $m$ long-term constraints. The goal of the decision maker is to maximize their total reward, while at the same time achieving small cumulative constraints violation across the $T$ rounds. We present the first best-of-both-world type algorithm for this general class of problems, with no-regret guarantees both in the case in which rewards and constraints are selected according to an unknown stochastic model, and in the case in which they are selected at each round by an adversary. Our algorithm is the first to provide guarantees in the adversarial setting with respect to the optimal fixed strategy that satisfies the long-term constraints. In particular, it guarantees a $\rho/(1+\rho)$ fraction of the optimal reward and sublinear regret, where $\rho$ is a feasibility parameter related to the existence of strictly feasible solutions. Our framework employs traditional regret minimizers as black-box components. Therefore, by instantiating it with an appropriate choice of regret minimizers it can handle the full-feedback as well as the bandit-feedback setting. Moreover, it allows the decision maker to seamlessly handle scenarios with non-convex rewards and constraints. We show how our framework can be applied in the context of budget-management mechanisms for repeated auctions in order to guarantee long-term constraints that are not packing (e.g., ROI constraints).
Optimal Correlated Equilibria in General-Sum Extensive-Form Games: Fixed-Parameter Algorithms, Hardness, and Two-Sided Column-Generation
Mar 14, 2022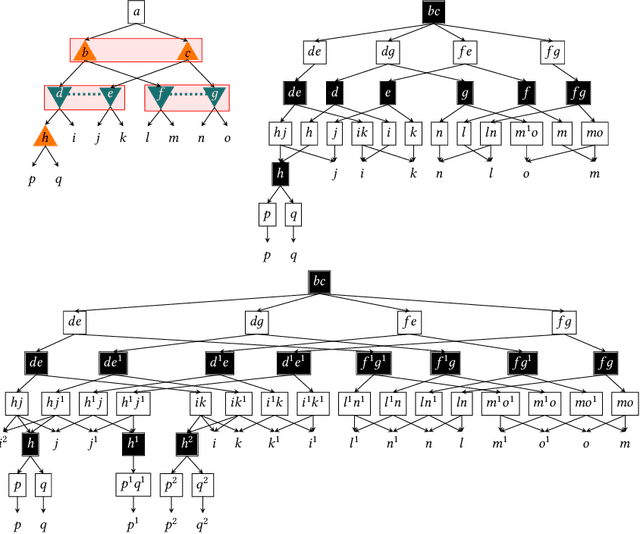
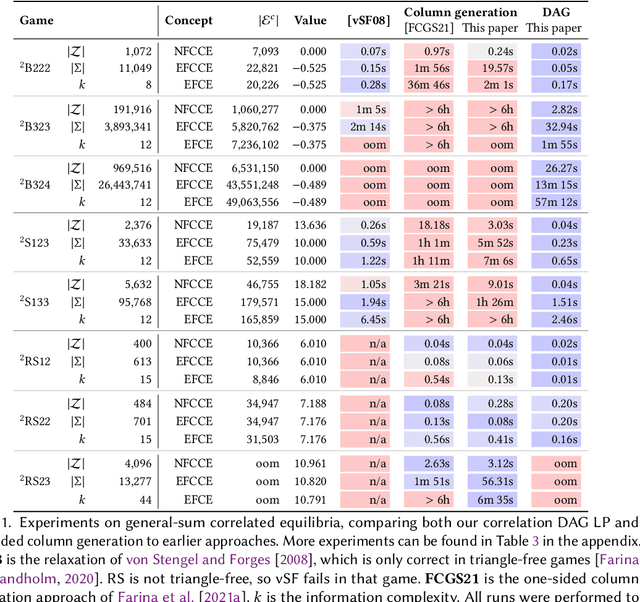
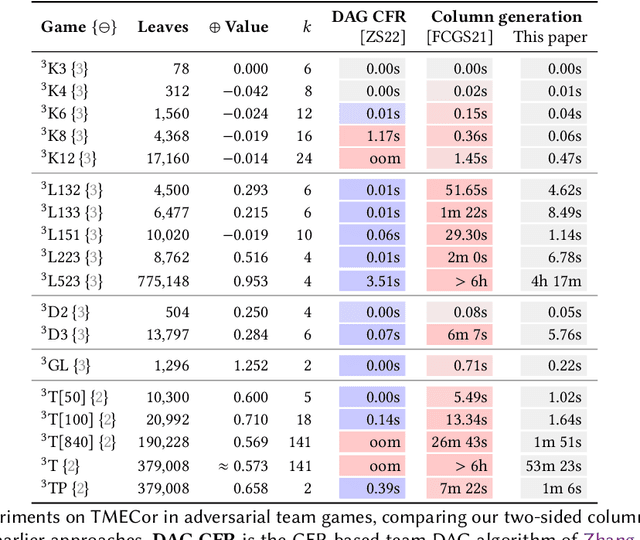
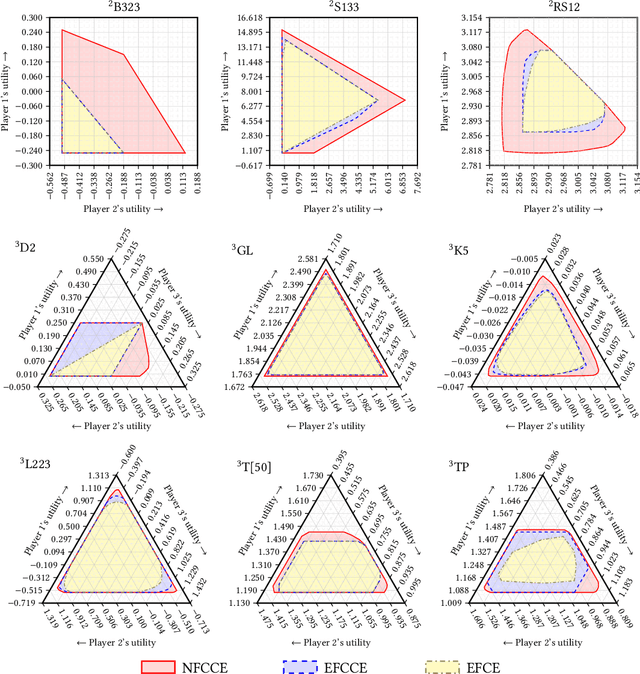
We study the problem of finding optimal correlated equilibria of various sorts: normal-form coarse correlated equilibrium (NFCCE), extensive-form coarse correlated equilibrium (EFCCE), and extensive-form correlated equilibrium (EFCE). This is NP-hard in the general case and has been studied in special cases, most notably triangle-free games, which include all two-player games with public chance moves. However, the general case is not well understood, and algorithms usually scale poorly. First, we introduce the correlation DAG, a representation of the space of correlated strategies whose size is dependent on the specific solution concept. It extends the team belief DAG of Zhang et al. to general-sum games. For each of the three solution concepts, its size depends exponentially only on a parameter related to the game's information structure. We also prove a fundamental complexity gap: while our size bounds for NFCCE are similar to those achieved in the case of team games by Zhang et al., this is impossible to achieve for the other two concepts under standard complexity assumptions. Second, we propose a two-sided column generation approach to compute optimal correlated strategies. Our algorithm improves upon the one-sided approach of Farina et al. by means of a new decomposition of correlated strategies which allows players to re-optimize their sequence-form strategies with respect to correlation plans which were previously added to the support. Our techniques outperform the prior state of the art for computing optimal general-sum correlated equilibria. For team games, the two-sided column generation approach vastly outperforms standard column generation approaches, making it the state of the art algorithm when the parameter is large. Along the way we also introduce two new benchmark games: a trick-taking game that emulates the endgame phase of the card game bridge, and a ride-sharing game.
Online Learning with Knapsacks: the Best of Both Worlds
Feb 28, 2022
We study online learning problems in which a decision maker wants to maximize their expected reward without violating a finite set of $m$ resource constraints. By casting the learning process over a suitably defined space of strategy mixtures, we recover strong duality on a Lagrangian relaxation of the underlying optimization problem, even for general settings with non-convex reward and resource-consumption functions. Then, we provide the first best-of-both-worlds type framework for this setting, with no-regret guarantees both under stochastic and adversarial inputs. Our framework yields the same regret guarantees of prior work in the stochastic case. On the other hand, when budgets grow at least linearly in the time horizon, it allows us to provide a constant competitive ratio in the adversarial case, which improves over the $O(m \log T)$ competitive ratio of Immorlica at al. (2019). Moreover, our framework allows the decision maker to handle non-convex reward and cost functions. We provide two game-theoretic applications of our framework to give further evidence of its flexibility.
Multi-Receiver Online Bayesian Persuasion
Jun 11, 2021Bayesian persuasion studies how an informed sender should partially disclose information to influence the behavior of a self-interested receiver. Classical models make the stringent assumption that the sender knows the receiver's utility. This can be relaxed by considering an online learning framework in which the sender repeatedly faces a receiver of an unknown, adversarially selected type. We study, for the first time, an online Bayesian persuasion setting with multiple receivers. We focus on the case with no externalities and binary actions, as customary in offline models. Our goal is to design no-regret algorithms for the sender with polynomial per-iteration running time. First, we prove a negative result: for any $0 < \alpha \leq 1$, there is no polynomial-time no-$\alpha$-regret algorithm when the sender's utility function is supermodular or anonymous. Then, we focus on the case of submodular sender's utility functions and we show that, in this case, it is possible to design a polynomial-time no-$(1 - \frac{1}{e})$-regret algorithm. To do so, we introduce a general online gradient descent scheme to handle online learning problems with a finite number of possible loss functions. This requires the existence of an approximate projection oracle. We show that, in our setting, there exists one such projection oracle which can be implemented in polynomial time.
Simple Uncoupled No-Regret Learning Dynamics for Extensive-Form Correlated Equilibrium
Apr 04, 2021
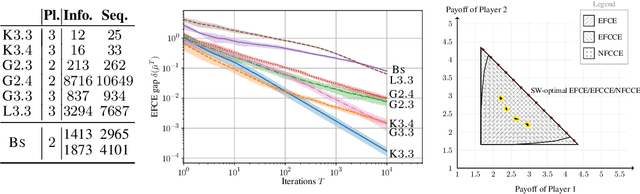
The existence of simple, uncoupled no-regret dynamics that converge to correlated equilibria in normal-form games is a celebrated result in the theory of multi-agent systems. Specifically, it has been known for more than 20 years that when all players seek to minimize their internal regret in a repeated normal-form game, the empirical frequency of play converges to a normal-form correlated equilibrium. Extensive-form (that is, tree-form) games generalize normal-form games by modeling both sequential and simultaneous moves, as well as private information. Because of the sequential nature and presence of partial information in the game, extensive-form correlation possesses significantly different properties than the normal-form counterpart, many of which are still open research directions. Extensive-form correlated equilibrium (EFCE) has been proposed as the natural extensive-form counterpart to normal-form correlated equilibrium, though it was currently unknown whether EFCE emerges as the result of uncoupled agent dynamics. In this article, we give the first uncoupled no-regret dynamics that converge with high probability to the set of EFCEs in n-player general-sum extensive-form games with perfect recall. First, we introduce a notion of trigger regret in extensive-form games, which extends that of internal regret in normal-form games. When each player has low trigger regret, the empirical frequency of play is close to an EFCE. Then, we give an efficient no-regret algorithm which guarantees with high probability that trigger regrets grow sublinearly in the number of iterations.
Multi-Agent Coordination in Adversarial Environments through Signal Mediated Strategies
Feb 09, 2021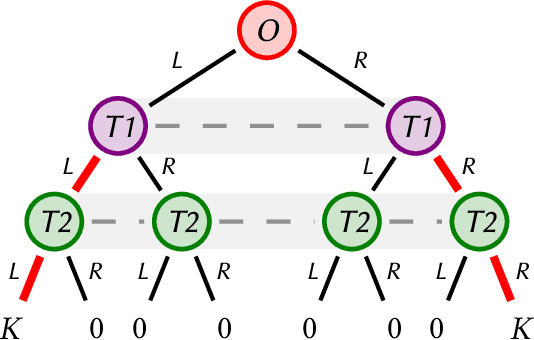
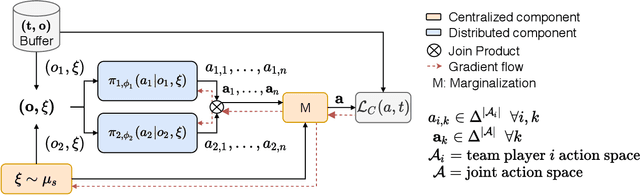
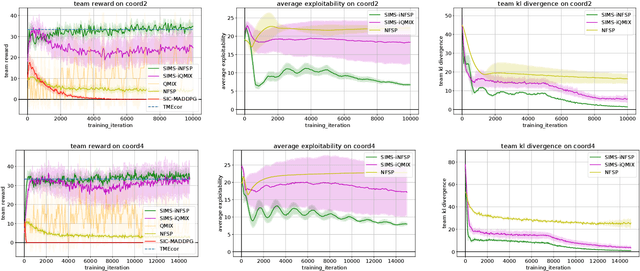

Many real-world scenarios involve teams of agents that have to coordinate their actions to reach a shared goal. We focus on the setting in which a team of agents faces an opponent in a zero-sum, imperfect-information game. Team members can coordinate their strategies before the beginning of the game, but are unable to communicate during the playing phase of the game. This is the case, for example, in Bridge, collusion in poker, and collusion in bidding. In this setting, model-free RL methods are oftentimes unable to capture coordination because agents' policies are executed in a decentralized fashion. Our first contribution is a game-theoretic centralized training regimen to effectively perform trajectory sampling so as to foster team coordination. When team members can observe each other actions, we show that this approach provably yields equilibrium strategies. Then, we introduce a signaling-based framework to represent team coordinated strategies given a buffer of past experiences. Each team member's policy is parametrized as a neural network whose output is conditioned on a suitable exogenous signal, drawn from a learned probability distribution. By combining these two elements, we empirically show convergence to coordinated equilibria in cases where previous state-of-the-art multi-agent RL algorithms did not.
Faster Algorithms for Optimal Ex-Ante Coordinated Collusive Strategies in Extensive-Form Zero-Sum Games
Sep 21, 2020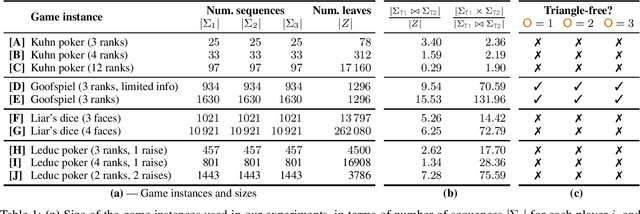
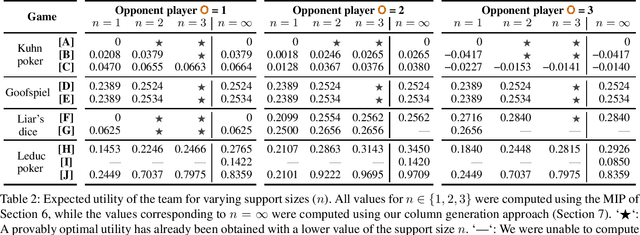
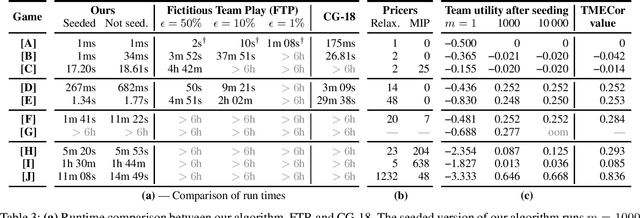
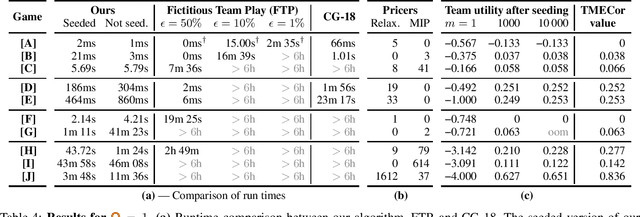
We focus on the problem of finding an optimal strategy for a team of two players that faces an opponent in an imperfect-information zero-sum extensive-form game. Team members are not allowed to communicate during play but can coordinate before the game. In that setting, it is known that the best the team can do is sample a profile of potentially randomized strategies (one per player) from a joint (a.k.a. correlated) probability distribution at the beginning of the game. In this paper, we first provide new modeling results about computing such an optimal distribution by drawing a connection to a different literature on extensive-form correlation. Second, we provide an algorithm that computes such an optimal distribution by only using profiles where only one of the team members gets to randomize in each profile. We can also cap the number of such profiles we allow in the solution. This begets an anytime algorithm by increasing the cap. We find that often a handful of well-chosen such profiles suffices to reach optimal utility for the team. This enables team members to reach coordination through a relatively simple and understandable plan. Finally, inspired by this observation and leveraging theoretical concepts that we introduce, we develop an efficient column-generation algorithm for finding an optimal distribution for the team. We evaluate it on a suite of common benchmark games. It is three orders of magnitude faster than the prior state of the art on games that the latter can solve and it can also solve several games that were previously unsolvable.
No-regret learning dynamics for extensive-form correlated and coarse correlated equilibria
Apr 09, 2020
Recently, there has been growing interest around less-restrictive solution concepts than Nash equilibrium in extensive-form games, with significant effort towards the computation of extensive-form correlated equilibrium (EFCE) and extensive-form coarse correlated equilibrium (EFCCE). In this paper, we show how to leverage the popular counterfactual regret minimization (CFR) paradigm to induce simple no-regret dynamics that converge to the set of EFCEs and EFCCEs in an n-player general-sum extensive-form games. For EFCE, we define a notion of internal regret suitable for extensive-form games and exhibit an efficient no-internal-regret algorithm. These results complement those for normal-form games introduced in the seminal paper by Hart and Mas-Colell. For EFCCE, we show that no modification of CFR is needed, and that in fact the empirical frequency of play generated when all the players use the original CFR algorithm converges to the set of EFCCEs.
Signaling in Bayesian Network Congestion Games: the Subtle Power of Symmetry
Feb 12, 2020
Network congestion games are a well-understood model of multi-agent strategic interactions. Despite their ubiquitous applications, it is not clear whether it is possible to design information structures to ameliorate the overall experience of the network users. We focus on Bayesian games with atomic players, where network vagaries are modeled via a (random) state of nature which determines the costs incurred by the players. A third-party entity---the sender---can observe the realized state of the network and exploit this additional information to send a signal to each player. A natural question is the following: is it possible for an informed sender to reduce the overall social cost via the strategic provision of information to players who update their beliefs rationally? The paper focuses on the problem of computing optimal ex ante persuasive signaling schemes, showing that symmetry is a crucial property for its solution. Indeed, we show that an optimal ex ante persuasive signaling scheme can be computed in polynomial time when players are symmetric and have affine cost functions. Moreover, the problem becomes NP-hard when players are asymmetric, even in non-Bayesian settings.