 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical inference using SGD
Nov 19, 2017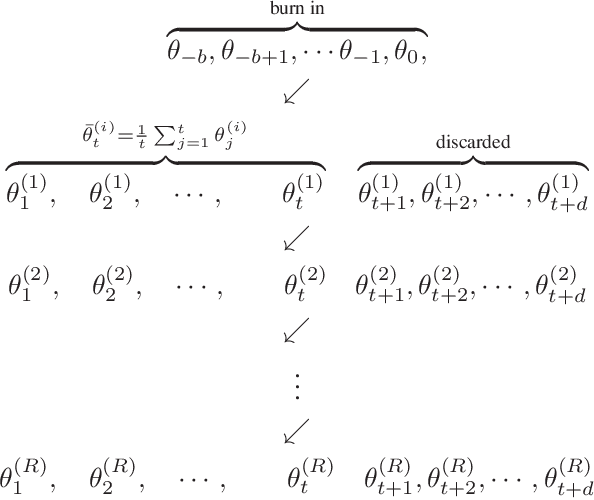

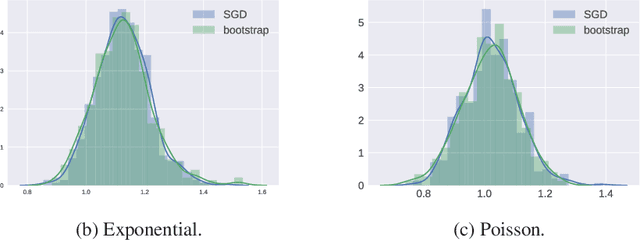

We present a novel method for frequentist statistical inference in $M$-estimation problems, based on stochastic gradient descent (SGD) with a fixed step size: we demonstrate that the average of such SGD sequences can be used for statistical inference, after proper scaling. An intuitive analysis using the Ornstein-Uhlenbeck process suggests that such averages are asymptotically normal. From a practical perspective, our SGD-based inference procedure is a first order method, and is well-suited for large scale problems. To show its merits, we apply it to both synthetic and real datasets, and demonstrate that its accuracy is comparable to classical statistical methods, while requiring potentially far less computation.
Algorithms for Learning Sparse Additive Models with Interactions in High Dimensions
May 08, 2017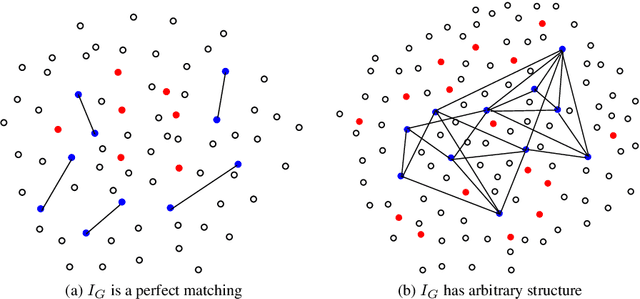
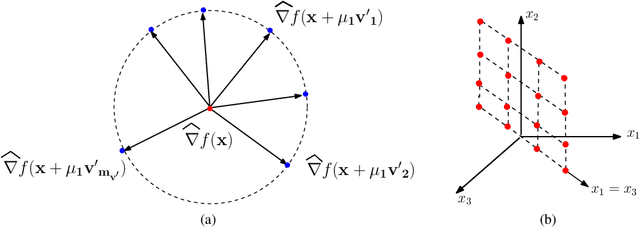
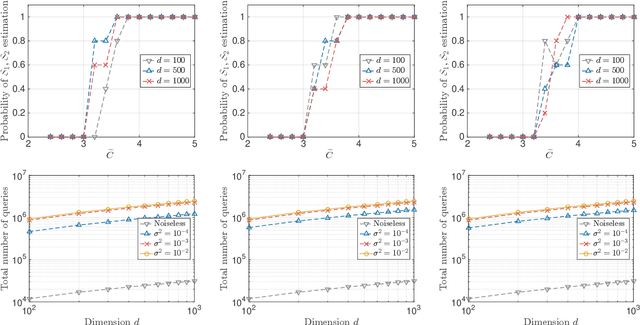
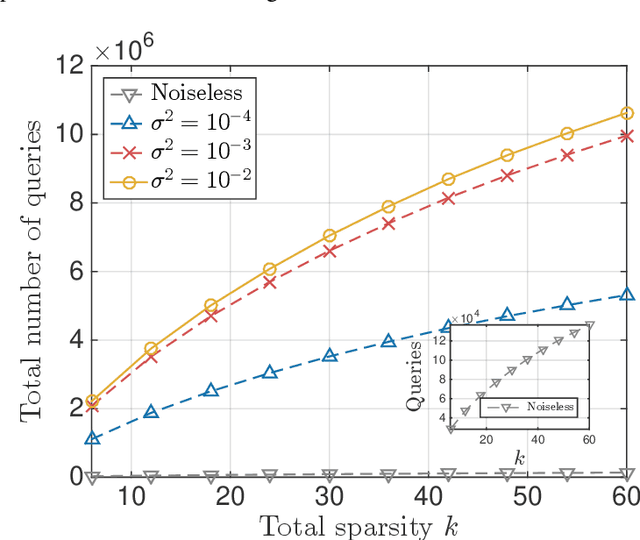
A function $f: \mathbb{R}^d \rightarrow \mathbb{R}$ is a Sparse Additive Model (SPAM), if it is of the form $f(\mathbf{x}) = \sum_{l \in \mathcal{S}}\phi_{l}(x_l)$ where $\mathcal{S} \subset [d]$, $|\mathcal{S}| \ll d$. Assuming $\phi$'s, $\mathcal{S}$ to be unknown, there exists extensive work for estimating $f$ from its samples. In this work, we consider a generalized version of SPAMs, that also allows for the presence of a sparse number of second order interaction terms. For some $\mathcal{S}_1 \subset [d], \mathcal{S}_2 \subset {[d] \choose 2}$, with $|\mathcal{S}_1| \ll d, |\mathcal{S}_2| \ll d^2$, the function $f$ is now assumed to be of the form: $\sum_{p \in \mathcal{S}_1}\phi_{p} (x_p) + \sum_{(l,l^{\prime}) \in \mathcal{S}_2}\phi_{(l,l^{\prime})} (x_l,x_{l^{\prime}})$. Assuming we have the freedom to query $f$ anywhere in its domain, we derive efficient algorithms that provably recover $\mathcal{S}_1,\mathcal{S}_2$ with finite sample bounds. Our analysis covers the noiseless setting where exact samples of $f$ are obtained, and also extends to the noisy setting where the queries are corrupted with noise. For the noisy setting in particular, we consider two noise models namely: i.i.d Gaussian noise and arbitrary but bounded noise. Our main methods for identification of $\mathcal{S}_2$ essentially rely on estimation of sparse Hessian matrices, for which we provide two novel compressed sensing based schemes. Once $\mathcal{S}_1, \mathcal{S}_2$ are known, we show how the individual components $\phi_p$, $\phi_{(l,l^{\prime})}$ can be estimated via additional queries of $f$, with uniform error bounds. Lastly, we provide simulation results on synthetic data that validate our theoretical findings.
A single-phase, proximal path-following framework
Dec 25, 2016
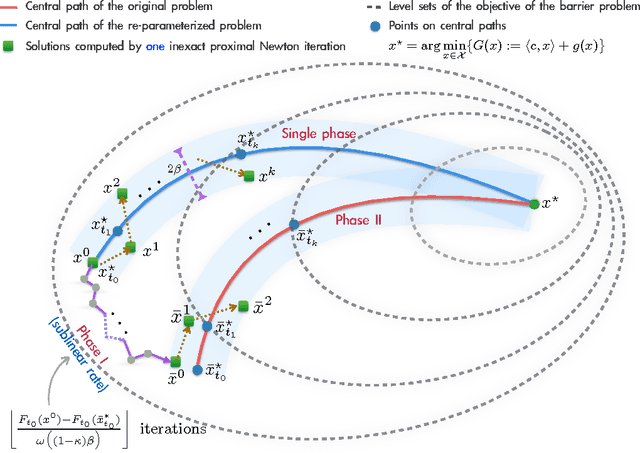
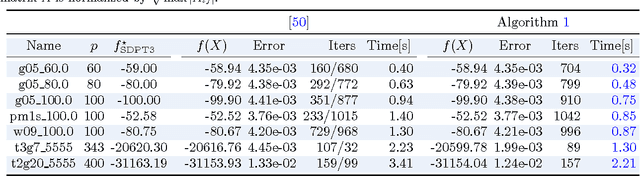
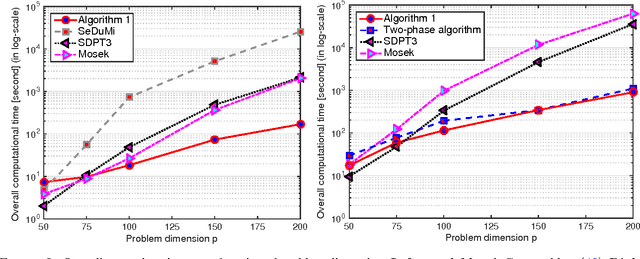
We propose a new proximal, path-following framework for a class of constrained convex problems. We consider settings where the nonlinear---and possibly non-smooth---objective part is endowed with a proximity operator, and the constraint set is equipped with a self-concordant barrier. Our approach relies on the following two main ideas. First, we re-parameterize the optimality condition as an auxiliary problem, such that a good initial point is available; by doing so, a family of alternative paths towards the optimum is generated. Second, we combine the proximal operator with path-following ideas to design a single-phase, proximal, path-following algorithm. Our method has several advantages. First, it allows handling non-smooth objectives via proximal operators; this avoids lifting the problem dimension in order to accommodate non-smooth components in optimization. Second, it consists of only a \emph{single phase}: While the overall convergence rate of classical path-following schemes for self-concordant objectives does not suffer from the initialization phase, proximal path-following schemes undergo slow convergence, in order to obtain a good starting point \cite{TranDinh2013e}. In this work, we show how to overcome this limitation in the proximal setting and prove that our scheme has the same $\mathcal{O}(\sqrt{\nu}\log(1/\varepsilon))$ worst-case iteration-complexity with standard approaches \cite{Nesterov2004,Nesterov1994} without requiring an initial phase, where $\nu$ is the barrier parameter and $\varepsilon$ is a desired accuracy. Finally, our framework allows errors in the calculation of proximal-Newton directions, without sacrificing the worst-case iteration complexity. We demonstrate the merits of our algorithm via three numerical examples, where proximal operators play a key role.
Finding Low-Rank Solutions via Non-Convex Matrix Factorization, Efficiently and Provably
Oct 29, 2016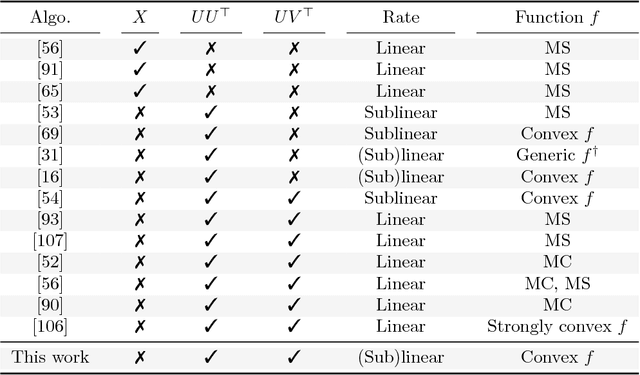
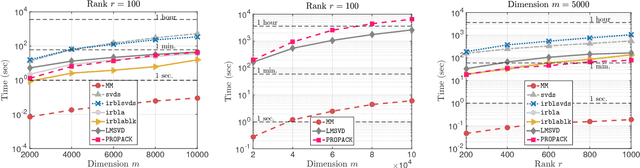

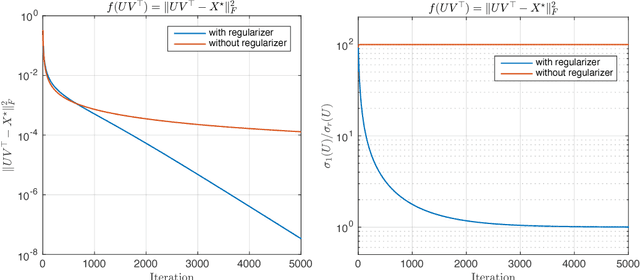
A rank-$r$ matrix $X \in \mathbb{R}^{m \times n}$ can be written as a product $U V^\top$, where $U \in \mathbb{R}^{m \times r}$ and $V \in \mathbb{R}^{n \times r}$. One could exploit this observation in optimization: e.g., consider the minimization of a convex function $f(X)$ over rank-$r$ matrices, where the set of rank-$r$ matrices is modeled via the factorization $UV^\top$. Though such parameterization reduces the number of variables, and is more computationally efficient (of particular interest is the case $r \ll \min\{m, n\}$), it comes at a cost: $f(UV^\top)$ becomes a non-convex function w.r.t. $U$ and $V$. We study such parameterization for optimization of generic convex objectives $f$, and focus on first-order, gradient descent algorithmic solutions. We propose the Bi-Factored Gradient Descent (BFGD) algorithm, an efficient first-order method that operates on the $U, V$ factors. We show that when $f$ is (restricted) smooth, BFGD has local sublinear convergence, and linear convergence when $f$ is both (restricted) smooth and (restricted) strongly convex. For several key applications, we provide simple and efficient initialization schemes that provide approximate solutions good enough for the above convergence results to hold.
Provable Burer-Monteiro factorization for a class of norm-constrained matrix problems
Oct 01, 2016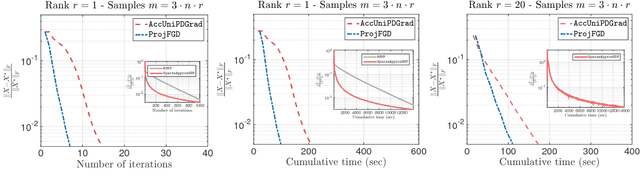
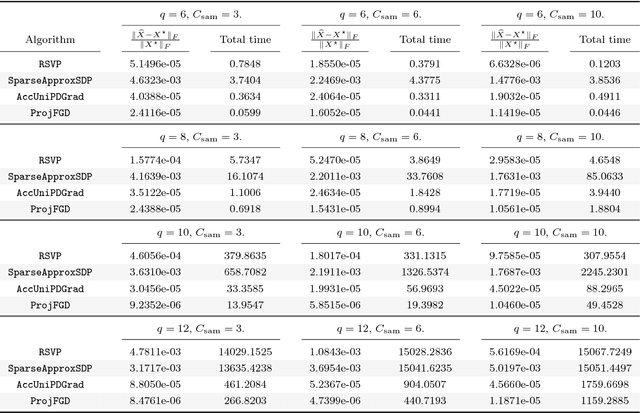


We study the projected gradient descent method on low-rank matrix problems with a strongly convex objective. We use the Burer-Monteiro factorization approach to implicitly enforce low-rankness; such factorization introduces non-convexity in the objective. We focus on constraint sets that include both positive semi-definite (PSD) constraints and specific matrix norm-constraints. Such criteria appear in quantum state tomography and phase retrieval applications. We show that non-convex projected gradient descent favors local linear convergence in the factored space. We build our theory on a novel descent lemma, that non-trivially extends recent results on the unconstrained problem. The resulting algorithm is Projected Factored Gradient Descent, abbreviated as ProjFGD, and shows superior performance compared to state of the art on quantum state tomography and sparse phase retrieval applications.
Non-square matrix sensing without spurious local minima via the Burer-Monteiro approach
Sep 27, 2016We consider the non-square matrix sensing problem, under restricted isometry property (RIP) assumptions. We focus on the non-convex formulation, where any rank-$r$ matrix $X \in \mathbb{R}^{m \times n}$ is represented as $UV^\top$, where $U \in \mathbb{R}^{m \times r}$ and $V \in \mathbb{R}^{n \times r}$. In this paper, we complement recent findings on the non-convex geometry of the analogous PSD setting [5], and show that matrix factorization does not introduce any spurious local minima, under RIP.
A simple and provable algorithm for sparse diagonal CCA
May 29, 2016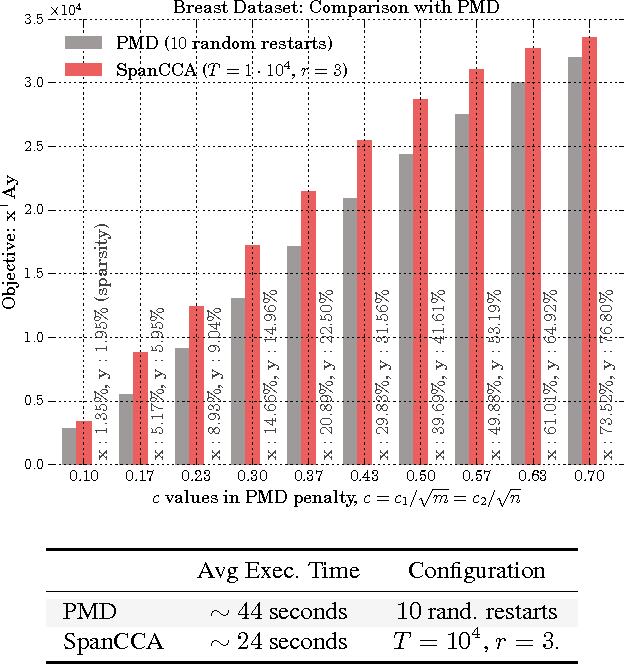

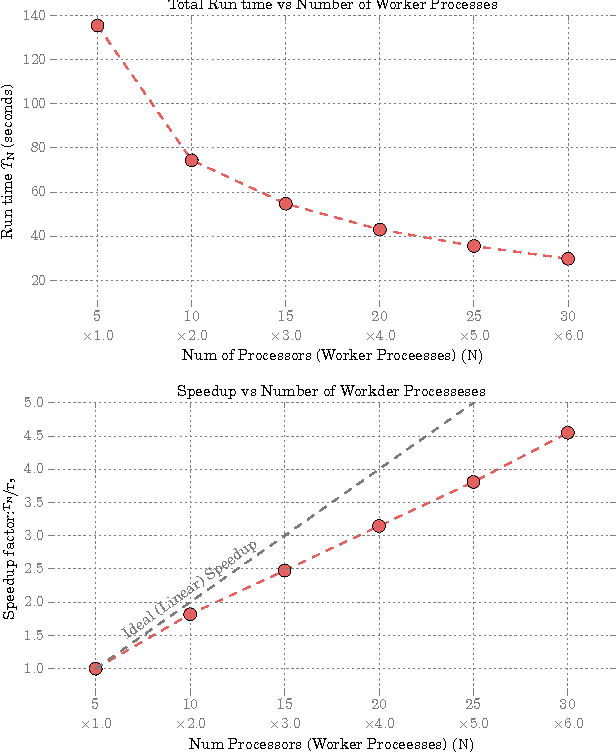
Given two sets of variables, derived from a common set of samples, sparse Canonical Correlation Analysis (CCA) seeks linear combinations of a small number of variables in each set, such that the induced canonical variables are maximally correlated. Sparse CCA is NP-hard. We propose a novel combinatorial algorithm for sparse diagonal CCA, i.e., sparse CCA under the additional assumption that variables within each set are standardized and uncorrelated. Our algorithm operates on a low rank approximation of the input data and its computational complexity scales linearly with the number of input variables. It is simple to implement, and parallelizable. In contrast to most existing approaches, our algorithm administers precise control on the sparsity of the extracted canonical vectors, and comes with theoretical data-dependent global approximation guarantees, that hinge on the spectrum of the input data. Finally, it can be straightforwardly adapted to other constrained variants of CCA enforcing structure beyond sparsity. We empirically evaluate the proposed scheme and apply it on a real neuroimaging dataset to investigate associations between brain activity and behavior measurements.
Learning Sparse Additive Models with Interactions in High Dimensions
Apr 18, 2016A function $f: \mathbb{R}^d \rightarrow \mathbb{R}$ is referred to as a Sparse Additive Model (SPAM), if it is of the form $f(\mathbf{x}) = \sum_{l \in \mathcal{S}}\phi_{l}(x_l)$, where $\mathcal{S} \subset [d]$, $|\mathcal{S}| \ll d$. Assuming $\phi_l$'s and $\mathcal{S}$ to be unknown, the problem of estimating $f$ from its samples has been studied extensively. In this work, we consider a generalized SPAM, allowing for second order interaction terms. For some $\mathcal{S}_1 \subset [d], \mathcal{S}_2 \subset {[d] \choose 2}$, the function $f$ is assumed to be of the form: $$f(\mathbf{x}) = \sum_{p \in \mathcal{S}_1}\phi_{p} (x_p) + \sum_{(l,l^{\prime}) \in \mathcal{S}_2}\phi_{(l,l^{\prime})} (x_{l},x_{l^{\prime}}).$$ Assuming $\phi_{p},\phi_{(l,l^{\prime})}$, $\mathcal{S}_1$ and, $\mathcal{S}_2$ to be unknown, we provide a randomized algorithm that queries $f$ and exactly recovers $\mathcal{S}_1,\mathcal{S}_2$. Consequently, this also enables us to estimate the underlying $\phi_p, \phi_{(l,l^{\prime})}$. We derive sample complexity bounds for our scheme and also extend our analysis to include the situation where the queries are corrupted with noise -- either stochastic, or arbitrary but bounded. Lastly, we provide simulation results on synthetic data, that validate our theoretical findings.
Dropping Convexity for Faster Semi-definite Optimization
Apr 16, 2016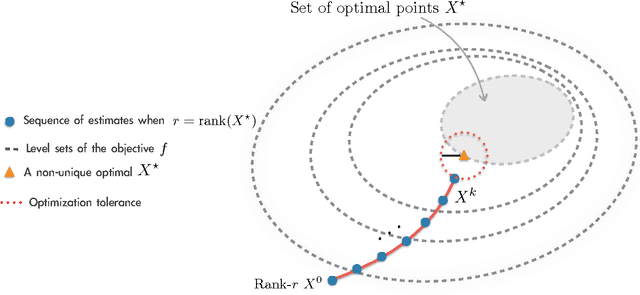

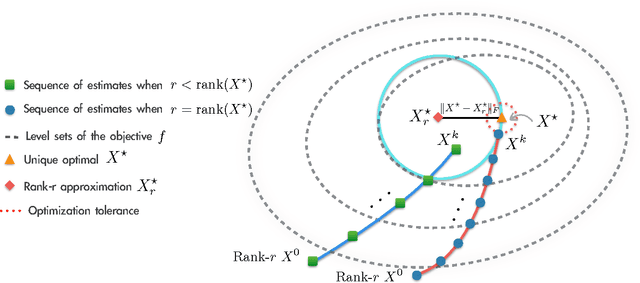
We study the minimization of a convex function $f(X)$ over the set of $n\times n$ positive semi-definite matrices, but when the problem is recast as $\min_U g(U) := f(UU^\top)$, with $U \in \mathbb{R}^{n \times r}$ and $r \leq n$. We study the performance of gradient descent on $g$---which we refer to as Factored Gradient Descent (FGD)---under standard assumptions on the original function $f$. We provide a rule for selecting the step size and, with this choice, show that the local convergence rate of FGD mirrors that of standard gradient descent on the original $f$: i.e., after $k$ steps, the error is $O(1/k)$ for smooth $f$, and exponentially small in $k$ when $f$ is (restricted) strongly convex. In addition, we provide a procedure to initialize FGD for (restricted) strongly convex objectives and when one only has access to $f$ via a first-order oracle; for several problem instances, such proper initialization leads to global convergence guarantees. FGD and similar procedures are widely used in practice for problems that can be posed as matrix factorization. To the best of our knowledge, this is the first paper to provide precise convergence rate guarantees for general convex functions under standard convex assumptions.
Convex block-sparse linear regression with expanders -- provably
Apr 03, 2016

Sparse matrices are favorable objects in machine learning and optimization. When such matrices are used, in place of dense ones, the overall complexity requirements in optimization can be significantly reduced in practice, both in terms of space and run-time. Prompted by this observation, we study a convex optimization scheme for block-sparse recovery from linear measurements. To obtain linear sketches, we use expander matrices, i.e., sparse matrices containing only few non-zeros per column. Hitherto, to the best of our knowledge, such algorithmic solutions have been only studied from a non-convex perspective. Our aim here is to theoretically characterize the performance of convex approaches under such setting. Our key novelty is the expression of the recovery error in terms of the model-based norm, while assuring that solution lives in the model. To achieve this, we show that sparse model-based matrices satisfy a group version of the null-space property. Our experimental findings on synthetic and real applications support our claims for faster recovery in the convex setting -- as opposed to using dense sensing matrices, while showing a competitive recovery performance.