 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucinations in Large Multilingual Translation Models
Mar 28, 2023Large-scale multilingual machine translation systems have demonstrated remarkable ability to translate directly between numerous languages, making them increasingly appealing for real-world applications. However, when deployed in the wild, these models may generate hallucinated translations which have the potential to severely undermine user trust and raise safety concerns. Existing research on hallucinations has primarily focused on small bilingual models trained on high-resource languages, leaving a gap in our understanding of hallucinations in massively multilingual models across diverse translation scenarios. In this work, we fill this gap by conducting a comprehensive analysis on both the M2M family of conventional neural machine translation models and ChatGPT, a general-purpose large language model~(LLM) that can be prompted for translation. Our investigation covers a broad spectrum of conditions, spanning over 100 translation directions across various resource levels and going beyond English-centric language pairs. We provide key insights regarding the prevalence, properties, and mitigation of hallucinations, paving the way towards more responsible and reliable machine translation systems.
Discrete Latent Structure in Neural Networks
Jan 18, 2023



Many types of data from fields including natural language processing, computer vision, and bioinformatics, are well represented by discrete, compositional structures such as trees, sequences, or matchings. Latent structure models are a powerful tool for learning to extract such representations, offering a way to incorporate structural bias, discover insight about the data, and interpret decisions. However, effective training is challenging, as neural networks are typically designed for continuous computation. This text explores three broad strategies for learning with discrete latent structure: continuous relaxation, surrogate gradients, and probabilistic estimation. Our presentation relies on consistent notations for a wide range of models. As such, we reveal many new connections between latent structure learning strategies, showing how most consist of the same small set of fundamental building blocks, but use them differently, leading to substantially different applicability and properties.
Asking Clarification Questions for Code Generation in General-Purpose Programming Language
Dec 19, 2022Code generation from text requires understanding the user's intent from a natural language description (NLD) and generating an executable program code snippet that satisfies this intent. While recent pretrained language models (PLMs) demonstrate remarkable performance for this task, these models fail when the given NLD is ambiguous due to the lack of enough specifications for generating a high-quality code snippet. In this work, we introduce a novel and more realistic setup for this task. We hypothesize that ambiguities in the specifications of an NLD are resolved by asking clarification questions (CQs). Therefore, we collect and introduce a new dataset named CodeClarQA containing NLD-Code pairs with created CQAs. We evaluate the performance of PLMs for code generation on our dataset. The empirical results support our hypothesis that clarifications result in more precise generated code, as shown by an improvement of 17.52 in BLEU, 12.72 in CodeBLEU, and 7.7\% in the exact match. Alongside this, our task and dataset introduce new challenges to the community, including when and what CQs should be asked.
Optimal Transport for Unsupervised Hallucination Detection in Neural Machine Translation
Dec 19, 2022Neural machine translation (NMT) has become the de-facto standard in real-world machine translation applications. However, NMT models can unpredictably produce severely pathological translations, known as hallucinations, that seriously undermine user trust. It becomes thus crucial to implement effective preventive strategies to guarantee their proper functioning. In this paper, we address the problem of hallucination detection in NMT by following a simple intuition: as hallucinations are detached from the source content, they exhibit encoder-decoder attention patterns that are statistically different from those of good quality translations. We frame this problem with an optimal transport formulation and propose a fully unsupervised, plug-in detector that can be used with any attention-based NMT model. Experimental results show that our detector not only outperforms all previous model-based detectors, but is also competitive with detectors that employ large models trained on millions of samples.
Improving abstractive summarization with energy-based re-ranking
Nov 07, 2022



Current abstractive summarization systems present important weaknesses which prevent their deployment in real-world applications, such as the omission of relevant information and the generation of factual inconsistencies (also known as hallucinations). At the same time, automatic evaluation metrics such as CTC scores have been recently proposed that exhibit a higher correlation with human judgments than traditional lexical-overlap metrics such as ROUGE. In this work, we intend to close the loop by leveraging the recent advances in summarization metrics to create quality-aware abstractive summarizers. Namely, we propose an energy-based model that learns to re-rank summaries according to one or a combination of these metrics. We experiment using several metrics to train our energy-based re-ranker and show that it consistently improves the scores achieved by the predicted summaries. Nonetheless, human evaluation results show that the re-ranking approach should be used with care for highly abstractive summaries, as the available metrics are not yet sufficiently reliable for this purpose.
CometKiwi: IST-Unbabel 2022 Submission for the Quality Estimation Shared Task
Sep 13, 2022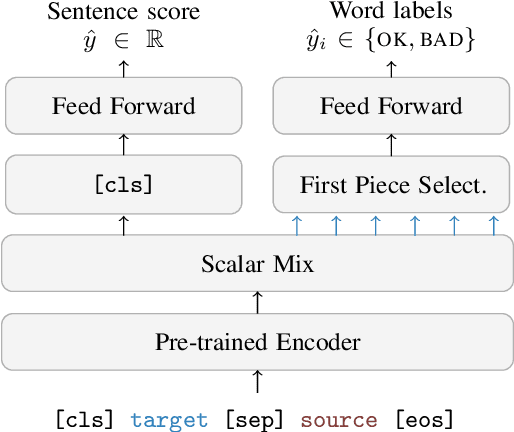
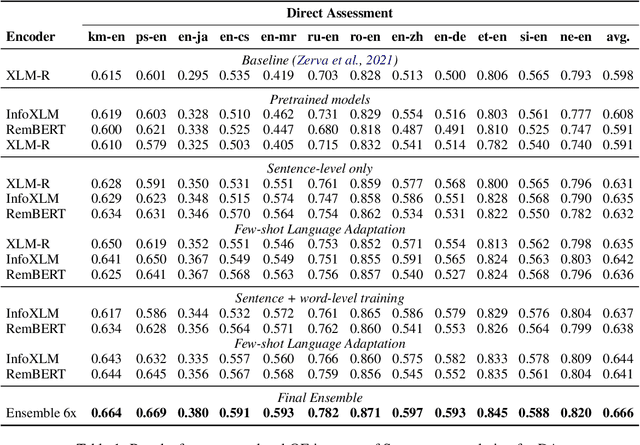
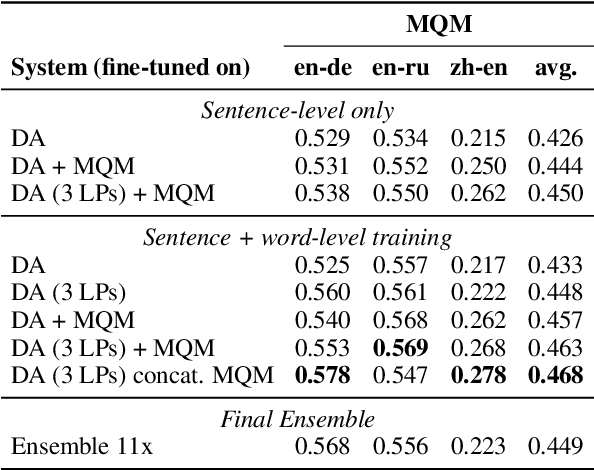
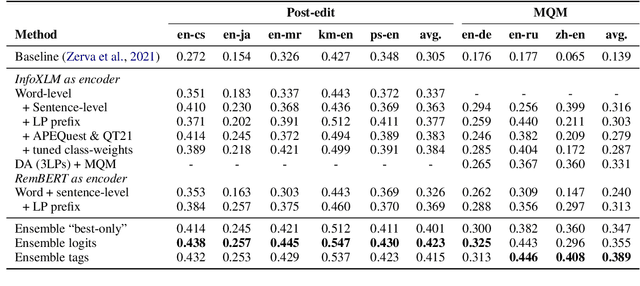
We present the joint contribution of IST and Unbabel to the WMT 2022 Shared Task on Quality Estimation (QE). Our team participated on all three subtasks: (i) Sentence and Word-level Quality Prediction; (ii) Explainable QE; and (iii) Critical Error Detection. For all tasks we build on top of the COMET framework, connecting it with the predictor-estimator architecture of OpenKiwi, and equipping it with a word-level sequence tagger and an explanation extractor. Our results suggest that incorporating references during pretraining improves performance across several language pairs on downstream tasks, and that jointly training with sentence and word-level objectives yields a further boost. Furthermore, combining attention and gradient information proved to be the top strategy for extracting good explanations of sentence-level QE models. Overall, our submissions achieved the best results for all three tasks for almost all language pairs by a considerable margin.
Looking for a Needle in a Haystack: A Comprehensive Study of Hallucinations in Neural Machine Translation
Aug 10, 2022

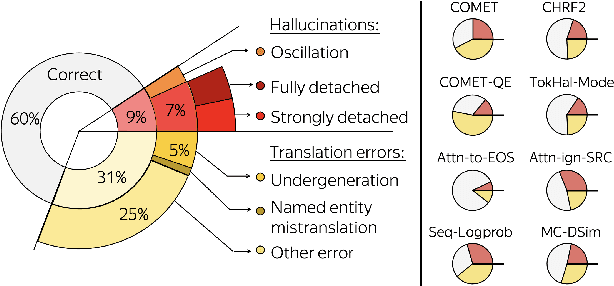
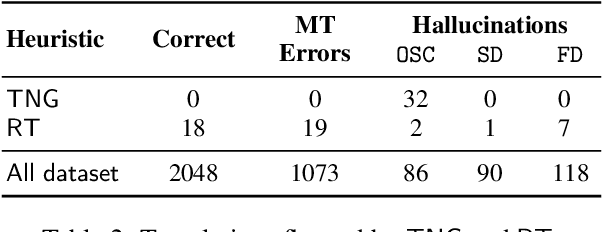
Although the problem of hallucinations in neural machine translation (NMT) has received some attention, research on this highly pathological phenomenon lacks solid ground. Previous work has been limited in several ways: it often resorts to artificial settings where the problem is amplified, it disregards some (common) types of hallucinations, and it does not validate adequacy of detection heuristics. In this paper, we set foundations for the study of NMT hallucinations. First, we work in a natural setting, i.e., in-domain data without artificial noise neither in training nor in inference. Next, we annotate a dataset of over 3.4k sentences indicating different kinds of critical errors and hallucinations. Then, we turn to detection methods and both revisit methods used previously and propose using glass-box uncertainty-based detectors. Overall, we show that for preventive settings, (i) previously used methods are largely inadequate, (ii) sequence log-probability works best and performs on par with reference-based methods. Finally, we propose DeHallucinator, a simple method for alleviating hallucinations at test time that significantly reduces the hallucinatory rate. To ease future research, we release our annotated dataset for WMT18 German-English data, along with the model, training data, and code.
Chunk-based Nearest Neighbor Machine Translation
May 24, 2022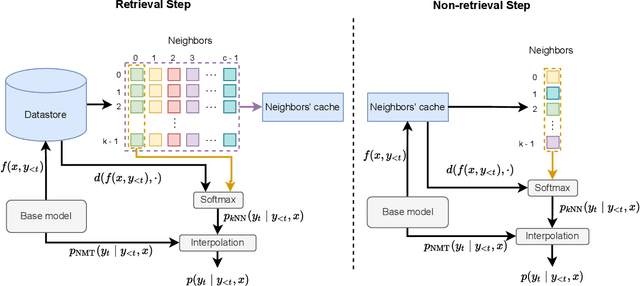
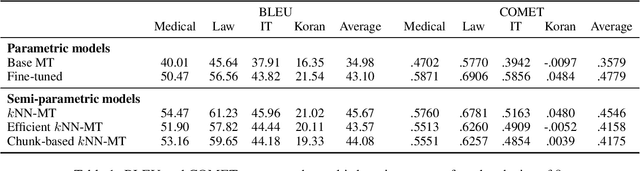
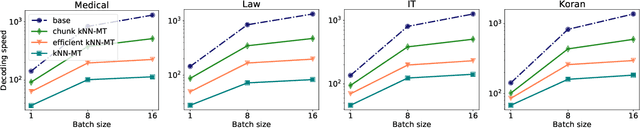
Semi-parametric models, which augment generation with retrieval, have led to impressive results in language modeling and machine translation, due to their ability to leverage information retrieved from a datastore of examples. One of the most prominent approaches, $k$NN-MT, has an outstanding performance on domain adaptation by retrieving tokens from a domain-specific datastore \citep{khandelwal2020nearest}. However, $k$NN-MT requires retrieval for every single generated token, leading to a very low decoding speed (around 8 times slower than a parametric model). In this paper, we introduce a \textit{chunk-based} $k$NN-MT model which retrieves chunks of tokens from the datastore, instead of a single token. We propose several strategies for incorporating the retrieved chunks into the generation process, and for selecting the steps at which the model needs to search for neighbors in the datastore. Experiments on machine translation in two settings, static domain adaptation and ``on-the-fly'' adaptation, show that the chunk-based $k$NN-MT model leads to a significant speed-up (up to 4 times) with only a small drop in translation quality.
Quality-Aware Decoding for Neural Machine Translation
May 02, 2022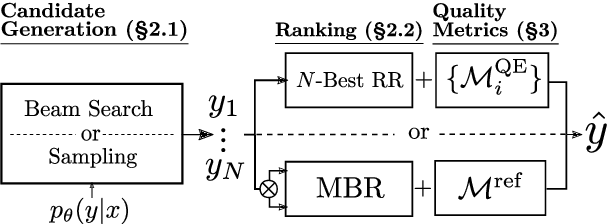
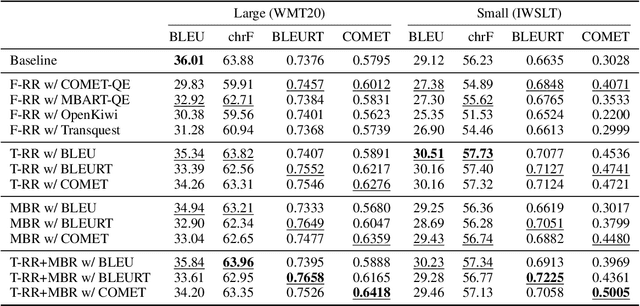
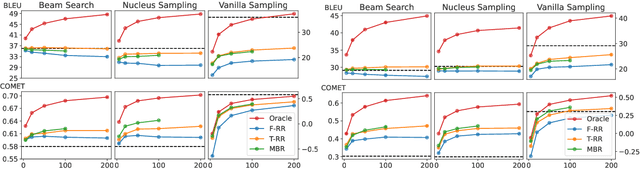
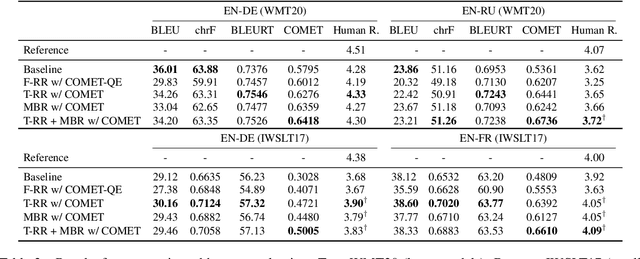
Despite the progress in machine translation quality estimation and evaluation in the last years, decoding in neural machine translation (NMT) is mostly oblivious to this and centers around finding the most probable translation according to the model (MAP decoding), approximated with beam search. In this paper, we bring together these two lines of research and propose quality-aware decoding for NMT, by leveraging recent breakthroughs in reference-free and reference-based MT evaluation through various inference methods like $N$-best reranking and minimum Bayes risk decoding. We perform an extensive comparison of various possible candidate generation and ranking methods across four datasets and two model classes and find that quality-aware decoding consistently outperforms MAP-based decoding according both to state-of-the-art automatic metrics (COMET and BLEURT) and to human assessments. Our code is available at https://github.com/deep-spin/qaware-decode.
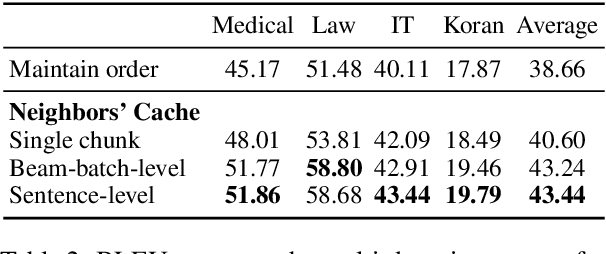
Efficient Machine Translation Domain Adaptation
Apr 26, 2022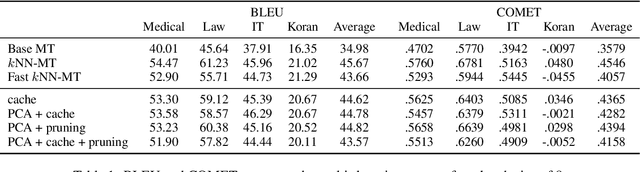
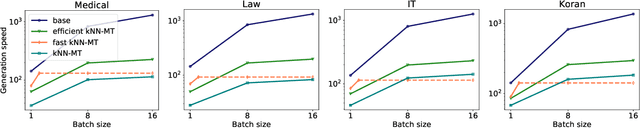
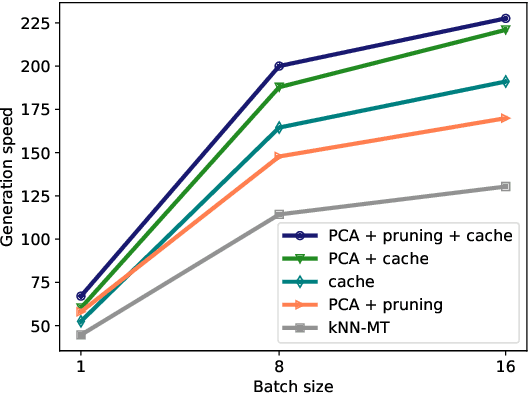
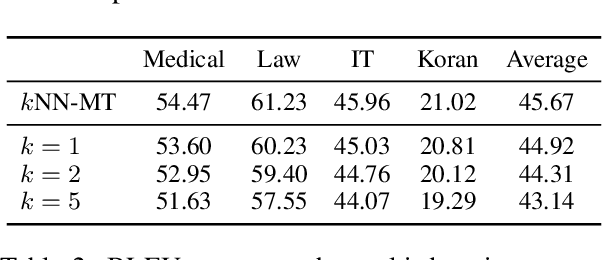
Machine translation models struggle when translating out-of-domain text, which makes domain adaptation a topic of critical importance. However, most domain adaptation methods focus on fine-tuning or training the entire or part of the model on every new domain, which can be costly. On the other hand, semi-parametric models have been shown to successfully perform domain adaptation by retrieving examples from an in-domain datastore (Khandelwal et al., 2021). A drawback of these retrieval-augmented models, however, is that they tend to be substantially slower. In this paper, we explore several approaches to speed up nearest neighbor machine translation. We adapt the methods recently proposed by He et al. (2021) for language modeling, and introduce a simple but effective caching strategy that avoids performing retrieval when similar contexts have been seen before. Translation quality and runtimes for several domains show the effectiveness of the proposed solutions.