 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Symbolic Optimization: Reinforcement Learning for Symbolic Mathematics
May 16, 2025Deep Symbolic Optimization (DSO) is a novel computational framework that enables symbolic optimization for scientific discovery, particularly in applications involving the search for intricate symbolic structures. One notable example is equation discovery, which aims to automatically derive mathematical models expressed in symbolic form. In DSO, the discovery process is formulated as a sequential decision-making task. A generative neural network learns a probabilistic model over a vast space of candidate symbolic expressions, while reinforcement learning strategies guide the search toward the most promising regions. This approach integrates gradient-based optimization with evolutionary and local search techniques, and it incorporates in-situ constraints, domain-specific priors, and advanced policy optimization methods. The result is a robust framework capable of efficiently exploring extensive search spaces to identify interpretable and physically meaningful models. Extensive evaluations on benchmark problems have demonstrated that DSO achieves state-of-the-art performance in both accuracy and interpretability. In this chapter, we provide a comprehensive overview of the DSO framework and illustrate its transformative potential for automating symbolic optimization in scientific discovery.
Hierarchical Sparse Bayesian Multitask Model with Scalable Inference for Microbiome Analysis
Feb 04, 2025



This paper proposes a hierarchical Bayesian multitask learning model that is applicable to the general multi-task binary classification learning problem where the model assumes a shared sparsity structure across different tasks. We derive a computationally efficient inference algorithm based on variational inference to approximate the posterior distribution. We demonstrate the potential of the new approach on various synthetic datasets and for predicting human health status based on microbiome profile. Our analysis incorporates data pooled from multiple microbiome studies, along with a comprehensive comparison with other benchmark methods. Results in synthetic datasets show that the proposed approach has superior support recovery property when the underlying regression coefficients share a common sparsity structure across different tasks. Our experiments on microbiome classification demonstrate the utility of the method in extracting informative taxa while providing well-calibrated predictions with uncertainty quantification and achieving competitive performance in terms of prediction metrics. Notably, despite the heterogeneity of the pooled datasets (e.g., different experimental objectives, laboratory setups, sequencing equipment, patient demographics), our method delivers robust results.
Multi-task Sparse Structure Learning
Sep 02, 2014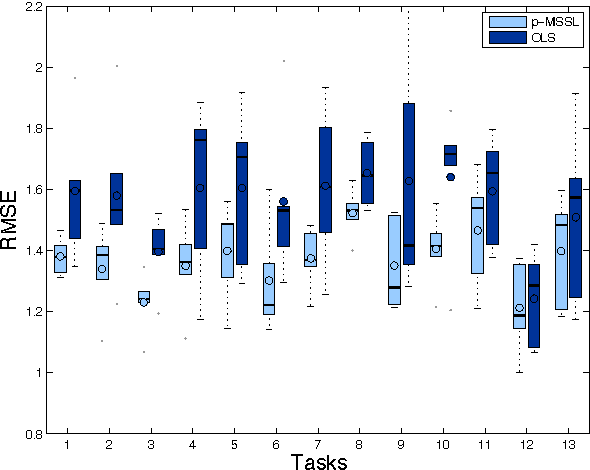

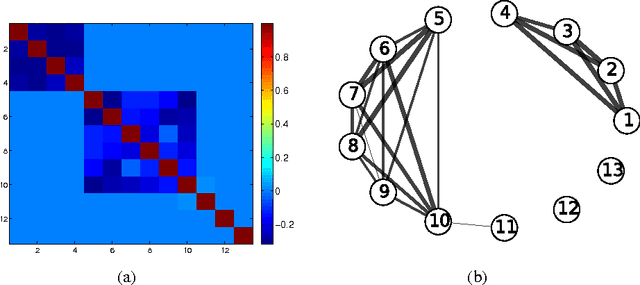

Multi-task learning (MTL) aims to improve generalization performance by learning multiple related tasks simultaneously. While sometimes the underlying task relationship structure is known, often the structure needs to be estimated from data at hand. In this paper, we present a novel family of models for MTL, applicable to regression and classification problems, capable of learning the structure of task relationships. In particular, we consider a joint estimation problem of the task relationship structure and the individual task parameters, which is solved using alternating minimization. The task relationship structure learning component builds on recent advances in structure learning of Gaussian graphical models based on sparse estimators of the precision (inverse covariance) matrix. We illustrate the effectiveness of the proposed model on a variety of synthetic and benchmark datasets for regression and classification. We also consider the problem of combining climate model outputs for better projections of future climate, with focus on temperature in South America, and show that the proposed model outperforms several existing methods for the problem.